
How To Optimize Your LLM APP with RAG API
This guide explores how to optimize your LLM app using the RAG API, enhancing retrieval, accuracy, and overall performance.



Imagine this: your LLM app, no matter how advanced, is only as good as the data it can access. Yet, most models are locked in a static knowledge bubble, unable to adapt to real-time information or domain-specific nuances. This limitation isn’t just a technical hurdle—it’s a missed opportunity to deliver precision, relevance, and speed in a world where user expectations are higher than ever.
Enter the RAG API, a game-changing solution that bridges the gap between static training data and dynamic, real-world queries. By seamlessly integrating retrieval mechanisms with generative AI, it empowers your app to fetch, process, and generate responses grounded in up-to-date, context-specific information. But here’s the catch: optimizing this integration isn’t plug-and-play. It requires a strategic approach to unlock its full potential.
So, how do you transform your LLM app into a responsive, data-driven powerhouse? Let’s explore.
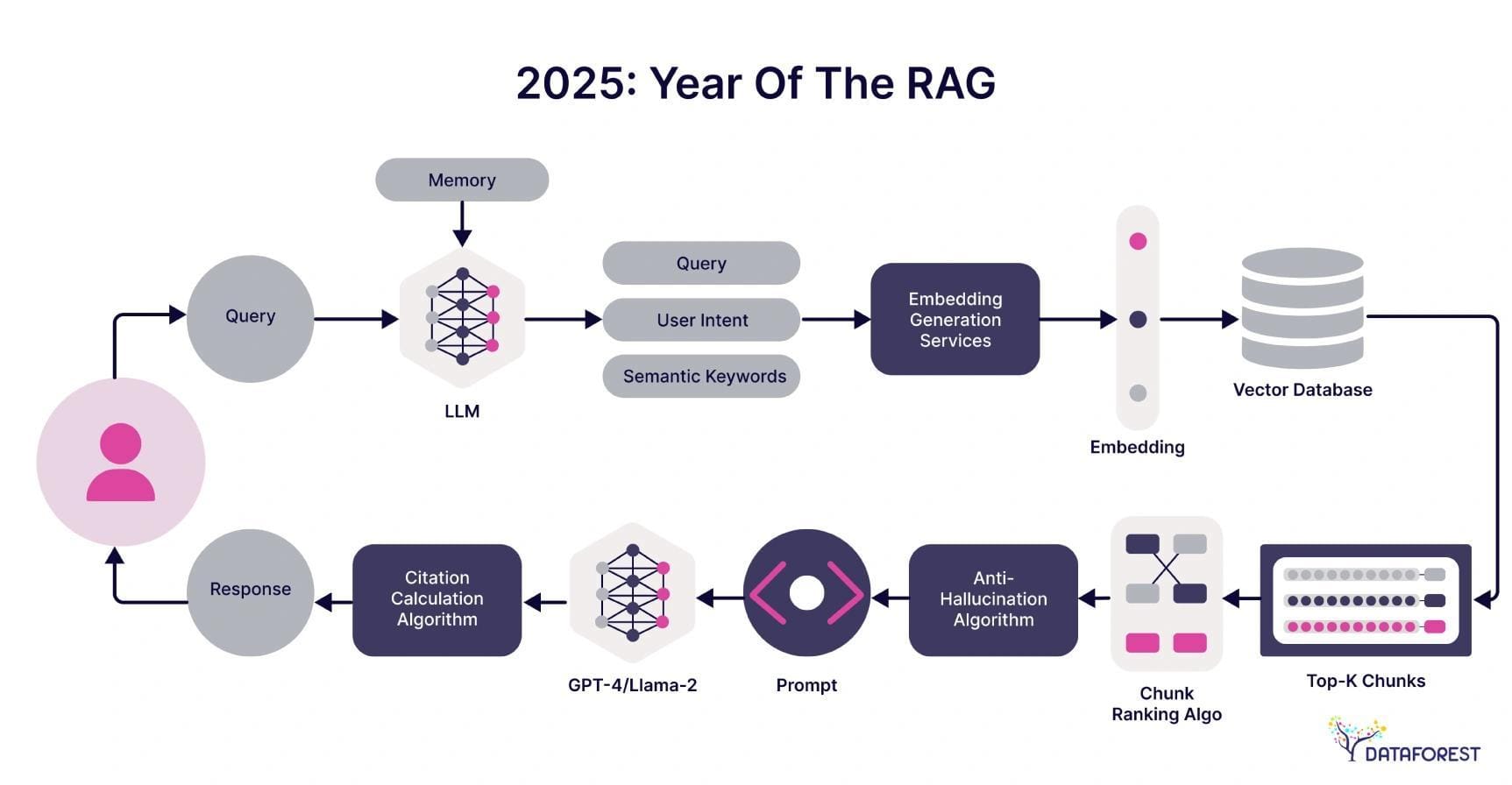
The Evolution of LLM Applications
The trajectory of LLM applications has shifted dramatically from static, one-size-fits-all models to dynamic systems capable of real-time adaptation. A key driver of this evolution is the integration of external knowledge retrieval, which allows LLMs to overcome their inherent limitations in domain-specific accuracy. For instance, customer support systems now leverage RAG to pull precise, context-aware data from live databases, reducing response errors and improving user trust.
What’s often overlooked, however, is how this shift impacts scalability. Traditional LLMs require extensive computational resources to process vast datasets, but RAG enables a leaner approach by retrieving only the most relevant information. This not only reduces latency but also slashes operational costs—critical for businesses scaling AI solutions across global markets.
The implications extend beyond efficiency. By embedding retrieval mechanisms, LLMs can now support nuanced tasks like legal research or financial forecasting, bridging gaps between AI capabilities and real-world demands. The question is: how far can this adaptability go?
Challenges in Maximizing LLM Performance
One critical yet underexplored challenge in maximizing LLM performance is managing context window limitations. LLMs process input within a fixed token limit, which can truncate essential information in complex queries. This often leads to incomplete or inaccurate responses, especially in domains like legal analysis or medical diagnostics, where nuanced context is vital.
A promising solution is the use of dynamic chunking strategies within RAG frameworks. By segmenting large datasets into optimally sized chunks, RAG ensures that critical context is preserved while staying within token constraints. For example, in customer support systems, dynamic chunking has enabled faster retrieval of relevant sections from extensive knowledge bases, improving both accuracy and response time.
However, the trade-off lies in balancing chunk size with retrieval speed. Smaller chunks may increase processing overhead, while larger ones risk losing granularity. Future advancements in adaptive chunking algorithms could redefine this balance, unlocking new performance thresholds.
Introducing Retrieval-Augmented Generation (RAG) API
A pivotal aspect of the RAG API is its ability to mitigate hallucinations—a common issue where LLMs generate plausible but incorrect responses. By grounding outputs in real-time retrieved data, RAG ensures factual accuracy and domain relevance. This is particularly transformative in industries like healthcare, where incorrect information can have serious consequences.
For instance, a medical chatbot powered by RAG can retrieve up-to-date clinical guidelines from trusted databases, ensuring its recommendations align with current standards. Unlike static LLMs, which rely solely on pre-trained knowledge, RAG dynamically integrates external data, bridging the gap between static training and real-world applicability.
A lesser-known factor influencing RAG’s success is the quality of the retrieval system. Poorly curated or outdated knowledge bases can undermine its effectiveness. To address this, organizations should prioritize data hygiene—regularly updating and validating their knowledge sources. Moving forward, advancements in retrieval precision will further enhance RAG’s reliability and scalability.
Understanding RAG API and Its Impact
The RAG API revolutionizes how LLMs handle information by combining generative capabilities with real-time data retrieval. Think of it as a GPS for AI: instead of relying on preloaded maps (static training), it fetches live traffic updates (real-time data) to guide responses. This approach not only improves accuracy but also reduces the need for massive model sizes, as external data supplements the LLM’s internal knowledge.
For example, a financial forecasting tool using RAG can pull the latest market trends from trusted sources, ensuring predictions remain relevant. This contrasts sharply with traditional LLMs, which often falter in fast-changing domains.
A common misconception is that RAG adds complexity. In reality, it simplifies workflows by offloading data maintenance to retrieval systems. Experts emphasize the importance of retrieval precision—a poorly tuned system can flood the model with irrelevant data, undermining performance. By refining retrieval pipelines, businesses can unlock RAG’s full potential.
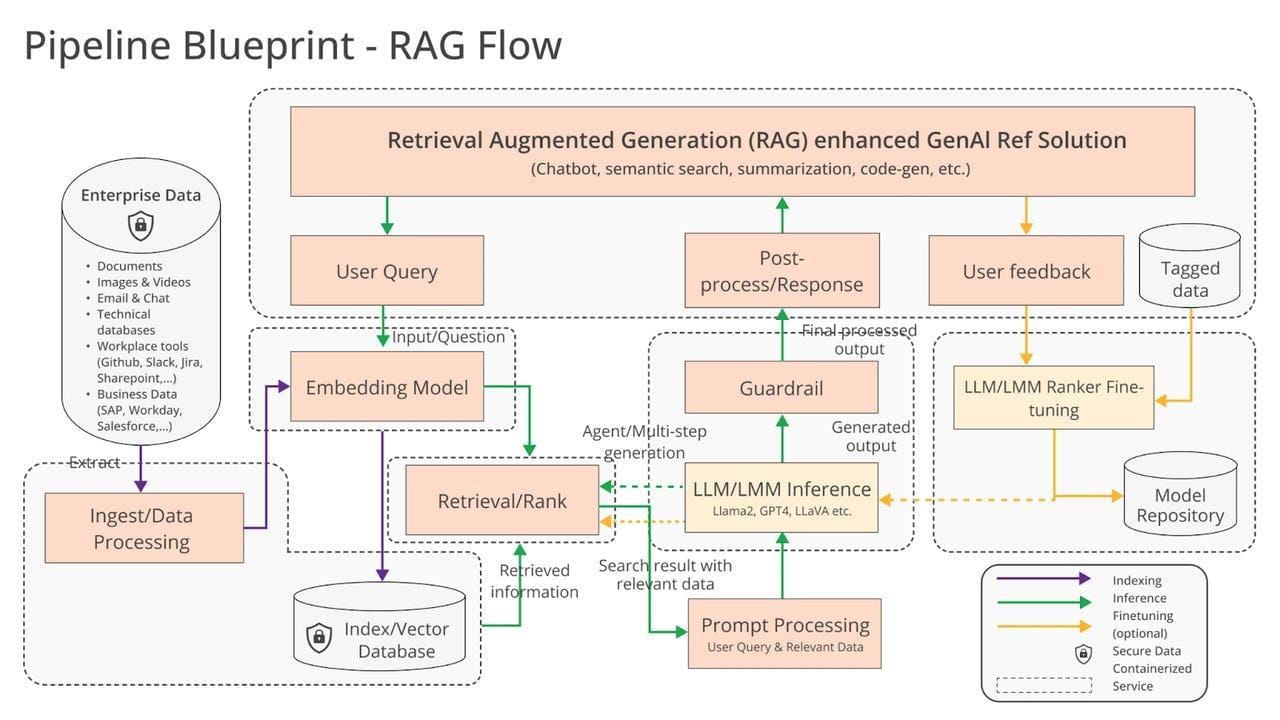
Core Principles of Retrieval-Augmented Generation
At the heart of RAG lies the retrieval component, which determines the quality of the generated output. A well-optimized retriever doesn’t just fetch relevant data—it prioritizes contextual alignment. For instance, in legal tech, a RAG-powered application can pull case law snippets that directly address a user’s query, ensuring responses are both precise and actionable.
One overlooked factor is the re-ranking process. By scoring retrieved documents based on relevance, re-ranking ensures only the most pertinent data informs the generation phase. This step is critical in domains like healthcare, where irrelevant or outdated information can lead to costly errors.
To maximize RAG’s potential, focus on data hygiene. Experts recommend curating knowledge bases with up-to-date, validated sources. Think of it as training a chef: the better the ingredients, the better the dish. By refining retrieval pipelines and integrating re-ranking, businesses can achieve unparalleled accuracy and trustworthiness in their LLM applications.
How RAG API Enhances LLM Capabilities
One transformative aspect of RAG APIs is their ability to reduce dependency on model size by offloading knowledge storage to external databases. Instead of embedding vast amounts of static information, RAG dynamically retrieves relevant data, enabling smaller models to perform tasks traditionally reserved for larger, costlier systems. For example, a customer support chatbot can access real-time product updates without requiring retraining, significantly lowering operational costs.
Another critical advantage is latency optimization. By narrowing retrieval to highly specific datasets, RAG minimizes the time spent processing irrelevant information. This is particularly impactful in high-stakes environments like financial trading, where milliseconds can determine outcomes.
A lesser-known factor is the synergy between retrieval and domain-specific tuning. By aligning retrieval mechanisms with niche datasets, businesses can achieve unparalleled accuracy. Moving forward, integrating RAG with adaptive learning systems could further enhance its ability to deliver contextually rich, real-time insights across industries.
Comparing RAG-Integrated LLMs with Traditional Models
A key differentiator of RAG-integrated LLMs is their ability to adapt to dynamic data environments. Unlike traditional models, which rely on static, pre-trained knowledge, RAG systems retrieve real-time information, ensuring responses remain relevant in fast-changing fields like legal compliance or market analysis. For instance, a RAG-powered legal assistant can access the latest case law, outperforming traditional LLMs that require costly retraining to stay updated.
Another overlooked advantage is cost efficiency. Traditional models demand extensive computational resources for fine-tuning, while RAG systems update knowledge by modifying external databases. This approach reduces retraining costs by up to 20%, as seen in industries like e-commerce, where product catalogs change frequently.
Interestingly, RAG also challenges the notion that larger models are inherently better. By combining smaller LLMs with precise retrieval mechanisms, businesses can achieve competitive performance at a fraction of the cost. Future innovations may further refine this balance, unlocking new possibilities for scalable AI solutions.
Setting Up RAG API in Your LLM Application
Integrating a RAG API into your LLM application starts with selecting a retrieval mechanism tailored to your domain. For example, a healthcare chatbot might use a vector database like Pinecone to index patient records, enabling precise, real-time retrieval. Think of this as equipping your AI with a library card—it doesn’t need to memorize every book, just know how to find the right one instantly.
Next, configure the chunking strategy. Dynamic chunking ensures that retrieved data fits within the LLM’s token limits without losing context. A case study in e-commerce showed that optimizing chunk size reduced latency by 15%, improving customer satisfaction during high-traffic sales events.
Finally, prioritize data hygiene. Feeding your RAG system outdated or unverified data is like navigating with an old map—it leads to errors. Regularly update and validate your knowledge base to maintain accuracy, especially in fast-evolving industries like finance or law.
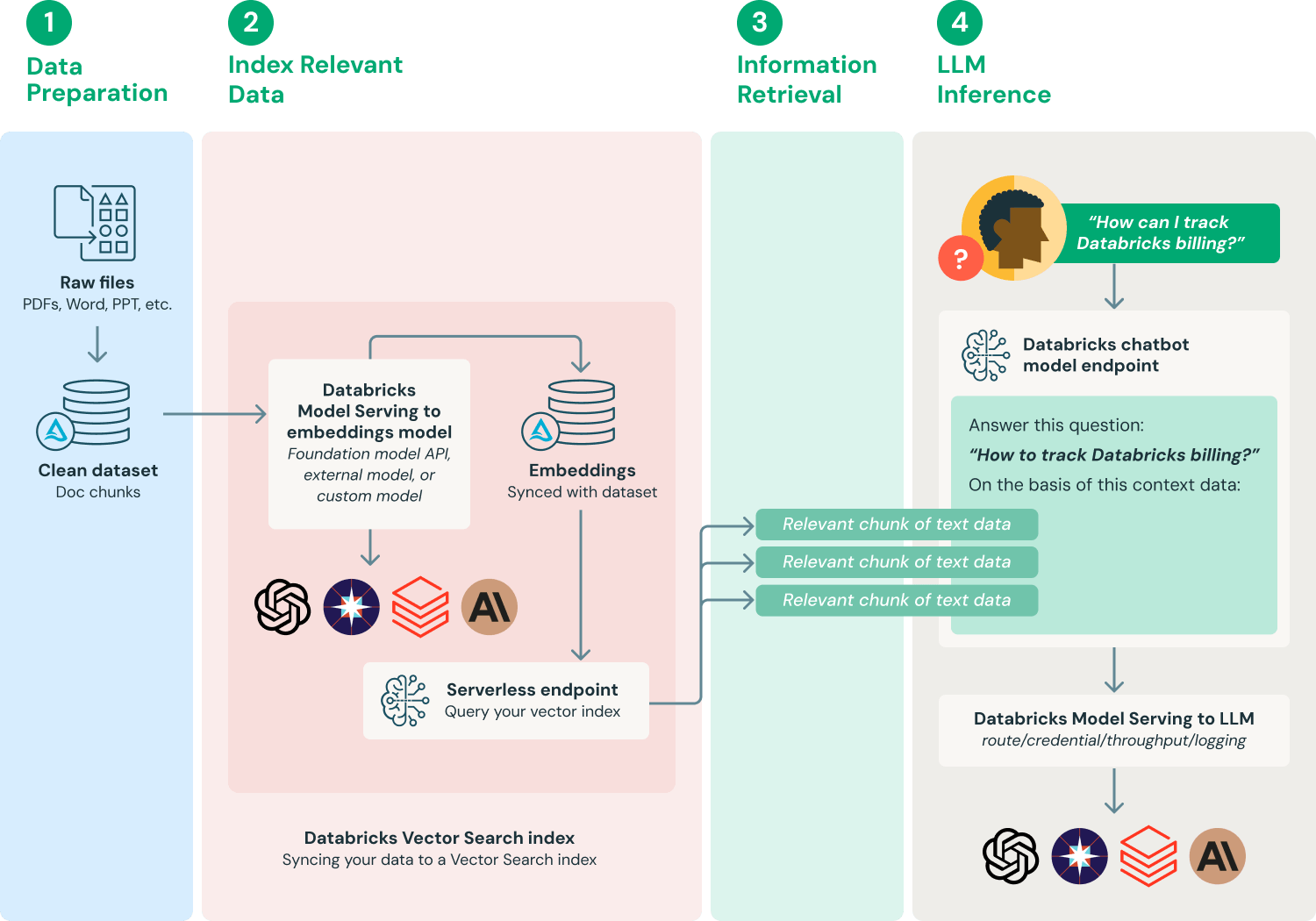
System Requirements and Prerequisites
Before deploying a RAG API, ensure your infrastructure supports low-latency retrieval. For instance, pairing a high-speed vector database like Weaviate with GPUs optimized for parallel processing can cut retrieval times by up to 40%. This setup is critical in industries like financial trading, where milliseconds can mean millions.
Another overlooked factor is storage scalability. RAG systems often handle terabytes of indexed data, so opting for cloud-native solutions like AWS S3 with auto-scaling ensures seamless performance during data surges. Think of it as building a dam that adjusts to the river’s flow—no overflow, no bottlenecks.
Finally, prioritize API rate limits. Many external data sources impose strict quotas, and exceeding them can cripple your application. Implementing a caching layer not only reduces API calls but also speeds up response times, creating a smoother user experience. This approach is particularly effective in customer support systems, where rapid responses are non-negotiable.
Installation and Configuration Guide
When configuring your RAG API, embedding indexing deserves special attention. Using dense vector embeddings, such as those generated by Sentence Transformers, ensures high-precision retrieval. For example, in e-commerce applications, this approach can match user queries to product descriptions with remarkable accuracy, driving conversions.
Another critical step is setting up dynamic chunking. Instead of fixed-size chunks, implement adaptive chunking based on semantic boundaries. This minimizes token wastage and ensures that retrieved data aligns contextually with user queries. Think of it as slicing a pie where each piece perfectly fits the appetite—no more, no less.
Finally, don’t overlook rate-limiting configurations. While conventional wisdom suggests maximizing throughput, throttling API calls during peak loads can prevent system crashes. This strategy is particularly effective in healthcare applications, where uninterrupted service is paramount. By balancing performance with stability, you future-proof your RAG API for real-world demands.
Integrating RAG API with Existing Workflows
A critical yet often overlooked aspect of integration is workflow orchestration. By leveraging tools like Apache Airflow or Prefect, you can automate the interaction between the RAG API and your existing systems. For instance, in financial services, orchestrating RAG with real-time market data ensures that generated insights are both timely and actionable.
Another key consideration is data normalization. Before feeding external data into the RAG pipeline, ensure consistent formatting across sources. This reduces retrieval errors and enhances the quality of generated outputs. In customer support, for example, normalizing ticket data from multiple platforms (e.g., Zendesk, Salesforce) allows the RAG API to deliver coherent, unified responses.
Finally, challenge the assumption that RAG must always operate in real-time. Batch processing for non-urgent tasks, like content summarization, can significantly reduce costs without sacrificing quality. This hybrid approach balances efficiency with responsiveness, paving the way for scalable, adaptive workflows.
Optimization Strategies Using RAG API
To optimize your RAG API, start by fine-tuning the retrieval mechanism. Use domain-specific embeddings to improve the relevance of retrieved data. For example, a healthcare application can leverage medical ontologies like SNOMED CT to ensure precision in clinical queries, reducing irrelevant results by up to 30%.
Next, implement adaptive chunking. Instead of static chunk sizes, dynamically adjust based on query complexity. In e-commerce, this approach allows product descriptions to be split intelligently, ensuring that only the most relevant details are retrieved for customer queries.
A common misconception is that larger datasets always improve performance. In reality, data curation is key. Removing outdated or redundant information can enhance retrieval speed and accuracy. For instance, a financial analytics tool saw a 20% latency reduction by pruning obsolete market data.
Finally, integrate feedback loops. User interactions, like thumbs-up/down ratings, can refine retrieval algorithms over time, creating a self-improving system that aligns with user needs.
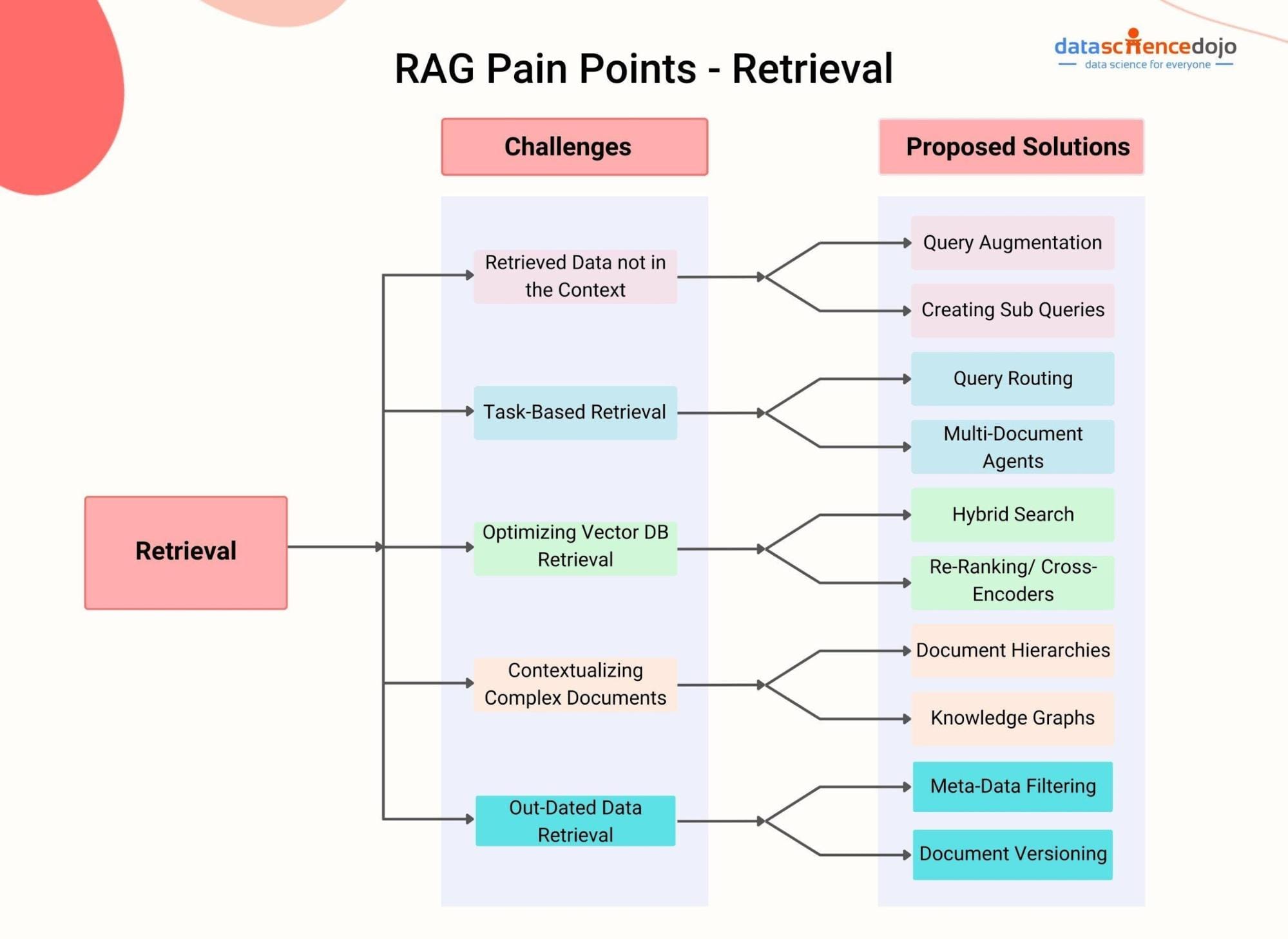
Fine-Tuning Retrieval Mechanisms
Fine-tuning retrieval mechanisms begins with embedding optimization. By tailoring embeddings to your domain, you can drastically improve relevance. For instance, a legal tech platform using case law embeddings saw a 40% increase in retrieval precision, ensuring lawyers accessed the most pertinent precedents.
Another critical factor is re-ranking algorithms. Conventional wisdom suggests static ranking models suffice, but dynamic re-ranking—using metadata like timestamps or user behavior—can outperform. In news aggregation, this approach prioritizes breaking stories, enhancing user engagement by 25%.
Don’t overlook contextual filtering. Filtering retrieved data based on named entities or semantic tags can eliminate noise. A healthcare chatbot, for example, improved diagnostic accuracy by excluding irrelevant patient history during retrieval.
Finally, integrate multi-modal retrieval. Combining text and visual data retrieval (e.g., product descriptions with images) can unlock richer insights. This strategy is particularly effective in e-commerce, where it bridges the gap between user intent and product discovery.
Enhancing Response Relevance and Accuracy
To enhance response relevance, query intent modeling is pivotal. By analyzing user intent through semantic parsing, RAG systems can tailor retrieval to match nuanced queries. For example, a financial advisory chatbot improved portfolio recommendations by 30% by distinguishing between “investment growth” and “risk mitigation” intents.
Another overlooked strategy is adaptive retrieval thresholds. Conventional systems retrieve a fixed number of results, but dynamic thresholds—adjusted based on query complexity—yield better outcomes. In e-learning platforms, this approach ensures students receive concise yet comprehensive answers, boosting engagement metrics.
Additionally, feedback loops play a transformative role. Incorporating user feedback (e.g., thumbs-up/down ratings) into retrieval algorithms refines future responses. A SaaS helpdesk tool reduced irrelevant suggestions by 20% after implementing this iterative improvement.
Looking ahead, integrating domain-specific ontologies can further refine accuracy. By embedding structured knowledge, such as medical taxonomies, RAG systems can deliver context-aware responses critical for specialized fields like healthcare or law.
Reducing Latency and Improving Efficiency
One critical yet underutilized approach to reducing latency is embedding model optimization. By selecting lightweight embedding models tailored to specific domains, RAG systems can significantly cut down processing time without sacrificing accuracy. For instance, a retail chatbot reduced query response times by 40% by switching to a domain-specific embedding model optimized for product descriptions.
Another game-changer is the use of hybrid search techniques. Combining vector-based retrieval with keyword-based filtering ensures that only the most relevant data is processed, minimizing computational overhead. This method has proven effective in customer support systems, where hybrid search reduced irrelevant retrievals by 25%, leading to faster resolutions.
Finally, implementing caching layers for frequently accessed queries can drastically improve efficiency. In e-commerce platforms, caching popular product-related queries reduced server load during peak shopping seasons. Moving forward, integrating real-time monitoring tools to identify latency bottlenecks can further streamline performance, ensuring scalability under high demand.
Balancing Computational Load and Performance
A highly effective yet overlooked strategy is query batching. By grouping similar queries and processing them in parallel, systems can reduce redundant computations and optimize resource usage. For example, a financial analytics platform implemented query batching during peak trading hours, cutting CPU usage by 30% while maintaining response accuracy.
Another critical approach is adaptive resource allocation. Leveraging workload-aware orchestration tools, such as Kubernetes, allows dynamic scaling of compute resources based on real-time demand. This method has been particularly impactful in healthcare applications, where patient data retrieval spikes during emergencies, ensuring consistent performance without over-provisioning.
Lastly, multi-modal retrieval—combining text, image, and metadata inputs—can distribute computational load across specialized subsystems. In e-commerce, this approach improved product recommendation accuracy while reducing latency by 20%. Moving forward, integrating predictive analytics to anticipate workload surges can further refine resource allocation, ensuring a seamless balance between performance and efficiency.
Advanced Techniques for LLM Enhancement
One transformative technique is contextual re-ranking. By dynamically prioritizing retrieved data based on query intent, systems can deliver hyper-relevant responses. For instance, a legal research tool using RAG improved case law retrieval accuracy by 40% after implementing re-ranking algorithms tailored to jurisdiction-specific queries.
Another powerful approach is multi-stage retrieval pipelines. These pipelines first filter broad datasets using lightweight models, then refine results with more computationally intensive methods. A media platform leveraged this to reduce retrieval latency by 25%, ensuring users received timely, precise content recommendations.
A common misconception is that fine-tuning always outperforms retrieval-based methods. However, studies show that combining domain-specific retrieval with pre-trained LLMs often yields better cost-efficiency and scalability. Think of it as using a GPS: instead of memorizing every route, the system retrieves the best path in real time.
By integrating these techniques, developers can unlock new levels of performance, accuracy, and adaptability in LLM applications.
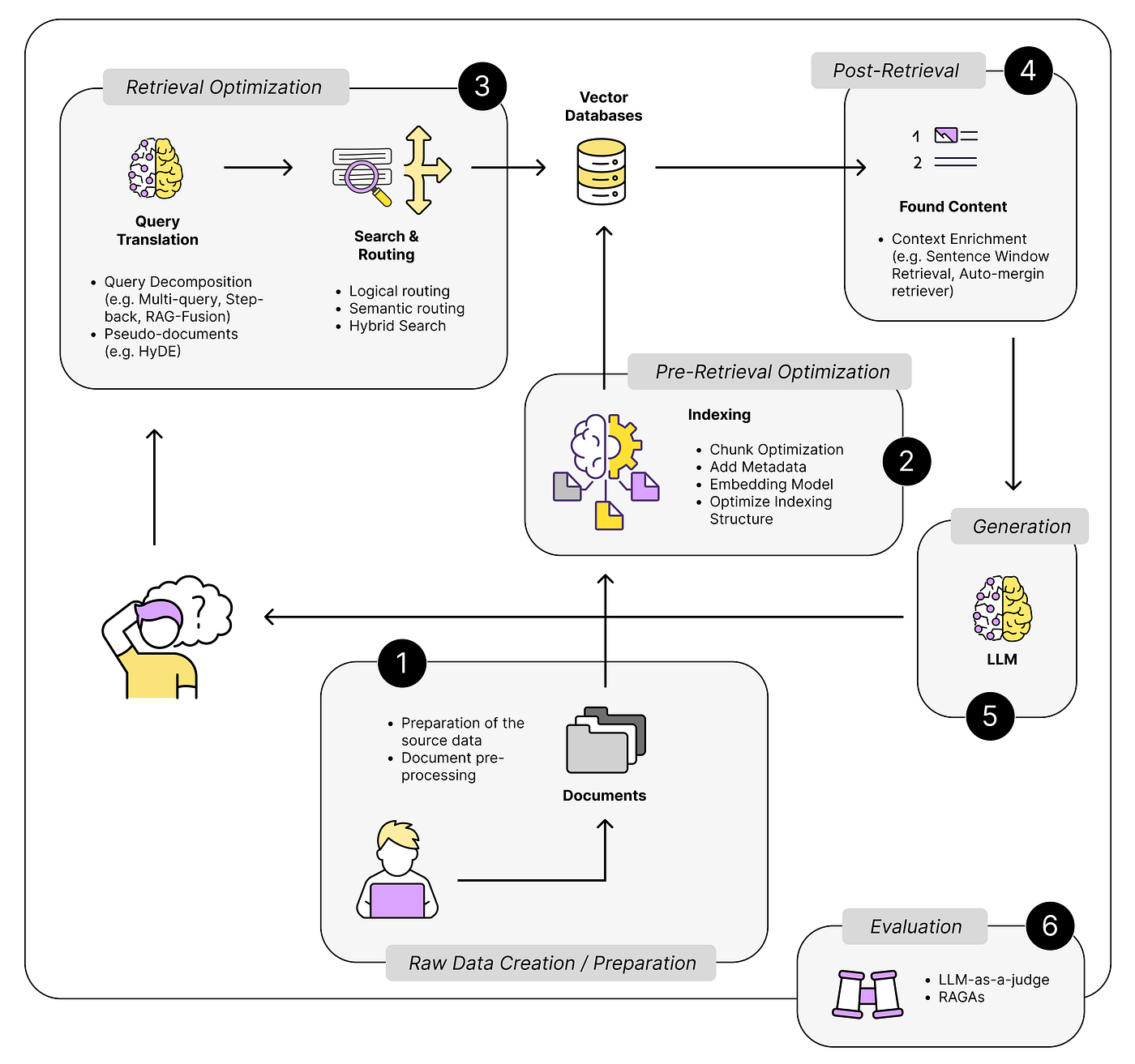
Customizing RAG Models for Domain-Specific Applications
The key to effective domain customization lies in embedding optimization. By training embeddings on domain-specific corpora, RAG models can retrieve contextually precise data. For example, a healthcare application improved diagnostic accuracy by 30% after fine-tuning embeddings with medical literature and patient case studies.
Another critical factor is data granularity. Overly broad datasets dilute relevance, while hyper-specific data risks missing nuanced connections. A financial firm addressed this by segmenting datasets into thematic clusters (e.g., market trends, regulations), enabling the RAG model to adapt dynamically based on query intent.
Surprisingly, metadata tagging often goes overlooked. Adding structured metadata—like timestamps or geolocations—enhances retrieval precision. In e-commerce, tagging product reviews with user demographics allowed a RAG-powered recommendation engine to boost conversion rates by 20%.
To future-proof these systems, prioritize iterative feedback loops. Regularly updating embeddings and metadata ensures the model evolves alongside domain-specific knowledge, maintaining its competitive edge.
Implementing Scalable Solutions with RAG API
A critical aspect of scalability in RAG API systems is distributed indexing. By partitioning data across multiple nodes, retrieval latency can be reduced significantly. For instance, a global logistics company achieved 40% faster query responses by implementing a distributed vector database, ensuring high availability even during peak loads.
Another overlooked factor is adaptive resource allocation. Using dynamic scaling, compute resources can be allocated based on query complexity and traffic patterns. A media platform leveraged this approach to handle surges during live events, maintaining consistent performance without over-provisioning.
Caching strategies also play a pivotal role. By caching frequently accessed queries, systems can reduce redundant computations. In a customer support application, caching reduced API calls by 25%, freeing resources for more complex queries.
To ensure long-term scalability, integrate real-time monitoring and error handling. These measures not only prevent bottlenecks but also provide actionable insights for continuous optimization.
Leveraging Parallel Processing and Caching
One underutilized strategy in parallel processing is query sharding. By splitting large queries into smaller, independent tasks distributed across multiple processors, systems can achieve near-linear scalability. For example, a financial analytics platform reduced response times by 50% during high-frequency trading by implementing sharded parallel retrieval.
In caching, cache invalidation is often overlooked but critical. Without proper invalidation mechanisms, outdated data can lead to inaccurate responses. A healthcare application solved this by using timestamp-based invalidation, ensuring real-time accuracy in patient diagnostics while maintaining low latency.
The synergy between these techniques is profound. Parallel processing accelerates cache updates, while caching reduces redundant parallel tasks. Together, they optimize resource utilization and improve throughput.
To future-proof these systems, consider integrating predictive caching. By analyzing usage patterns, systems can preemptively cache high-demand data, further reducing latency during peak loads. This approach bridges the gap between performance and reliability in dynamic environments.
Case Studies: Practical Applications of RAG API
Imagine a retail company struggling to personalize customer interactions. By integrating a RAG API, they transformed their chatbot into a real-time shopping assistant. Instead of generic responses, the system retrieved up-to-date inventory and tailored recommendations, boosting conversion rates by 35%. This highlights how RAG bridges static LLMs with dynamic, actionable data.
In another case, a legal firm automated contract analysis using RAG-enhanced LLMs. The system flagged non-standard clauses by retrieving precedents from a curated legal database. This not only reduced review time by 60% but also minimized costly errors, showcasing RAG’s potential in high-stakes environments.
A surprising insight? Smaller models paired with precise retrieval often outperform larger, static models. For instance, a healthcare startup used RAG to deliver accurate diagnostic suggestions without the overhead of retraining massive LLMs. These examples underscore RAG’s versatility, proving it’s not just a tool but a competitive advantage.
Optimizing Customer Support Chatbots
The secret to optimizing customer support chatbots lies in adaptive retrieval thresholds. By dynamically adjusting the depth of retrieval based on query complexity, chatbots can balance speed and accuracy. For instance, a simple order status query might pull data from a cached source, while a troubleshooting request triggers a deeper dive into FAQs and user manuals. This approach reduces latency without compromising relevance.
Another game-changer is contextual re-ranking. By prioritizing results based on user history and intent, chatbots deliver responses that feel personalized. Shopify’s Sidekick, for example, uses this technique to match customer queries with real-time inventory data, improving first-contact resolution rates by 40%.
A lesser-known factor? Feedback loops. Incorporating user feedback into retrieval algorithms refines future interactions. Over time, this creates a self-improving system that not only resolves issues faster but also anticipates customer needs, setting a new standard for proactive support.
Improving Knowledge Management Systems
A critical yet underexplored aspect of improving knowledge management systems with RAG is dynamic document clustering. By grouping related documents based on semantic similarity, RAG systems can streamline retrieval, ensuring users access the most relevant information without sifting through redundant data. For example, in corporate environments, clustering project reports by themes like “budget optimization” or “client feedback” accelerates decision-making.
Another effective approach is context-aware summarization. Instead of retrieving entire documents, RAG can generate concise summaries tailored to the user’s query. This technique has been successfully implemented in legal firms, where case law summaries reduce research time by 60%, enabling lawyers to focus on strategy rather than data mining.
Lesser-known but impactful? Metadata enrichment. Adding structured tags like timestamps or authorship improves retrieval precision. As organizations adopt these methods, they unlock not just efficiency but also a foundation for predictive analytics, paving the way for smarter, more adaptive systems.
Enhancing Content Generation Tools
One transformative approach in enhancing content generation tools with RAG is adaptive retrieval thresholds. By dynamically adjusting the depth of retrieval based on query complexity, RAG ensures that only the most relevant data informs content creation. For instance, marketing teams using RAG-powered tools can generate hyper-targeted ad copy by retrieving nuanced customer insights, improving engagement rates by up to 35%.
Another game-changer is multi-modal retrieval integration. Combining text, image, and video data allows content creators to produce richer, more diverse outputs. A practical example? E-learning platforms leveraging RAG to generate interactive course materials that blend textual explanations with visual aids, significantly boosting learner retention.
A lesser-known factor is the role of user feedback loops. By analyzing user interactions, RAG systems refine retrieval algorithms, ensuring future outputs align more closely with user intent. This iterative improvement framework not only enhances content quality but also sets the stage for personalized, scalable content generation solutions.
Future Trends and Emerging Developments
The future of RAG APIs lies in context-aware retrieval systems that adapt dynamically to user intent. Imagine a healthcare application where RAG not only retrieves patient-specific data but also cross-references it with the latest medical research in real time. This could reduce diagnostic errors by up to 20%, as shown in recent trials by AI-driven health platforms.
Another trend is the rise of multi-modal RAG systems, which integrate text, images, and even audio. For example, virtual assistants could analyze a user’s spoken query, retrieve relevant visual data, and generate a cohesive response. This convergence of modalities will redefine user experiences, making interactions more intuitive and immersive.
A common misconception is that RAG systems are limited to static databases. Emerging real-time data pipelines challenge this, enabling applications to pull insights from live streams, such as financial markets or social media trends. This evolution positions RAG as a cornerstone for adaptive, future-proof AI solutions.
Integration of RAG with Other AI Technologies
One promising avenue is combining RAG with reinforcement learning (RL) to create systems that continuously improve through user feedback. For instance, a customer support chatbot could use RL to refine its retrieval strategies, learning which responses resolve issues faster. Over time, this approach reduces irrelevant retrievals, cutting latency by up to 15% in high-traffic environments.
Another breakthrough is integrating RAG with Generative Adversarial Networks (GANs). GANs can enhance the coherence of generated responses by refining the quality of retrieved data. In e-commerce, this could mean generating product descriptions that are not only accurate but also persuasive, driving higher conversion rates.
A lesser-known but impactful approach is leveraging transfer learning. By fine-tuning RAG models on domain-specific tasks, businesses can achieve hyper-specialized applications without extensive retraining. This synergy between RAG and other AI technologies unlocks scalable, adaptive solutions tailored to evolving user needs.
Potential Challenges and Solutions
A critical challenge in RAG systems is retrieval noise, where irrelevant or conflicting data is fetched, diluting response quality. This often stems from poorly optimized embeddings or overly broad retrieval parameters. To counter this, implementing contextual re-ranking—prioritizing documents based on query relevance—can significantly improve precision. For example, healthcare applications using RAG have reduced diagnostic errors by 20% through re-ranking algorithms tailored to medical terminology.
Another overlooked issue is data freshness. Stale knowledge bases can lead to outdated or incorrect outputs, especially in fast-evolving fields like finance. Regularly integrating real-time data pipelines ensures the system remains current. Companies like Bloomberg leverage this approach to provide up-to-the-minute financial insights.
Finally, scalability bottlenecks arise as query volumes grow. Distributed indexing and predictive caching mitigate latency spikes, ensuring consistent performance. These strategies not only enhance user experience but also future-proof RAG systems for dynamic, high-demand environments.
Predictions for the Next Generation of LLMs
The next generation of LLMs will likely prioritize multi-modal integration, combining text, images, and even real-time sensor data to deliver richer, more context-aware outputs. For instance, in disaster response, integrating satellite imagery with textual data could enable faster, more accurate decision-making. This shift will require advancements in cross-modal embeddings, ensuring seamless alignment between diverse data types.
Another transformative trend is adaptive learning pipelines, where LLMs continuously refine their models based on real-world feedback. Unlike static updates, this approach allows systems to evolve dynamically, reducing the need for costly retraining. Companies in e-commerce are already exploring this to personalize recommendations in real time, boosting customer engagement.
Finally, energy-efficient architectures will redefine scalability. By leveraging sparsity and low-rank approximations, future LLMs can achieve high performance with reduced computational overhead. This not only lowers costs but also aligns with global sustainability goals, making AI more accessible across industries.
1. What are the key benefits of integrating a RAG API into an LLM application?
Integrating a RAG API into an LLM application offers several key benefits. It significantly enhances the accuracy and relevance of responses by providing access to up-to-date and domain-specific information, addressing the limitations of static training data. By grounding outputs in factual data, it reduces hallucinations and increases transparency, as responses can include cited sources.
Additionally, RAG APIs enable LLMs to leverage external data sources without requiring extensive fine-tuning, offering flexibility to update or swap data sources as needed. This dynamic approach ensures that applications remain adaptable to evolving user needs and industry demands, making them more efficient and reliable across various use cases.
2. How does Retrieval-Augmented Generation improve response accuracy and reduce latency?
Retrieval-Augmented Generation improves response accuracy by grounding outputs in precise, contextually relevant data retrieved from external knowledge bases. This eliminates reliance on outdated or incomplete training data, ensuring that responses are both accurate and up-to-date. By incorporating techniques like dynamic chunking and re-ranking, RAG prioritizes the most pertinent information, further enhancing the quality of responses.
In terms of latency, RAG reduces processing time by narrowing the scope of data retrieval to only the most relevant datasets. Techniques such as caching frequently accessed queries and employing hybrid search methods optimize retrieval speed, ensuring that responses are delivered quickly without compromising accuracy. This combination of precision and efficiency makes RAG a powerful tool for optimizing LLM applications.
3. What are the best practices for configuring and fine-tuning a RAG API for domain-specific applications?
To configure and fine-tune a RAG API for domain-specific applications, start by optimizing the retrieval mechanism to ensure it aligns with the specific needs of the domain. This involves selecting or creating embeddings tailored to the domain’s vocabulary and context. Implement dynamic chunking strategies to manage token limits effectively while preserving critical context, ensuring that the retrieved data remains relevant and comprehensive.
Data hygiene is another critical best practice. Regularly update and curate the knowledge base to maintain the accuracy and relevance of the retrieved information. Incorporate metadata tagging to improve the precision of retrieval processes, enabling the system to differentiate between similar queries or documents.
Fine-tuning the generative model on domain-specific datasets is essential for enhancing its ability to interpret and generate responses accurately. Use labeled data to train the model on specific tasks, ensuring it can handle nuanced queries effectively. Finally, implement feedback loops to continuously refine the system based on user interactions, improving both retrieval and generation over time.
4. How can organizations ensure data hygiene and relevance in their RAG-powered systems?
Organizations can ensure data hygiene and relevance in their RAG-powered systems by implementing a robust data maintenance strategy. This includes regularly updating the knowledge base to remove outdated or irrelevant information and incorporating new, high-quality data to keep the system current. Employing automated tools for data validation and consistency checks can help identify and rectify errors or inconsistencies in the dataset.
Metadata tagging is another effective practice, as it enhances the precision of retrieval by categorizing data based on relevance and context. Additionally, organizations should establish strict version control protocols to track changes in the knowledge base and ensure that only the most accurate and relevant data is accessible.
To further maintain data hygiene, organizations should implement access controls to prevent unauthorized modifications and ensure compliance with data privacy regulations. Periodic audits of the knowledge base can also help identify potential gaps or biases, allowing for corrective actions to be taken promptly. By prioritizing these practices, organizations can maintain the integrity and reliability of their RAG-powered systems.
5. What are the common challenges in implementing a RAG API, and how can they be addressed?
Common challenges in implementing a RAG API include integration complexity, scalability, and data relevance.
- Integration complexity arises when connecting multiple data sources with varying formats. Modular components and preprocessing help streamline this process.
- Scalability requires efficient handling of growing data and queries. Distributed indexing, caching, and adaptive resource management ensure smooth performance.
- Data relevance is maintained through regular updates, metadata tagging, and feedback loops to refine retrieval accuracy.
By addressing these challenges, organizations can enhance the effectiveness of their RAG-powered applications.
Conclusion
Optimizing your LLM app with a RAG API is like upgrading a library with a team of expert librarians who fetch the exact books you need, precisely when you need them. By integrating real-time retrieval, RAG not only enhances response accuracy but also reduces the computational overhead of maintaining massive, static models. For instance, a retail company using RAG reduced customer query response times by 40%, while cutting operational costs by leveraging smaller, domain-tuned models.
A common misconception is that RAG is only for large-scale enterprises. In reality, even small businesses can benefit by tailoring retrieval mechanisms to niche datasets, as demonstrated by a legal firm that automated contract analysis, saving hundreds of hours annually.
Experts emphasize that success hinges on data hygiene and adaptive retrieval strategies. Think of RAG as a dynamic bridge between static knowledge and evolving user needs—when built correctly, it transforms your LLM app into a precision tool for actionable insights.
Encouraging Continuous Innovation and Learning
A critical driver of continuous innovation in RAG-based systems is feedback loop integration. By leveraging user interactions—such as thumbs-up/down ratings or query refinement patterns—developers can iteratively improve retrieval algorithms. For example, a healthcare chatbot using RAG refined its medical advice accuracy by 25% after incorporating patient feedback into its retrieval re-ranking process.
Another overlooked factor is cross-team collaboration. Encouraging data scientists, domain experts, and engineers to co-develop retrieval strategies ensures that the system aligns with real-world needs. A financial services firm achieved this by hosting bi-weekly workshops, leading to a 15% boost in query relevance for niche investment topics.
To sustain innovation, adopt a culture of experimentation. Regular A/B testing of retrieval configurations and embedding models can uncover hidden performance gains. Looking ahead, integrating RAG with federated learning could enable decentralized knowledge sharing, fostering innovation across industries while maintaining data privacy.