
Optimizing Retrieval Accuracy: Query Instructions vs Semantic Purity
Query instructions and semantic purity both impact RAG retrieval performance. This guide explores their strengths, trade-offs, and use cases to help you choose the best approach for improving accuracy, contextual relevance, and system effectiveness.


You ask a system to find “jaguar”—and it returns a car, not the animal you meant.
It’s a small mistake, but in critical domains like healthcare or law, that kind of confusion can’t happen.
This is the core tension in optimizing retrieval accuracy: query instructions vs semantic purity.
Should we trust the user’s explicit instructions or the model’s interpretation of what they meant?
It turns out, relying purely on semantic depth without guidance can cause search systems to miss the mark—especially when the query includes ambiguous or domain-specific terms.
This article explores why neither approach works well in isolation, and how a hybrid of the two—anchored instructions paired with smart semantic interpretation—can bring us closer to accurate, reliable retrieval.
Defining Retrieval Accuracy
Retrieval accuracy hinges on the system’s ability to align user intent with the most relevant results, a task that demands more than surface-level keyword matching.
At its core, it involves a dynamic interplay between explicit query parameters and the nuanced interpretation of semantic content.
This balance is particularly critical in domains where precision is paramount, such as legal or medical information retrieval.
One advanced technique is contextual word sense disambiguation (WSD), which identifies the intended meaning of ambiguous terms based on their surrounding context.
Unlike traditional keyword-based methods, WSD leverages grammatical dependencies and phrase structures to infer meaning. However, its effectiveness can vary significantly depending on the domain-specific training data and the complexity of the query.
A notable limitation of WSD is its reliance on high-quality annotated datasets, which are often scarce in specialized fields.
To address this, hybrid approaches combining WSD with ontology-based indexing have emerged, offering a structured framework for mapping queries to domain-specific concepts.
This synthesis underscores the importance of tailoring retrieval systems to the unique demands of their application contexts.
The Role of Query Instructions and Semantic Purity
Balancing query instructions with semantic purity is a nuanced challenge that directly impacts retrieval accuracy.
Query instructions act as a structural framework, ensuring precision by anchoring searches to explicit user intent.
However, semantic purity introduces interpretive depth, enabling systems to uncover latent connections within data. The interplay between these elements defines the effectiveness of modern retrieval systems.
One critical technique is integrating conceptual query languages with semantic models.
Conceptual languages, such as those based on Object-Role Modeling (ORM), allow queries to be formulated at a higher abstraction level, reducing ambiguity.
These systems can dynamically adapt to user intent when paired with semantic embeddings while maintaining contextual relevance.
This hybrid approach minimizes strict query instructions' rigidity without sacrificing semantic models' interpretive power.
A notable limitation arises in edge cases where overly abstract queries lead to semantic drift, diluting relevance.
Addressing this requires iterative refinement, where user feedback fine-tunes the balance. By leveraging hybrid methodologies, retrieval systems can achieve a harmony that elevates both precision and depth.
Foundational Concepts in Information Retrieval
The evolution of information retrieval (IR) systems has been shaped by a fundamental tension: the need to balance precision with interpretive depth.
Early systems relied heavily on Boolean logic, which retrieved documents based on exact keyword matches.
While effective for structured queries, this approach often failed to capture the subtleties of user intent, particularly in cases involving ambiguous or polysemous terms.
A significant leap occurred by introducing vector space models, which represented documents and queries as weighted term vectors.
This innovation allowed systems to calculate the cosine similarity between vectors, enabling a more nuanced results ranking.
However, these models still struggled with semantic understanding, as they treated terms as independent entities without considering their contextual relationships.
The advent of ontology-based indexing marked a paradigm shift.
By mapping documents to structured knowledge representations, such as RDF schemas, retrieval systems could infer relationships between concepts rather than relying solely on surface-level text.
For instance, an ontology system might recognize that “cardiology” is a subset of “medicine,” enhancing retrieval accuracy for domain-specific queries.
Ultimately, the interplay between foundational techniques—Boolean logic, vector models, and ontologies—provides the scaffolding for modern IR systems.
By understanding these building blocks, researchers and practitioners can better navigate the complexities of optimizing retrieval accuracy.
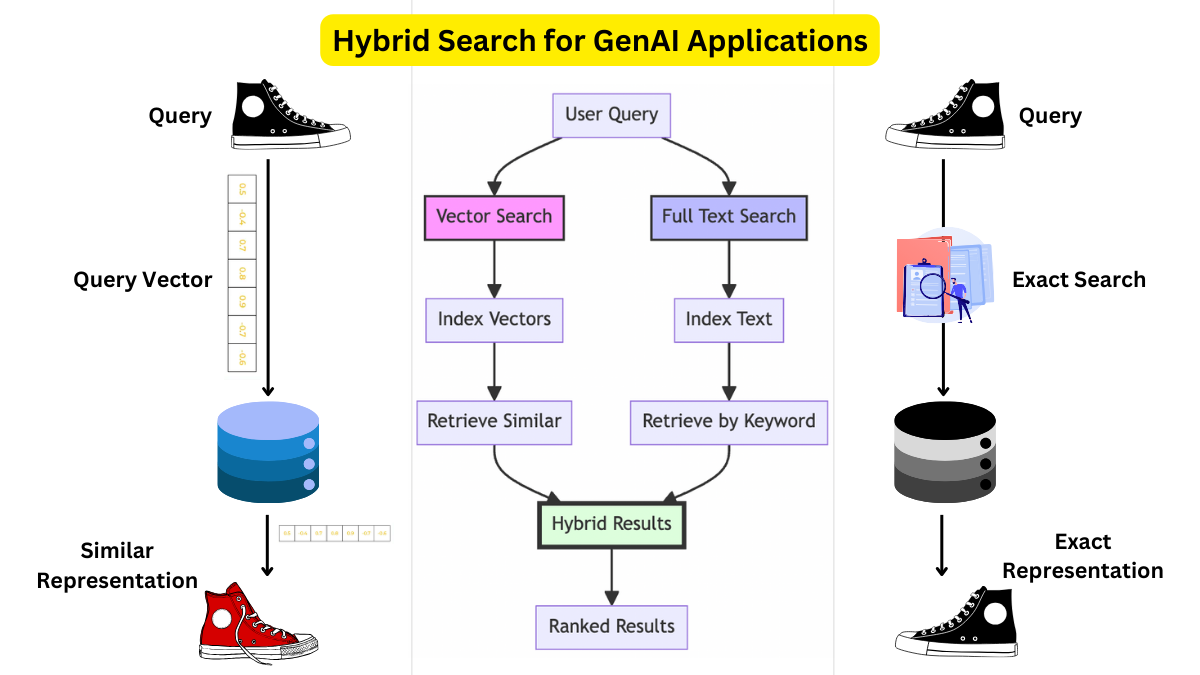
Traditional Keyword-Based Search
Keyword-based search thrives on its simplicity and precision, offering a direct pathway to relevant results by matching exact terms within a dataset.
This approach is particularly effective in environments where clarity and speed are paramount, such as legal document retrieval or technical troubleshooting.
By focusing solely on explicit terms, it eliminates the interpretive ambiguity often associated with semantic models, ensuring that users receive results aligned with their specific queries.
The underlying mechanism relies on Boolean logic and exact string matching, prioritizing query processing transparency.
Unlike semantic systems that infer intent, keyword-based search operates on a deterministic framework, making predicting and controlling outcomes easier.
However, this rigidity can also be a limitation, as it struggles with synonyms, misspellings, or nuanced phrasing.
A notable example is the use of keyword search in compliance audits. Organizations like Deloitte leverage this method to quickly locate regulatory terms within vast document repositories, ensuring adherence to legal standards.
While efficient, such systems require meticulous query formulation to avoid overlooking critical information.
Ultimately, its strength lies in its predictability, making it indispensable for tasks demanding unambiguous results.
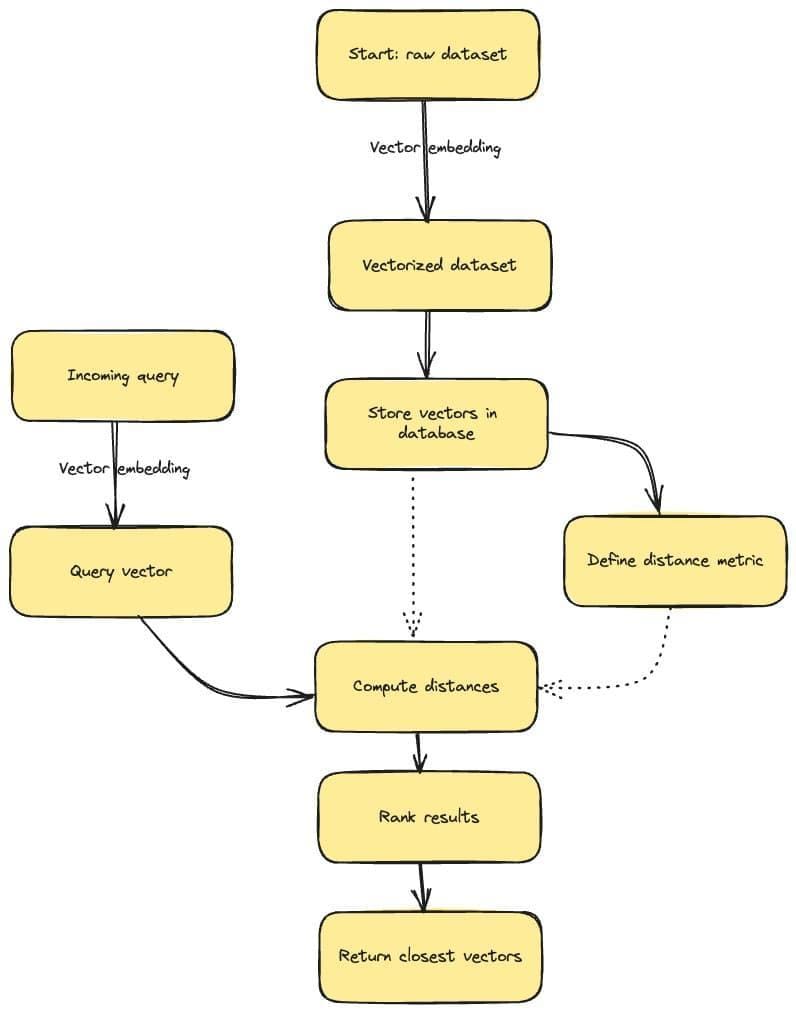
Introduction to Vector Embeddings
Vector embeddings revolutionize information retrieval by encoding semantic relationships into high-dimensional spaces, enabling systems to interpret meaning beyond surface-level text.
At their core, embeddings transform words, phrases, or entire documents into numerical vectors, where proximity in the vector space reflects semantic similarity.
This mechanism allows retrieval systems to bridge gaps in user intent, capturing nuances that traditional keyword-based methods often miss.
A critical aspect of embedding effectiveness lies in fine-tuning.
While pre-trained models like GloVe or Word2Vec provide a strong foundation, domain-specific adjustments significantly enhance performance.
For instance, embedding models tailored to legal or medical corpora can better capture these fields' intricate terminology and contextual dependencies.
This customization ensures that embeddings align with the application's specific needs, improving precision and recall.
However, embeddings are not without challenges.
The “curse of dimensionality” can dilute relevance in high-dimensional spaces, particularly for sparse datasets.
Addressing this requires careful dimensionality reduction techniques, such as Principal Component Analysis (PCA), to maintain meaningful relationships while optimizing computational efficiency.
By integrating these strategies, vector embeddings become indispensable tools for modern retrieval systems.
Balancing Query Instructions and Semantic Purity
The tension between query instructions and semantic purity is not a binary conflict but a dynamic interplay that shapes retrieval accuracy.
Explicit query instructions act as a compass, guiding systems to align with user intent.
However, semantic purity, which delves into the latent connections within data, ensures that retrieval systems capture the depth of meaning often absent in rigidly structured queries.
Bbalancing these paradigms is not merely a technical challenge but a strategic necessity for domains demanding both precision and interpretive depth.
Understanding Query Instructions
Query instructions are the foundation for aligning user intent with retrieval systems, yet their true power lies in their adaptability.
A well-crafted instruction directs the system and evolves through iterative refinement, ensuring precision in dynamic contexts.
This adaptability is particularly critical in domains like legal research, where even minor ambiguities can lead to significant misinterpretations.
One advanced technique is dynamic query expansion, which adjusts instructions based on real-time feedback.
The system refines its understanding of intent by incorporating user interactions, such as relevance judgments.
However, challenges arise in balancing specificity with flexibility. Overly rigid instructions may stifle the system’s ability to explore latent connections, while excessive abstraction risks semantic drift.
Addressing this requires a hybrid approach, combining explicit parameters with contextual embeddings to maintain precision and depth.
Ultimately, query instructions are not static directives but dynamic tools, capable of transforming retrieval systems into adaptive, user-centric solutions. This nuanced interplay between structure and flexibility defines their real-world effectiveness.
Exploring Semantic Purity
Semantic purity, at its core, emphasizes preserving the intrinsic meaning of relationships within data while avoiding distortions caused by overgeneralization.
This concept becomes particularly significant in systems that rely on structured knowledge bases, where the balance between explicit relational mappings and inferred semantic depth directly impacts retrieval accuracy.
One advanced approach to maintaining semantic purity is the relational purity score, which evaluates how well explicit relationships in a knowledge base align with the implicit semantics derived from corpus-based embeddings.
For instance, analogy queries—such as identifying relationships between entities—benefit from high relational purity, as they rely on precise yet flexible mappings.
However, challenges arise when applying this to heterogeneous datasets. Systems trained on general corpora often misinterpret domain-specific relationships, leading to reduced precision.
Addressing this requires domain-adaptive embeddings that align with the relational purity framework, ensuring contextual relevance.
By integrating relational purity metrics into retrieval pipelines, practitioners can fine-tune systems to balance interpretive depth with structural fidelity, enhancing both precision and adaptability.
Advanced Retrieval Algorithms and Techniques
Hybrid retrieval systems, which combine traditional keyword-based methods with semantic embeddings, have emerged as a cornerstone of modern information retrieval.
By integrating these approaches, systems can simultaneously preserve the precision of explicit query instructions while uncovering latent semantic relationships.
A key innovation within these systems is dynamic reranking algorithms, which adjust result prioritization based on real-time user interactions.
Unlike static ranking methods, these algorithms continuously leverage feedback loops to refine relevance.
For example, Amazon’s search engine employs reranking to adapt product recommendations based on click-through rates, ensuring alignment with evolving user preferences.
However, a common misconception is that semantic embeddings alone can resolve ambiguity.
In reality, embeddings often misinterpret domain-specific terms without tailored training datasets.
Addressing this, organizations like OpenAI have developed domain-adaptive models that align embeddings with specialized corpora, enhancing both precision and recall.
This interplay between hybrid retrieval and adaptive ranking underscores a pivotal insight: retrieval accuracy thrives on systems that balance interpretive depth with user-centric adaptability.
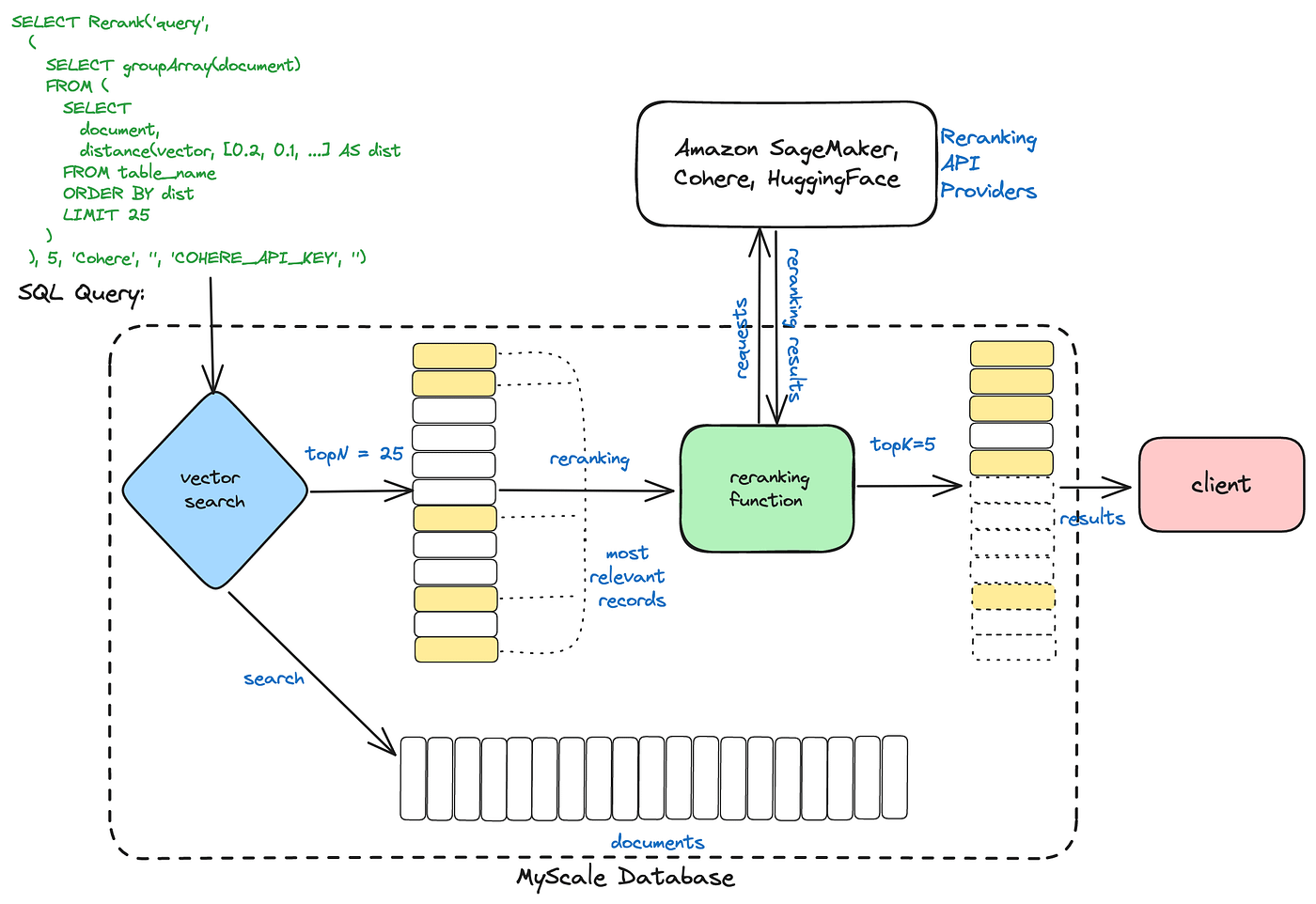
Hybrid Search Strategies
Hybrid search strategies excel by leveraging the complementary strengths of keyword-based retrieval and semantic embeddings, but their true power lies in integrating dynamic reranking mechanisms.
This approach ensures that results are relevant and contextually aligned with user intent, adapting in real-time to evolving queries.
This strategy's core is the reranking layer, which recalibrates initial search outputs by assigning relevance scores based on semantic alignment.
Unlike static ranking, this iterative process refines results dynamically, enabling systems to prioritize nuanced connections that might be overlooked.
For instance, Azure AI’s hybrid retrieval and reranking experiments demonstrated significant improvements in document recall relevance, particularly in multilingual and multimodal contexts.
A critical nuance often overlooked is the interplay between query specificity and semantic flexibility.
Overly rigid instructions can stifle the system’s ability to uncover latent relationships, while excessive abstraction risks semantic drift.
The solution lies in iterative query expansion, where user feedback fine-tunes the balance.
This iterative refinement is particularly effective in domains like clinical research. Ngo et al.’s deep learning-based semantic search system achieved notable precision by aligning queries with large-scale ontologies.
By embedding reranking into hybrid search workflows, organizations can achieve a seamless fusion of precision and depth, transforming retrieval systems into adaptive, user-centric solutions.
This iterative approach enhances accuracy and ensures scalability across diverse application domains.
Sophisticated Ranking Algorithms
Sophisticated ranking algorithms thrive on their ability to dynamically adapt to the interplay between explicit query instructions and semantic inference.
One particularly impactful technique is context-aware reranking, which recalibrates initial search results by integrating user behavior signals with semantic embeddings.
This approach ensures that the system aligns with the user’s immediate intent and anticipates latent needs based on contextual patterns.
The underlying mechanism involves a multi-layered architecture where explicit query parameters guide the initial retrieval phase, while a secondary reranking layer refines results using semantic proximity and behavioral data.
For example, systems like those employed by Google Scholar leverage citation networks and user interaction data to prioritize academically relevant results, demonstrating the power of combining structured and unstructured signals.
However, the effectiveness of these algorithms is highly context-dependent. In domains like healthcare, where precision is critical, over-reliance on semantic embeddings can lead to misinterpretation of specialized terminology.
Conversely, rigid adherence to explicit instructions may overlook nuanced relationships. Addressing this requires domain-specific tuning, such as incorporating ontologies or knowledge graphs tailored to the field.
A novel contribution to this field is the concept of adaptive ranking thresholds, which dynamically adjust the weight of semantic versus explicit signals based on query complexity.
This framework enhances retrieval accuracy and provides a scalable solution for diverse application contexts, from legal research to e-commerce.
By embracing such innovations, ranking algorithms can achieve a precise and intuitive balance.
FAQ
What is the difference between query instructions and semantic purity in optimizing retrieval accuracy?
Query instructions define explicit user intent using structured inputs. Semantic purity focuses on inferred meaning from data. Together, they balance precision and depth, improving retrieval accuracy by guiding systems to interpret queries more reliably.
How do entity relationships and salience analysis support accurate information retrieval?
Entity relationships define clear connections between concepts, while salience analysis identifies the most important terms. Together, they help retrieval systems stay focused on user intent, improving accuracy in queries with complex or domain-specific language.
How does co-occurrence optimization improve complex query retrieval?
Co-occurrence optimization examines how often and how closely terms appear together. This helps uncover hidden relationships between terms, improving systems' handling of complex or ambiguous queries in structured or technical datasets.
How do hybrid systems reduce semantic drift when combining query instructions and semantic embeddings?
Hybrid systems combine structured inputs with semantic models to avoid drift. Query instructions anchor intent, while salience and co-occurrence refine results. This keeps retrieval aligned with meaning without losing precision, especially in complex domains.
What are best practices for using domain-specific ontologies in retrieval accuracy?
Use expert-built ontologies that reflect the structure of a field. Align them with semantic models to ensure clarity and relevance. Regular updates and salience-based prioritization help improve accuracy in areas like legal, financial, or medical search.
Conclusion
Optimizing retrieval accuracy depends on the right balance between query instructions and semantic purity.
Structured inputs keep results precise, while semantic models uncover deeper meaning. By combining both with tools like entity relationships, salience, and co-occurrence analysis, retrieval systems become more reliable, especially in fields that demand both clarity and context.