
Building a RAG-Based Chatbot with Memory: A Guide to History-Aware Retrieval
This guide explores building a RAG-based chatbot with memory, enabling history-aware retrieval for improved contextual responses. Learn key techniques, architectures, and best practices to enhance chatbot interactions with better recall and relevance.


Imagine a chatbot remembering every detail of your last conversation—what you asked, how you phrased it, even the follow-up questions you didn’t get around to asking.
Sounds futuristic, right?
Well, that’s where history-aware retrieval comes in, and it’s about to change everything you thought you knew about conversational AI.
Why does this matter now? Because in a world where users expect seamless, human-like interactions, memory isn’t a luxury; it’s a necessity.
But the dilemma is: how do you build a chatbot that doesn’t just retrieve information but also remembers context like a human? That’s what we’re going to discuss in this article.
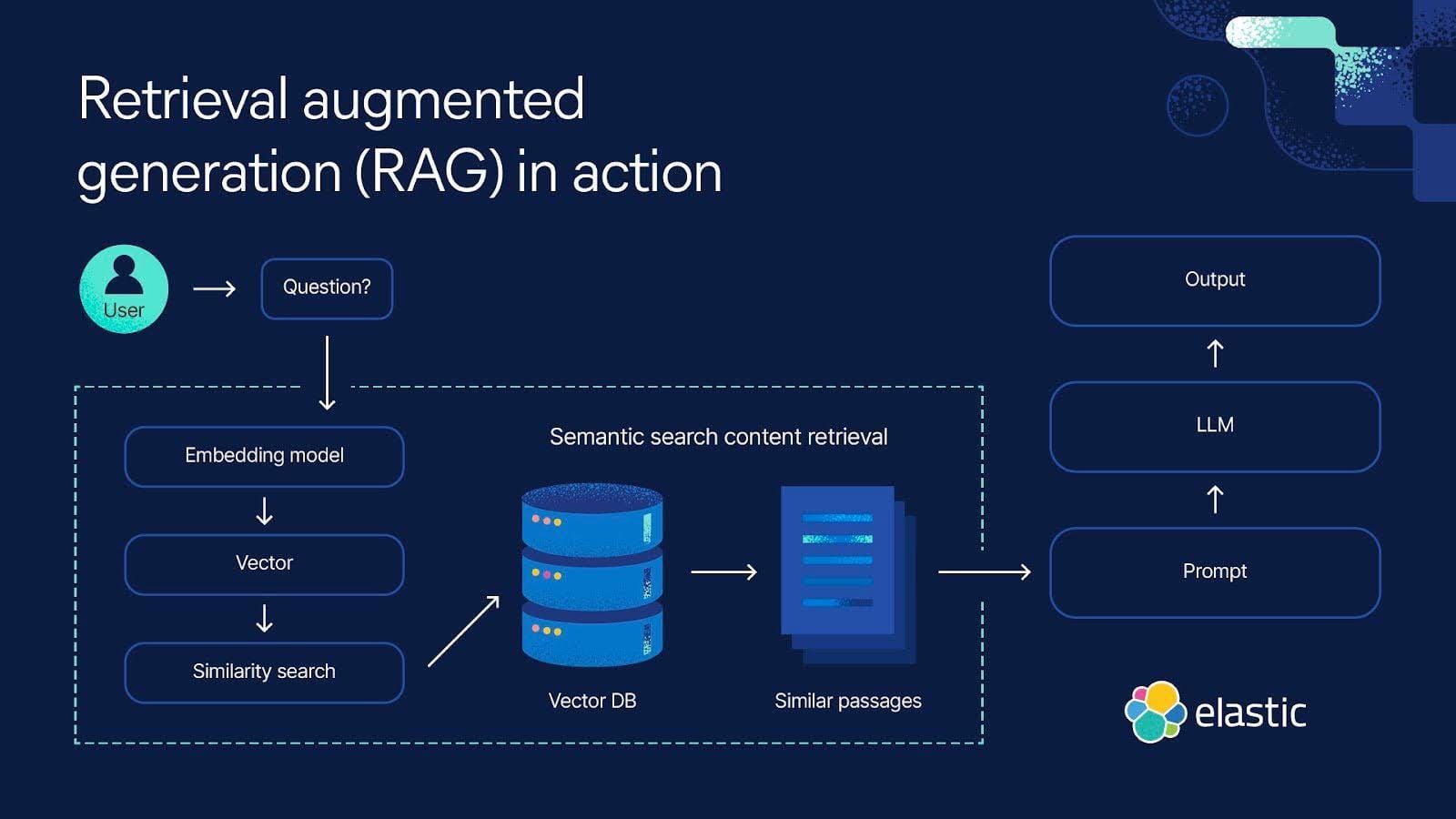
Integrating Memory into Chatbots
Think of chatbot memory like a personal assistant jotting down key details during a conversation.
It’s not just about remembering—it’s about remembering the right things.
For instance, a customer support chatbot that recalls a user’s previous complaint about a delayed shipment can proactively address it in follow-up interactions. This creates a seamless, human-like experience.
There’s just one roadblock, though. Memory isn’t infinite.
Storing every interaction bloats the system and slows performance. That’s why prioritization techniques—like summarizing past exchanges or tagging critical data points—are game-changers.
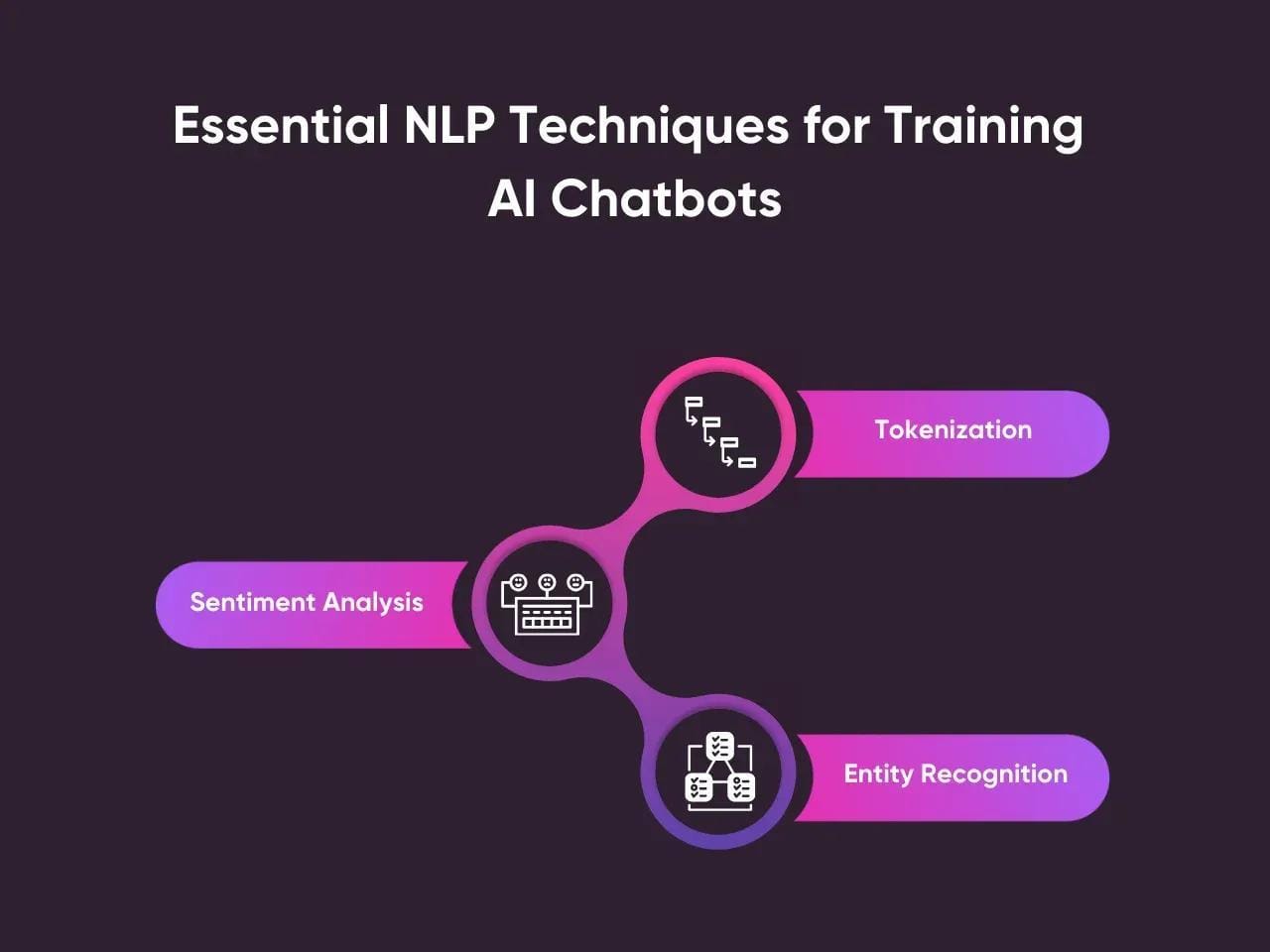
Techniques for Implementing Memory
One standout technique for implementing memory in chatbots is contextual chunking.
This method breaks conversations into manageable segments, allowing the bot to focus on the most relevant parts of a dialogue.
Why does this work?
It mirrors how humans process information—by grouping related details together, we avoid cognitive overload. For chatbots, this means faster retrieval and more accurate responses.
Take customer support as an example. A bot using contextual chunking can recall a user’s issue from earlier in the chat without being bogged down by unrelated details.
By dynamically pruning less relevant chunks, bots can handle larger datasets without sacrificing performance.
Building the RAG-Based Chatbot with Memory
Building a RAG-based chatbot with memory is like designing a library reorganizing itself after every visitor.
The reason behind that is adaptive memory management. This form of management stores only the most relevant conversational snippets while discarding noise.
A common misconception is that more memory equals better performance. In reality, context overload can confuse the model, leading to irrelevant responses.
Techniques like conversation chunking—breaking interactions into manageable, semantically linked pieces—ensure the chatbot stays focused. This is especially useful in industries like healthcare, where precision is non-negotiable.
Setting Up the Development Environment
Your development environment is the foundation of your RAG chatbot.
A containerized setup using tools like Docker isn’t just a nice-to-have—it’s essential because it ensures consistency across development and production, eliminating the dreaded “it works on my machine” problem.
You must also use version control for data sources. Tools like DVC (Data Version Control) can track changes in your datasets, ensuring your retrieval system always accesses the latest information.
Finally, integrate monitoring tools like Prometheus-–these track system performance and flag bottlenecks before they spiral out of control.
Implementing the Retrieval Component
To implement the retrieval component, you must first understand vector search, the backbone of any RAG system.
Unlike keyword-based retrieval, vector search uses embeddings to match data semantically.
It ensures your chatbot understands intent, not just words. For example, an e-commerce chatbot can recommend “running shoes” even if the user searches for “jogging sneakers.” This semantic precision boosts relevance and user satisfaction.
Hierarchical indexing is priceless in this scenario. You can drastically reduce retrieval noise by organizing data into layers (e.g., by topic or time). A healthcare chatbot, for instance, can prioritize recent medical guidelines over outdated ones, ensuring accurate advice.
But don’t ignore retrieval noise reduction. Techniques like query filtering or metadata tagging can prevent irrelevant results from cluttering responses. Think of it as decluttering your chatbot’s brain.
Integrating knowledge graphs could further enhance retrieval by mapping relationships between data points, creating even richer, context-aware interactions.
Integrating the Generation Module
Output conditioning is a technique that ensures the generation module prioritizes retrieved data over “hallucinated” content.
Why is this critical? Because generative models, left unchecked, can fabricate details.
For instance, in healthcare, a chatbot must base its advice on retrieved medical records, not guesswork. Conditioning the output anchors responses in factual data, improving trust and accuracy.
Combining Retrieval and Generation with Memory
We need to talk about adaptive memory prioritization to feed only the most relevant historical data into the retrieval and generation pipeline.
Overloading the system with unnecessary context can dilute response accuracy. For example, in e-commerce, a chatbot retrieving a user’s entire purchase history might miss the most recent order, leading to irrelevant recommendations.
You keep interactions sharp and focused by ranking memory snippets based on recency and relevance.
Another underappreciated factor is retrieval latency. Faster retrieval improves user experience and enhances generation quality by reducing the risk of outdated or mismatched data. Techniques like vector database caching can significantly reduce retrieval times, especially in high-traffic scenarios.
Technical Implementation Details
Let’s break this down: building a RAG-based chatbot with memory starts with vector embeddings.
Think of these as the chatbot’s “mental map,” where every piece of data is encoded semantically.
For instance, instead of matching keywords, the system understands that “buying shoes” and “purchasing sneakers” are related. This semantic encoding is powered by tools like FAISS or Pinecone, which make retrieval both fast and precise.
Now, here’s where it gets tricky—context window limits. Large Language Models (LLMs) can only process so much at once.
To solve this, developers use summarization techniques to condense conversation history without losing meaning. Imagine summarizing a novel into a tweet—it’s that level of precision.
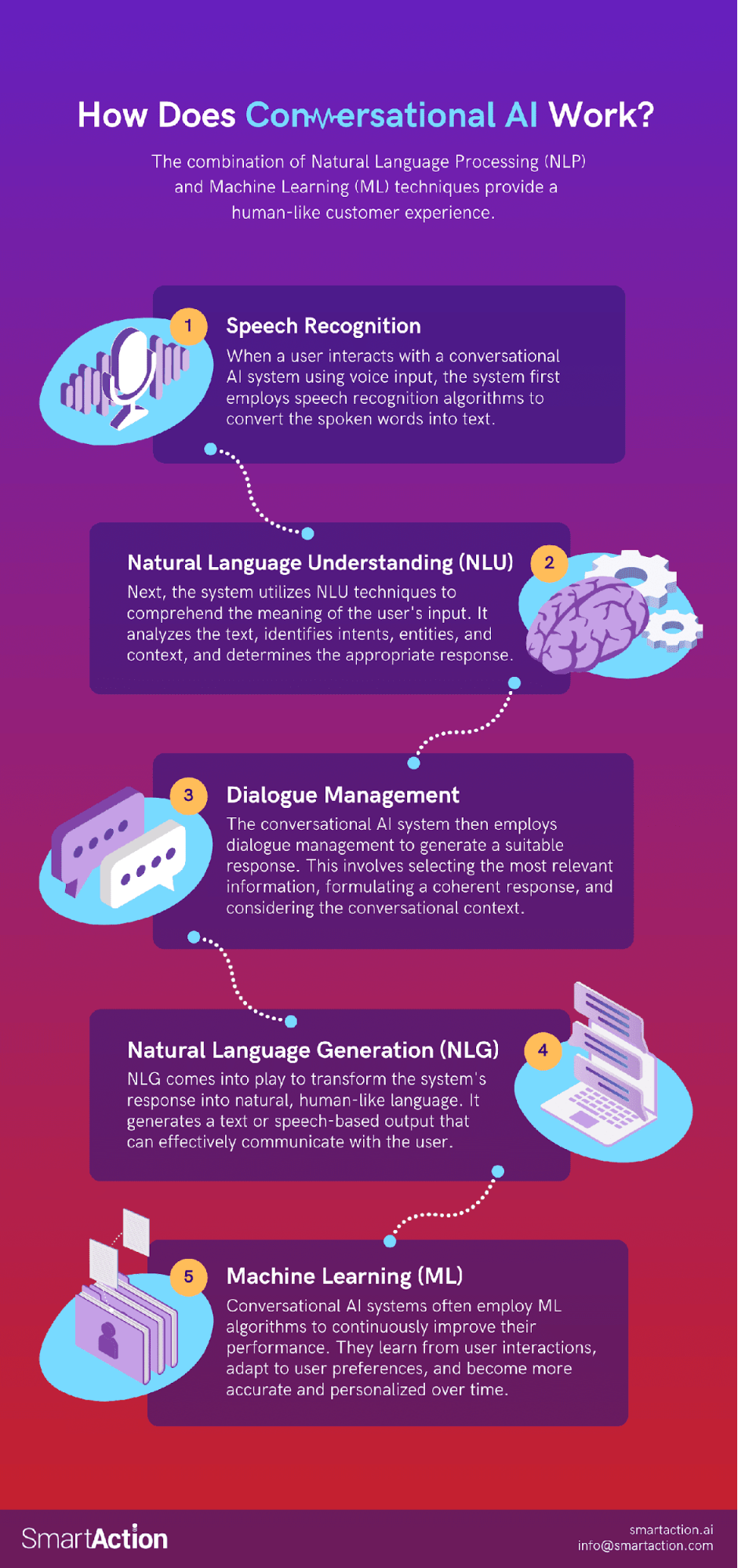
Choosing the Right Frameworks and Tools
Not all frameworks are created equal, and your choice can make or break your chatbot’s performance.
For retrieval systems, tools like Haystack shine because they seamlessly integrate vector databases (e.g., Weaviate) with LLMs, offering a plug-and-play experience.
But if you’re working with domain-specific data, LangChain allows for custom pipelines, giving you the flexibility to fine-tune retrieval and generation.
Here’s a pro tip: prioritize frameworks with active communities, because debugging is faster when thousands of developers have already solved your problem.
Handling Conversational Contexts
To ensure your chatbot doesn’t lose the thread of a conversation, multi-turn context tracking comes into play.
This approach works by maintaining a dynamic memory buffer that prioritizes recent exchanges while referencing long-term context when needed.
For instance, in healthcare, a chatbot can recall a patient’s symptoms from earlier in the session while pulling relevant medical history from prior visits.
Context pruning is essential to avoid overloading the system. By trimming irrelevant or redundant data, you keep the chatbot focused and responsive. Think of it like decluttering your inbox—only the most important emails stay visible.
Testing and Debugging Strategies
Edge case testing is a game-changer that ensures your chatbot handles the unexpected.
These are the quirky, ambiguous, or multi-intent queries that often trip up even the most advanced systems.
For example, a legal chatbot must distinguish between “filing a patent” and “patent infringement” without missing a beat. By stress-testing with such scenarios, you can uncover blind spots before users do.
Query paraphrasing can simulate diverse user inputs, exposing weaknesses in retrieval and generation. Tools like back-translation (e.g., English to French and back) expand your dataset, making the system more robust against linguistic variations.
And let’s not forget real-world simulation. You should deploy the chatbot in controlled environments—like internal teams—to gather actionable feedback. This iterative loop fine-tunes performance and builds confidence for large-scale deployment.
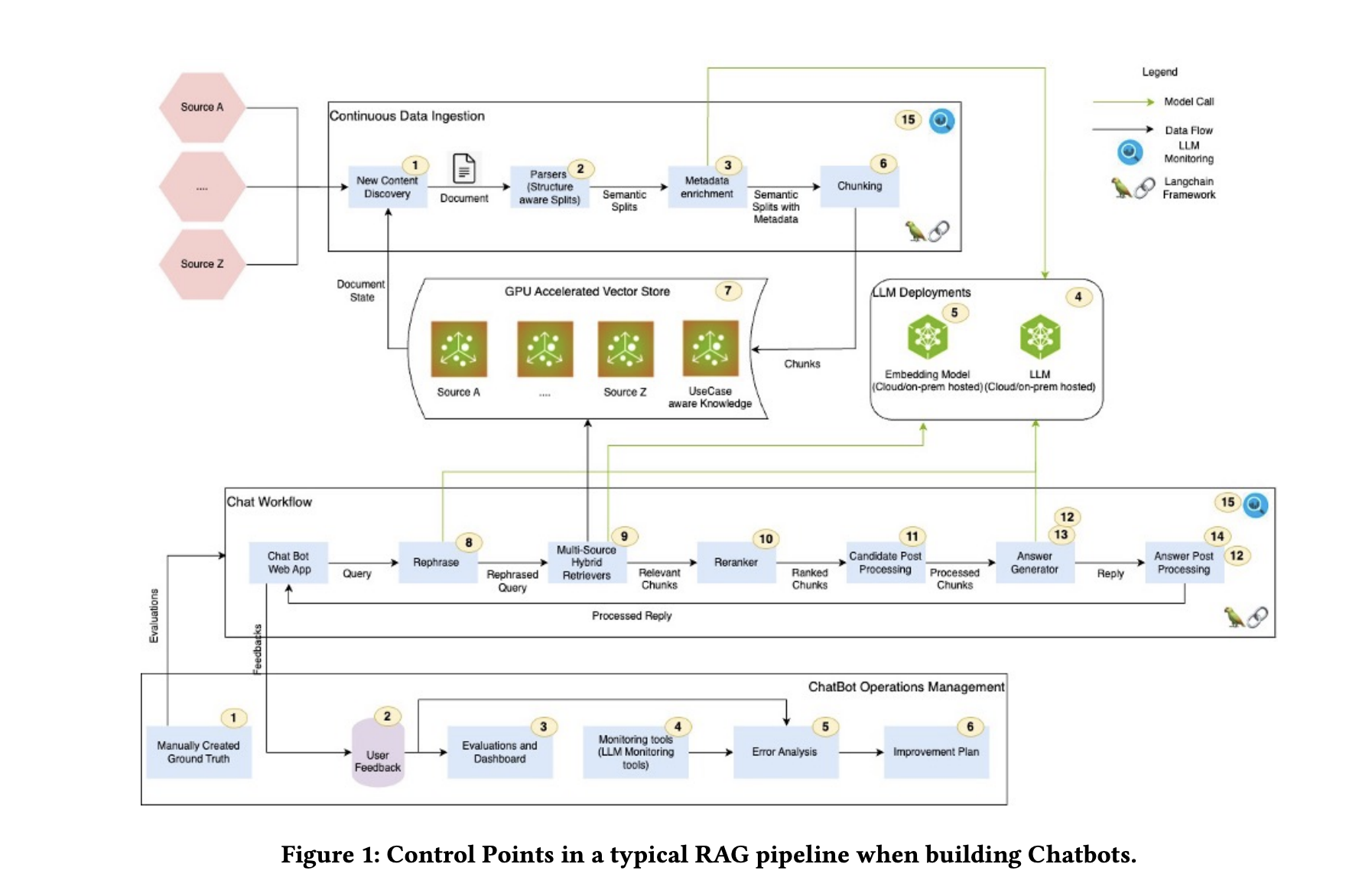
Optimizing Performance and Scalability
Scaling a RAG chatbot isn’t just about throwing more servers at the problem—it’s about working smarter, not harder.
Take adaptive batching. By grouping similar queries during peak loads, you can optimize GPU usage without sacrificing response times.
Dynamic retrieval scaling is also often overlooked.
This technique adjusts retrieval depth based on query complexity. Imagine zooming in for detailed questions and zooming out for broader ones. Galileo AI found this reduced latency by 25% while maintaining accuracy.
But here’s the kicker: predictive analytics. By anticipating traffic surges (e.g., Black Friday), you can pre-scale resources, avoiding bottlenecks entirely.
Combine this with caching strategies—like storing FAQs—and you’ve got a chatbot that’s not just fast but future-proof.
Measuring Success and KPIs
A critical yet overlooked KPI for RAG-based chatbots is contextual understanding accuracy.
Unlike generic accuracy metrics, this measures how well the chatbot retains and applies multi-turn context.
User effort score (UES) is another powerful metric. This evaluates how easy it is for users to achieve their goals. UES bridges the gap between efficiency and user satisfaction, making it indispensable for iterative improvements.
To implement, pair contextual accuracy tracking with user journey mapping. This dual approach not only highlights friction points but also informs retraining priorities.
FAQ
What are the key components required to build a RAG-based chatbot with memory?
The key components required to build a RAG-based chatbot with memory include:
- External knowledge sources
- A retrieval system (e.g., vector databases)
- A generative language model
- A memory management system
- Integration frameworks.
- Tools for data preprocessing and feedback mechanisms are also essential for accuracy and relevance.
How does history-aware retrieval enhance the performance of a RAG chatbot?
History-aware retrieval maintains context across multi-turn conversations, resolving ambiguities like pronoun references. It prioritizes relevant past interactions, reducing noise and improving response accuracy, especially in complex scenarios like healthcare or customer support.
What techniques can be used to manage and optimize conversational memory in chatbots?
Techniques include contextual chunking, summarization, context pruning, metadata tagging, and hierarchical memory management. These methods ensure efficient storage, retrieval, and relevance of conversational history while avoiding overload.
How do you ensure data relevance and accuracy in a RAG-based chatbot with memory?
Use semantic retrieval (vector databases), metadata enrichment, and real-time knowledge updates. Context-aware retrieval and human-in-the-loop supervision further refine accuracy, ensuring responses are grounded in relevant, up-to-date information.
What are the best practices for integrating retrieval and generation in a history-aware chatbot?
Best practices include retrieval-conditioned generation, dynamic query optimization, and retrieval noise reduction. Tight feedback loops, contextual memory integration, and domain-specific customization ensure seamless, accurate, and relevant responses.
Conclusion
Building a RAG-based chatbot with memory isn’t just about combining retrieval and generation—it’s about creating a system that feels human.
Think of it like hosting a dinner party: the retrieval system is your pantry, stocked with ingredients, while the generation model is the chef crafting a meal tailored to your guests’ tastes. Without the right ingredients—or worse, with expired ones—the meal falls flat.
Ultimately, a history-aware chatbot isn’t just a tool—it’s a partner in conversation, bridging the gap between static AI and dynamic human needs.