
Optimizing RAG Systems for Sensitive Data and Privacy Compliance
Handling sensitive data in RAG systems requires strict privacy and compliance measures. This guide covers techniques to secure data, ensure regulatory alignment (e.g., GDPR, HIPAA), and maintain performance while protecting user confidentiality.


RAG systems are becoming central to how industries retrieve and generate knowledge—but they come with a hidden cost.
When sensitive data moves through these systems, even small gaps in design can lead to serious privacy risks.
That’s why optimizing RAG systems for sensitive data and privacy compliance is no longer optional. It’s a foundational requirement.
Encryption alone doesn’t solve the problem. What matters is how retrieval, generation, and access interact—because one weak point is all it takes.
In this article, we unpack what optimizing RAG systems for sensitive data and privacy compliance really looks like.
We break down the risks, the frameworks, and the design principles needed to build systems that are not just powerful—but also secure and compliant from the ground up.
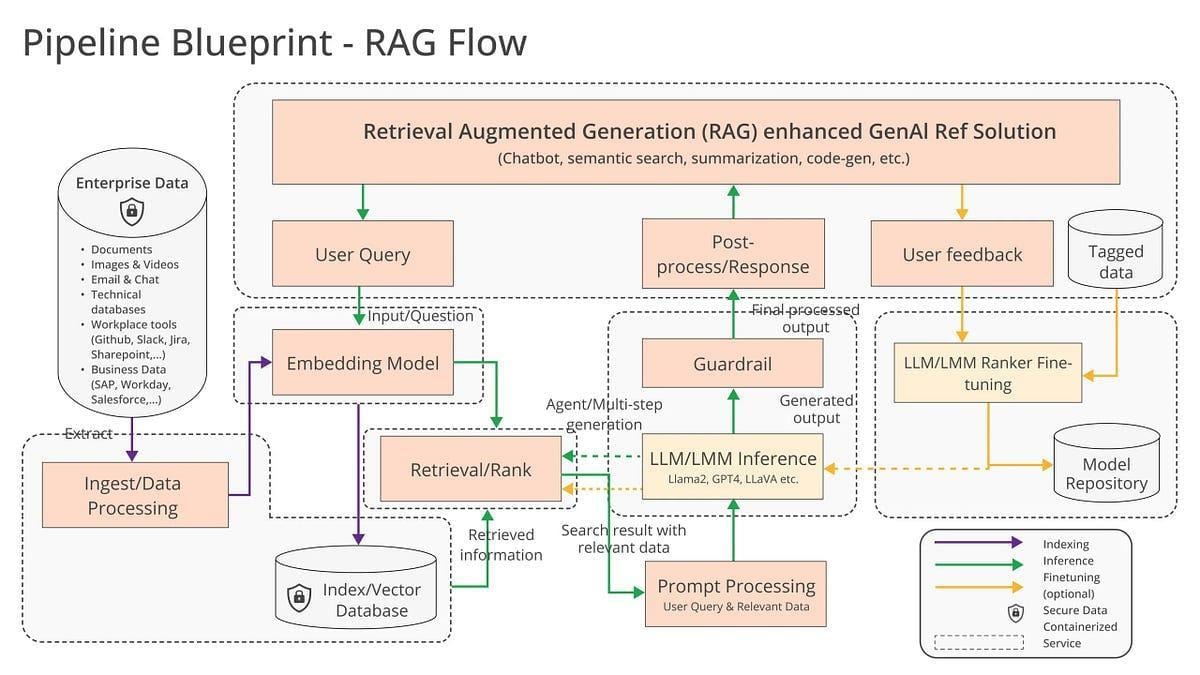
Understanding RAG Architecture
The integration of differential privacy into RAG systems represents a pivotal advancement in safeguarding sensitive data during retrieval and generation processes.
Unlike traditional anonymization techniques, differential privacy introduces controlled noise into datasets, ensuring that individual data points remain indistinguishable while preserving the utility of the overall dataset.
This nuanced approach directly addresses the challenge of balancing privacy with model performance.
One of the most critical mechanisms underpinning this technique is the calibration of noise levels.
If the noise is too high, the model’s accuracy suffers; too low, and privacy guarantees weaken.
However, its implementation is not without challenges.
Contextual factors, such as the diversity of input queries and the sensitivity of the knowledge base, can influence its effectiveness.
Fine-tuning these parameters requires a deep understanding of both the theoretical underpinnings and the practical constraints of real-world applications.
Importance of Privacy Compliance in AI Systems
Privacy compliance in AI systems hinges on the principle of data minimization, a cornerstone of regulations like GDPR.
This concept ensures that only the smallest necessary subset of data is processed, reducing exposure risks.
However, its implementation in RAG systems is far from straightforward. The challenge lies in balancing minimal data usage with the system’s need for contextual accuracy during retrieval and generation.
One advanced approach involves context-aware data filtering, where algorithms dynamically assess the relevance of data before retrieval.
For example, a financial institution employing RAG systems integrated attribute-based access control (ABAC) with tokenization.
This ensured sensitive account details were replaced with tokens during retrieval, maintaining compliance without sacrificing functionality. Such techniques highlight the interplay between technical precision and regulatory adherence.
Despite its promise, data minimization faces limitations in edge cases, such as multilingual datasets where semantic nuances demand broader data scopes.
Addressing these complexities requires adaptive frameworks that align with evolving regulations. By embedding compliance into the architecture itself, organizations mitigate risks and foster trust and operational resilience.
Core Principles of Data Privacy in RAG Systems
The foundation of data privacy in Retrieval-Augmented Generation (RAG) systems lies in proactive architectural design that integrates privacy safeguards at every layer.
Unlike traditional systems, RAG architectures must address the dual challenge of protecting sensitive data during both retrieval and generation processes.
This requires a shift from reactive measures to privacy-by-design frameworks, where compliance and security are embedded from inception.
One critical principle is contextual data anonymization, which ensures that sensitive information is stripped or masked dynamically based on the query context.
For instance, a RAG system deployed in healthcare might anonymize patient identifiers in real-time while preserving the semantic integrity of medical records. This approach mitigates privacy risks and maintains the system’s utility for decision-making.
Another cornerstone is granular access control mechanisms. Techniques like Role-Based Access Control (RBAC) and Attribute-Based Access Control (ABAC) allow organizations to enforce strict permissions, ensuring that only authorized users can access specific data subsets.
This layered approach minimizes exposure risks, particularly in high-stakes industries like finance and healthcare.
By integrating these principles, RAG systems can balance operational efficiency and robust privacy compliance, fostering trust and resilience in sensitive data environments.
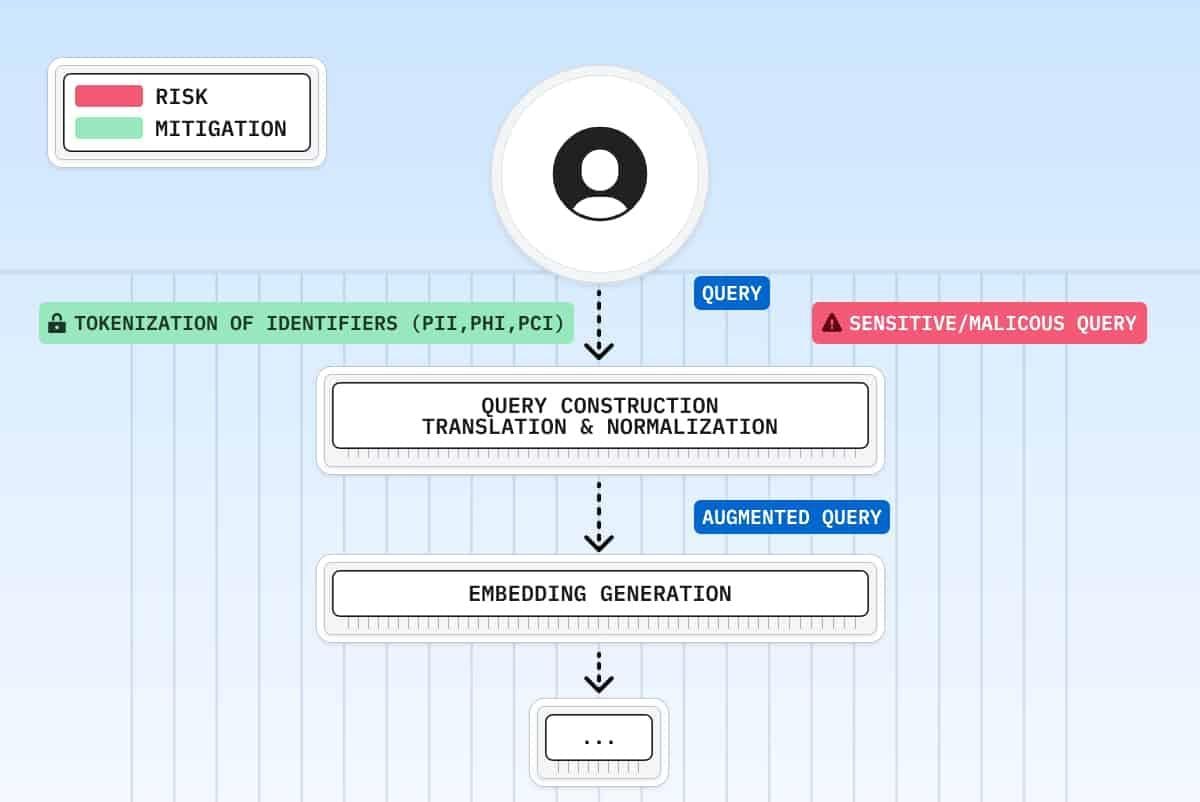
Data Anonymization and Pseudonymization Techniques
Anonymization and pseudonymization in RAG systems are not merely about obscuring data—they are about crafting a dynamic framework that adapts to the context of each query.
The distinction between these techniques lies in their reversibility: while pseudonymization replaces identifiers with reversible tokens, anonymization ensures irreversibility, making re-identification virtually impossible.
This distinction is critical in high-stakes environments like healthcare and finance, where even partial exposure can have severe consequences.
One advanced approach involves dynamic k-anonymity, where the system generalizes data outputs to ensure that any reference pertains to at least k individuals.
For example, to comply with HIPAA standards, a healthcare RAG system might aggregate patient data into broader categories, such as age ranges or geographic regions. This ensures privacy without compromising the utility of the data for clinical insights.
However, challenges arise in multilingual datasets, where semantic nuances can inadvertently expose sensitive information. Addressing this requires integrating context-sensitive masking algorithms that dynamically adjust based on linguistic and cultural factors.
By embedding these techniques into the RAG architecture, organizations can achieve robust privacy compliance while maintaining operational efficiency.
Regulatory Compliance: GDPR and HIPAA
Ensuring GDPR and HIPAA compliance in RAG systems requires a meticulous focus on data lineage tracking—a process often overlooked but critical for maintaining regulatory adherence.
Data lineage involves mapping the flow of sensitive information across the RAG pipeline, from ingestion to retrieval, ensuring every interaction is logged and auditable.
This approach matters because it addresses a core challenge: proving compliance during audits.
By embedding lineage tracking mechanisms, organizations can demonstrate how data is processed, anonymized, and accessed, satisfying both GDPR’s accountability principle and HIPAA’s audit control requirements.
For instance, integrating immutable logging systems ensures that every data access or modification is recorded, creating a transparent compliance trail.
A nuanced aspect of this process is the dynamic tagging of sensitive data.
RAG systems can automate compliance actions like data deletion or restricted access by assigning metadata that specifies regulatory requirements (e.g., GDPR’s right to erasure). However, this requires robust metadata governance to avoid misclassification, which could lead to compliance failures.
Technical Foundations for Secure RAG Implementations
The security of Retrieval-Augmented Generation (RAG) systems hinges on a robust interplay of advanced methodologies, each addressing distinct vulnerabilities while maintaining operational efficiency.
At the core lies vector embedding security, a technique that safeguards sensitive data encoded within embeddings. Unlike raw data, embeddings can inadvertently reveal patterns or identifiers if improperly secured.
Complementing this is the integration of confidential computing environments, such as Intel SGX, which isolate sensitive computations within secure enclaves. This ensures that even during processing, data remains inaccessible to unauthorized entities.
A common misconception is that encryption alone suffices. However, multi-layered security architectures—combining encryption, access controls, and real-time anomaly detection—are essential.
This layered approach mirrors a “defense-in-depth” strategy, akin to fortifying a castle with multiple walls, ensuring that breaching one layer does not compromise the entire system.
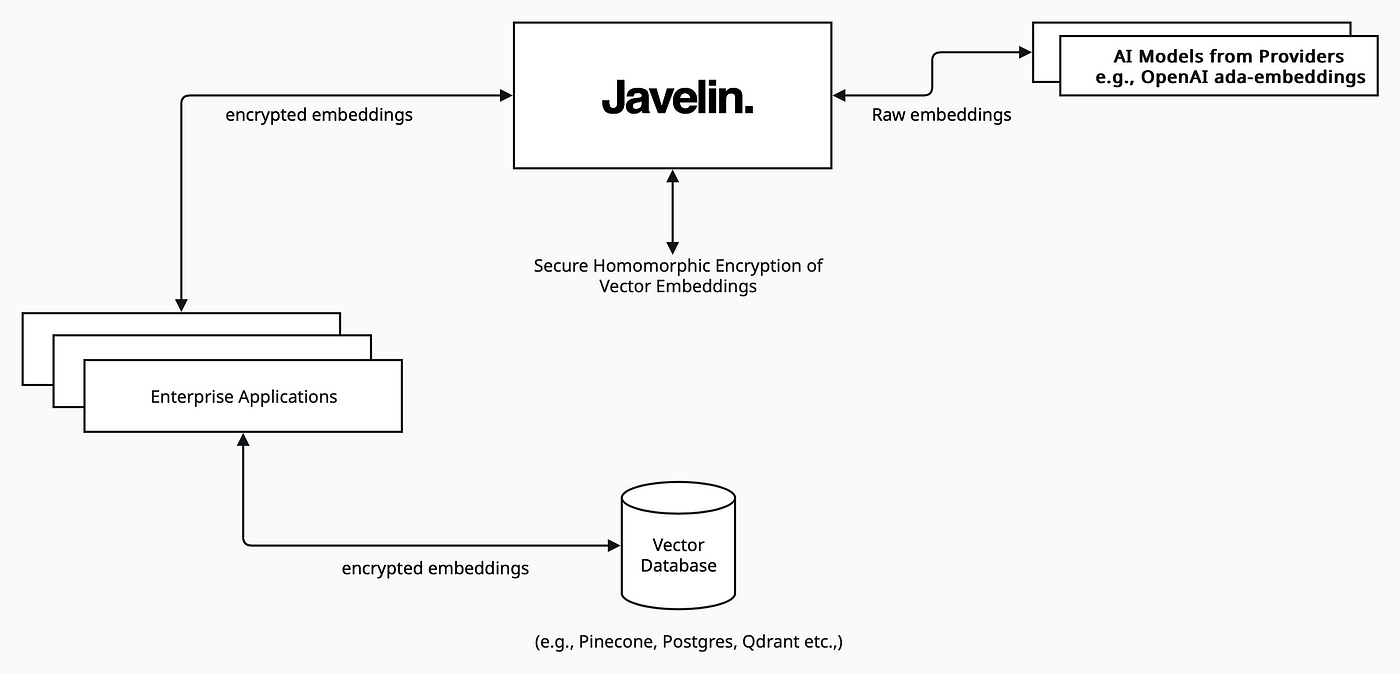
Vector Embedding Security and Encrypted Databases
Securing vector embeddings within RAG systems requires more than encryption; it demands a holistic approach integrating encryption with advanced access controls and key management.
Embeddings, while abstract representations, can inadvertently encode sensitive patterns, making their protection critical.
The challenge lies in ensuring that encryption secures data at rest and prevents adversarial reconstruction during retrieval.
A particularly effective method involves combining searchable encryption with context-aware access policies.
Searchable encryption allows embeddings to remain encrypted while still enabling similarity searches. This balances security with functionality, ensuring that sensitive data is not exposed during retrieval.
However, its effectiveness depends on the encryption scheme's precision and the access policies' robustness.
For instance, context-aware policies dynamically adjust access permissions based on factors like user behavior and query intent, adding layer of security.
One overlooked complexity is the trade-off between encryption granularity and system performance.
Fine-grained encryption enhances security but can slow retrieval processes, especially in high-traffic environments.
Addressing this requires adaptive frameworks optimizing encryption levels based on query sensitivity, ensuring security and efficiency. This nuanced approach exemplifies how embedding security must evolve to meet the demands of real-world applications.
Differential Privacy Techniques in RAG
Differential privacy in RAG systems hinges on precisely calibrating noise to safeguard sensitive data while maintaining system utility.
This technique introduces controlled randomness into query responses, ensuring individual data points remain indistinguishable.
However, the challenge lies in tailoring the noise to the context—too much disrupts accuracy, while too little compromises privacy.
One advanced approach involves adaptive privacy budgets, which dynamically adjusts noise levels based on query sensitivity.
For instance, in a legal RAG application, queries involving case law summaries may require minimal noise to preserve interpretability, whereas client-specific data demands higher privacy thresholds.
This adaptability ensures compliance without sacrificing functionality.
Despite its promise, this approach faces limitations in multilingual datasets, where semantic variations complicate noise calibration.
Addressing these nuances requires integrating linguistic models that align privacy mechanisms with language-specific structures, ensuring consistent protection across diverse contexts.
This evolution highlights the intricate balance between privacy and operational precision.
Advanced Privacy-Preserving Techniques
To fortify RAG systems against evolving privacy threats, contextual encryption and zero-trust architectures have emerged as transformative methodologies.
Contextual encryption dynamically adjusts encryption levels based on the sensitivity of the data being retrieved, ensuring that even during high-volume queries, sensitive information remains inaccessible.
For example, a financial RAG system might encrypt transaction data more rigorously than general account summaries, optimizing both security and performance.
On the other hand, zero-trust architectures redefine access control by continuously verifying user identities and permissions at every interaction point.
Unlike traditional models, which assume trust within internal networks, zero-trust frameworks treat every access attempt as potentially malicious.
These techniques not only enhance security but also align with stringent regulations like GDPR, ensuring compliance without compromising functionality.
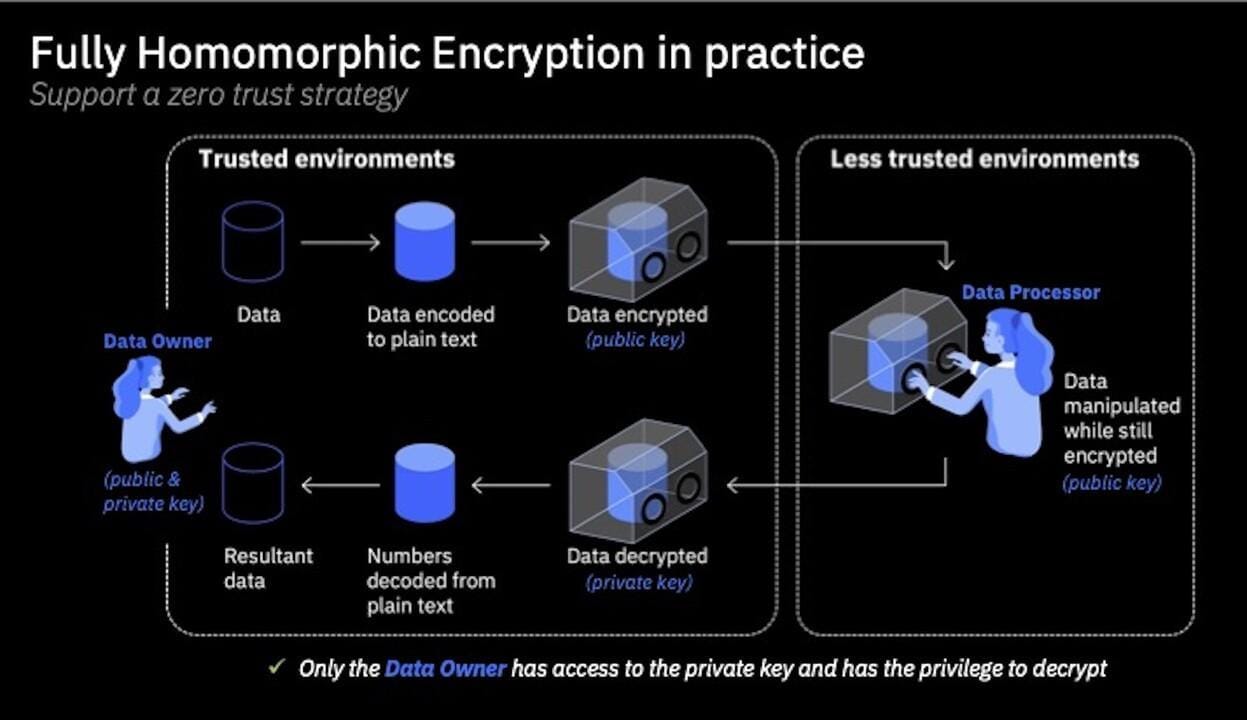
Context-Based Access Control Mechanisms
Context-based access control (CBAC) transcends traditional role-based systems by dynamically adapting permissions based on the specific context of each query.
This approach is particularly critical in RAG systems, where static access controls often fail to account for the nuanced interplay between user intent, data sensitivity, and query parameters.
By integrating contextual factors—such as the time of access, user behavior patterns, and the semantic nature of the query—CBAC ensures that data exposure is minimized without compromising functionality.
One of the most innovative implementations of CBAC involves semantic query analysis.
This technique evaluates the intent and sensitivity of a query in real-time, adjusting access permissions accordingly.
For instance, a healthcare RAG system might allow physicians to retrieve anonymized patient data for research purposes but restrict access to identifiable information unless explicitly authorized.
This granular control enhances security and aligns with stringent compliance requirements like GDPR.
However, CBAC is not without challenges. Its effectiveness hinges on robust contextual inference algorithms, which must accurately interpret user intent and query semantics.
Misclassifications can lead to either over-restriction, hampering usability, or under-restriction, increasing exposure risks.
Addressing these issues requires continuous refinement of machine learning models and integration with anomaly detection systems to flag suspicious access patterns.
By embedding CBAC into RAG architectures, organizations can balance operational efficiency and uncompromising data privacy, setting a new standard for secure AI-driven systems.
Secure Multi-Party Computation in RAG Systems
Secure Multi-Party Computation (SMPC) transforms how sensitive data is handled in RAG systems by enabling collaborative computations without exposing raw data.
At its core, SMPC ensures that no single party has access to the complete dataset, which is particularly vital in sectors like healthcare and finance, where privacy breaches can have severe consequences.
The underlying mechanism involves splitting data into encrypted shares distributed across multiple nodes. Each node processes its share independently, combining the results to produce the final output.
This approach eliminates the need for centralized data storage, significantly reducing the risk of unauthorized access.
However, optimizing the trade-off between computational overhead and system performance is the real challenge. For instance, poorly designed SMPC protocols can introduce latency, undermining the real-time capabilities of RAG systems.
Despite its promise, SMPC faces limitations in scalability and resource-constrained environments.
Addressing these requires innovative frameworks that balance security with efficiency, paving the way for broader adoption in privacy-critical applications.
FAQ
What are the key principles for optimizing RAG systems to handle sensitive data securely?
Secure RAG systems require encryption at rest and in transit, data minimization, and privacy-by-design. Contextual access controls and federated methods reduce exposure. Regular audits and monitoring help align data handling with privacy laws.
How can privacy compliance frameworks like GDPR and HIPAA be integrated into RAG system architectures?
Compliance frameworks are integrated by embedding policy enforcement, metadata tagging, and data lineage tracking. Access controls, encryption, and real-time audit logs ensure that data usage stays within legal boundaries and can be verified.
What advanced techniques ensure data minimization and anonymization in RAG systems?
Techniques include k-anonymity, differential privacy, pseudonymization, and query-aware filtering. These methods restrict access to non-essential data, mask identifiers, and prevent re-identification, supporting compliance while maintaining retrieval quality.
How do federated learning and differential privacy enhance the security of sensitive data in RAG systems?
Federated learning keeps data local, avoiding central transfer. Differential privacy introduces noise to outputs, hiding individual records. Together, they limit exposure and support secure, distributed learning within legal privacy constraints.
What role do zero-trust architectures and contextual encryption play in achieving privacy compliance for RAG systems?
Zero-trust models verify identity at each step. Contextual encryption changes protection levels based on query type and data sensitivity. These approaches restrict unauthorized access and align retrieval workflows with privacy compliance.
Conclusion
Optimizing RAG systems for sensitive data and privacy compliance means treating privacy as part of the architecture, not an afterthought.
From federated learning to contextual encryption, each layer must support data control, legal compliance, and operational clarity. As industries depend more on real-time AI systems, building privacy into the core of RAG frameworks is essential.