
Retrieval-Augmented Generation Challenges and Solutions
Explore the challenges of Retrieval-Augmented Generation (RAG) and discover practical solutions to overcome them.



A cutting-edge AI system confidently delivers an answer to your query, but the response is entirely wrong—not because the AI failed, but because the information simply didn’t exist in its knowledge base. This paradox lies at the heart of Retrieval-Augmented Generation (RAG), a technology designed to bridge the gap between static training data and dynamic, real-world information. Yet, as promising as RAG is, its implementation is riddled with challenges that can undermine its potential.
In an era where businesses rely on AI for real-time insights, the stakes couldn’t be higher. From scaling retrieval systems to ensuring the accuracy of generated content, the hurdles are as complex as they are critical. But what if the real issue isn’t just technical? What if the way we approach RAG itself needs rethinking?
This article unpacks these challenges, offering actionable solutions to unlock RAG’s transformative power.
Background and Motivation for Retrieval-Augmented Generation
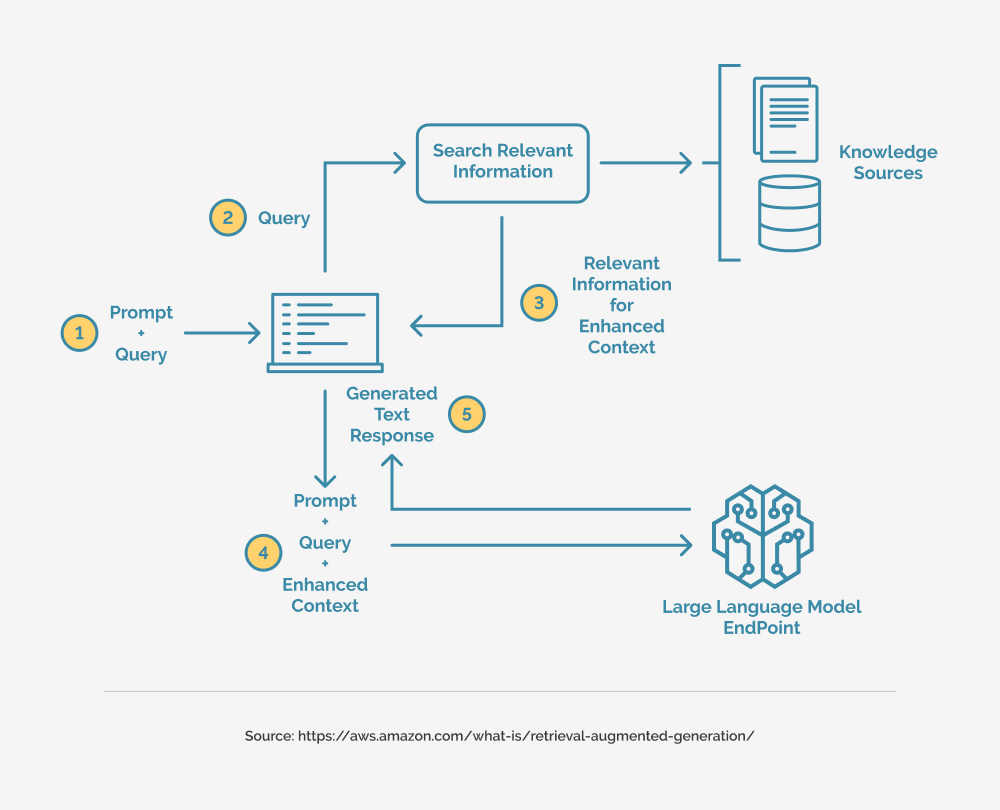
At its core, Retrieval-Augmented Generation (RAG) addresses a fundamental limitation of traditional AI models: their inability to adapt to rapidly changing information landscapes. Unlike static models that rely solely on pre-trained data, RAG dynamically integrates external knowledge, enabling real-time updates and contextually relevant outputs. This capability is particularly transformative in fields like healthcare, where retrieving the latest clinical guidelines can directly impact patient outcomes.
By leveraging external databases, RAG systems can bypass the need for exhaustive datasets, making them more efficient for niche or low-resource domains. For instance, legal research platforms use RAG to retrieve case law and statutes, synthesizing insights without requiring extensive retraining.
However, the success of RAG hinges on retrieval precision. Poorly curated knowledge bases or ambiguous queries can derail the system. To mitigate this, organizations should prioritize robust metadata tagging and domain-specific retrieval strategies, ensuring relevance and accuracy.
Limitations of Traditional Generative Models
A critical limitation of traditional generative models is their susceptibility to hallucinations—producing outputs that are plausible but factually incorrect. This stems from their reliance on static training data, which lacks real-time updates and domain-specific depth. For example, a model might confidently assert outdated medical advice, posing risks in high-stakes fields like healthcare.
These models often amplify biases present in their data, leading to skewed or incomplete outputs. In contrast, Retrieval-Augmented Generation (RAG) mitigates this by sourcing diverse, real-time information, reducing reliance on static, potentially biased datasets.
To address these issues, organizations should adopt hybrid approaches like RAG, which combine generative capabilities with retrieval systems. This ensures outputs are both fluent and grounded in factual data. Moving forward, integrating bias-detection algorithms and real-time validation mechanisms can further enhance the reliability of generative AI systems.
Purpose and Structure of the Article
A key focus of this article is to demystify the practical challenges of Retrieval-Augmented Generation (RAG) by breaking them into actionable insights. Unlike generic overviews, this approach emphasizes real-world applicability, such as improving retrieval quality through domain-specific indexing or reducing latency with optimized query pipelines.
The structure mirrors a problem-solving framework, where each challenge is paired with evidence-backed solutions. For instance, addressing scalability issues in RAG systems draws parallels to distributed computing in data engineering, showcasing how techniques like sharding and load balancing can enhance performance.
An often-overlooked aspect is the interplay between retrieval accuracy and user trust. Poorly retrieved data can erode confidence in AI systems, especially in sensitive fields like healthcare or finance. By integrating feedback loops and adaptive learning mechanisms, organizations can ensure continuous improvement.
This article aims to equip readers with a scalable framework to tackle RAG challenges, fostering innovation across industries.
Understanding Retrieval-Augmented Generation
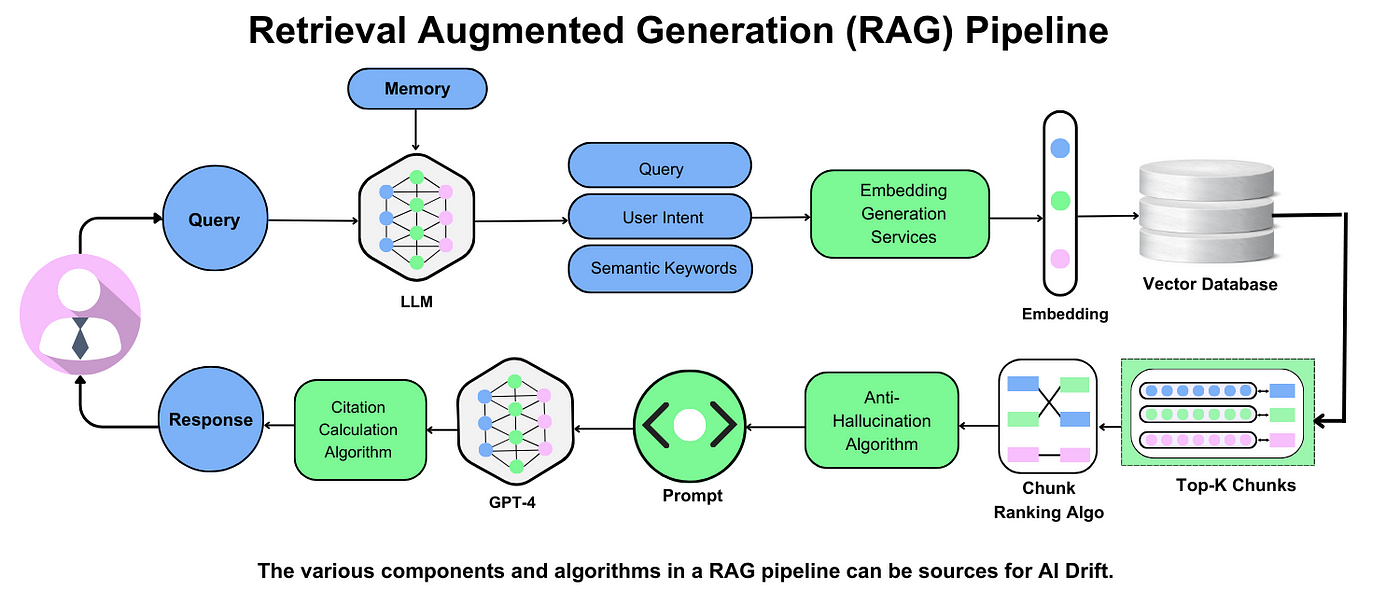
Retrieval-Augmented Generation (RAG) combines information retrieval systems with generative AI models, creating a hybrid approach that bridges static knowledge and real-time data. Think of it as a librarian and a storyteller working together: the librarian fetches the most relevant books, while the storyteller crafts a narrative tailored to your needs.
One standout example is healthcare chatbots. By retrieving the latest medical research, these systems provide accurate, up-to-date advice, unlike traditional models limited to outdated training data. This dynamic capability has proven critical during fast-evolving crises like pandemics.
A common misconception is that RAG simply “adds data” to generative models. In reality, its success hinges on retrieval precision and contextual alignment. Poorly matched data can lead to incoherent outputs, undermining user trust.
By integrating metadata tagging and semantic search algorithms, RAG systems ensure relevance and accuracy, setting a new standard for AI-driven solutions across industries.
Definition and Core Concepts of RAG
At its heart, Retrieval-Augmented Generation (RAG) thrives on dense vector representations to match queries with relevant data. Unlike keyword-based retrieval, dense vectors encode semantic meaning, enabling RAG to fetch contextually aligned information even when phrasing varies. This approach is pivotal in domains like legal research, where nuanced language can obscure critical precedents.
Systems that retrieve entire documents often overwhelm the generator with irrelevant data. Instead, passage-level retrieval—breaking content into smaller, focused chunks—yields more precise and coherent outputs. For instance, in customer support, retrieving a single FAQ snippet rather than an entire manual ensures faster, more accurate responses.
Retrieval is often viewed as purely technical, but human-in-the-loop feedback proves transformative. By iteratively refining retrieval models based on user corrections, organizations can enhance both accuracy and trust. This synergy between machine precision and human judgment is redefining RAG’s potential.
Theoretical Framework and Mechanisms
A critical mechanism in RAG is query-document alignment, where dense vector embeddings bridge the gap between user intent and retrieved data. This alignment leverages contrastive learning, a technique that trains models to distinguish relevant from irrelevant data points. By optimizing this process, RAG systems achieve higher precision, particularly in low-resource languages, where traditional retrieval methods falter.
Poorly retrieved data can cascade into incoherent outputs, but integrating adaptive retrieval mechanisms—where the generator’s output informs retrieval adjustments—mitigates this risk. For example, in real-time financial analysis, adaptive retrieval ensures that only the most relevant market data informs generated reports.
Retrieval and generation are often treated as distinct processes.However, emerging research suggests that joint optimization frameworks, where both components are trained simultaneously, yield superior results. This integrated approach could redefine RAG’s scalability and domain adaptability, paving the way for more robust applications.
Comparison with Other Augmented Models
A key distinction between RAG and knowledge-augmented models lies in their approach to external data. While RAG dynamically retrieves information in real-time, knowledge-augmented models rely on pre-embedded knowledge graphs. This static nature limits adaptability but excels in domains like supply chain optimization, where structured, unchanging data is paramount.
RAG’s on-the-fly retrieval offers flexibility but introduces latency challenges. In contrast, prompt-tuning models, which fine-tune responses based on pre-trained data, deliver faster outputs but struggle with domain-specific accuracy. For instance, in legal research, RAG can source up-to-date case law, whereas prompt-tuning models may miss recent rulings.
RAG’s retrieval-generation loop ensures responses align with user intent, unlike template-based systems, which often produce rigid outputs. By integrating adaptive retrieval mechanisms, RAG could further outperform static models, especially in dynamic fields like crisis management, where real-time accuracy is critical.
Core Challenges in RAG Systems
- Retrieval Quality and RelevanceImagine asking a librarian for a book on quantum physics and receiving a cookbook instead. That’s what happens when RAG systems retrieve irrelevant or outdated data. Studies show that retrieval precision drops by up to 30% in noisy datasets. To combat this, tools like knowledge graph augmentation and dynamic query re-weighting ensure the system focuses on contextually relevant information.
- Latency BottlenecksRAG’s real-time retrieval can feel like waiting for a slow elevator in a high-rise. As data grows, latency increases. For example, a large-scale deployment saw response times balloon by 50% without asynchronous retrieval or vector quantization. Solutions like distributed search engines (e.g., OpenSearch) reduce delays by parallelizing tasks.
- Scalability ConstraintsScaling RAG is like expanding a library while keeping every book instantly accessible. Without parallel ingestion pipelines, data ingestion times can triple. Enterprises like Netflix use ANN algorithms to handle billions of vectors efficiently.
- Integration ComplexityCombining retrieval and generation is akin to syncing a symphony orchestra. Misalignment leads to incoherent outputs. Modular architectures using containerized microservices (e.g., Docker) simplify scaling and maintenance.
- Dependency on Data QualityGarbage in, garbage out. If the knowledge base is biased or outdated, RAG amplifies these flaws. Regular updates and anomaly detection tools like Anomaly Transformer are essential to maintain trustworthiness.
Integrating Retrieval and Generation Components
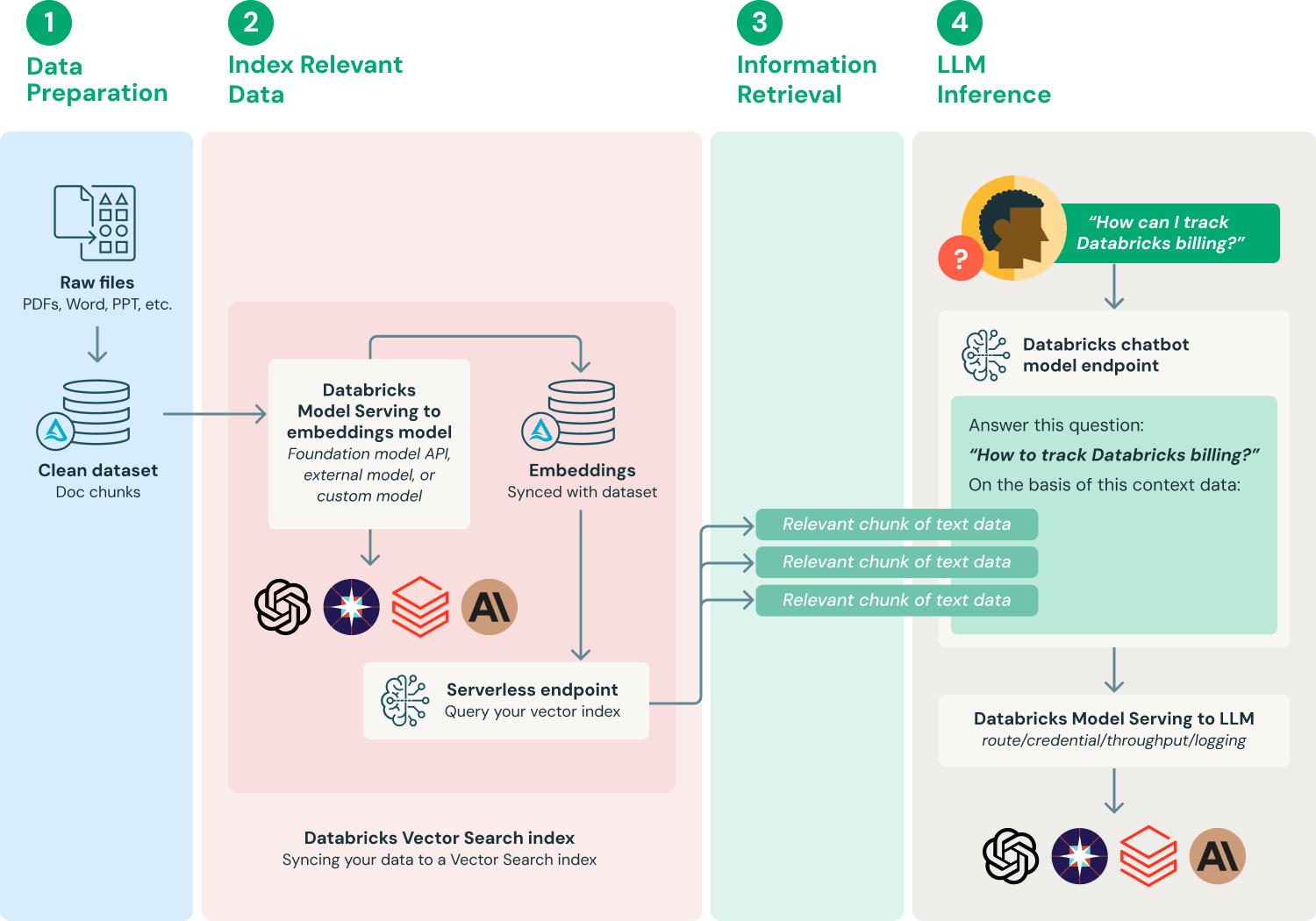
Misalignment often occurs when retrieved data lacks the granularity or specificity required by the generative model, leading to incoherent outputs. For instance, in customer support chatbots, generic retrieval results can produce vague or irrelevant responses, frustrating users.
A promising approach is query expansion with semantic embeddings, which refines retrieval queries to better match the generative model’s needs. For example, OpenAI’s GPT-based systems have demonstrated improved coherence by leveraging dense vector representations to align retrieval outputs with generative prompts. This ensures that retrieved data is not only relevant but also contextually rich.
Real-world applications, such as legal document summarization, benefit significantly from this alignment. By integrating domain-specific retrievers with fine-tuned generative models, firms can produce precise, actionable summaries.
Looking ahead, adaptive feedback loops—where generation informs retrieval—could redefine integration, enabling dynamic, task-specific optimization.
Scalability with Large-Scale Data
A pivotal challenge in scaling RAG systems lies in efficient indexing for high-dimensional data. Traditional indexing methods falter as datasets grow, leading to slower retrieval times and increased computational overhead. To address this, approximate nearest neighbor (ANN) algorithms, such as HNSW (Hierarchical Navigable Small World), have emerged as game-changers. These algorithms balance speed and accuracy by prioritizing proximity-based search over exhaustive comparisons.
For example, e-commerce platforms like Amazon use ANN-based indexing to retrieve product recommendations from massive catalogs in milliseconds. This approach not only accelerates retrieval but also reduces memory usage, making it viable for real-time applications.
However, scalability isn’t just about speed—it’s also about data consistency. Incremental indexing, where new data is seamlessly integrated without reprocessing the entire dataset, ensures up-to-date results without downtime.
Looking forward, combining distributed vector databases with modular RAG architectures could redefine scalability, enabling seamless expansion across industries.
Ensuring Relevance and Accuracy of Retrieved Information
By dynamically enriching user queries with semantically related terms, systems can retrieve more precise results. For instance, in legal applications, expanding “contract dispute” to include terms like “breach of agreement” or “arbitration” ensures retrieval aligns with nuanced user intent.
This approach works because it leverages knowledge graphs and ontologies to map relationships between concepts. Google’s search engine, for example, uses similar techniques to refine results for ambiguous queries, significantly improving user satisfaction.
However, relevance isn’t just about retrieval—it’s also about post-retrieval filtering. Techniques like re-ranking using transformer models (e.g., BERT) can prioritize the most contextually aligned documents, reducing noise.
To push boundaries, integrating domain-specific embeddings with real-time feedback loops could further refine accuracy, especially in fields like healthcare, where precision is non-negotiable. This creates a virtuous cycle of continuous improvement.
Latency and Performance Optimization
Unlike traditional synchronous methods, asynchronous retrieval allows multiple queries to be processed in parallel, significantly reducing wait times. This approach is particularly effective in real-time applications like chatbots, where even a 100ms delay can degrade user experience.
For example, OpenAI’s GPT-based systems have demonstrated improved throughput by combining asynchronous retrieval with vector quantization. By reducing the dimensionality of vector representations, similarity searches become faster without sacrificing accuracy. This technique is especially impactful in large-scale deployments, such as customer support platforms handling thousands of simultaneous queries.
Another game-changer is edge computing. By processing retrieval tasks closer to the user, latency caused by network delays is minimized. This is already being implemented in industries like autonomous vehicles, where split-second decisions rely on ultra-low latency.
Looking ahead, integrating predictive caching—preloading likely retrieval results based on user behavior—could further revolutionize performance, bridging the gap between speed and scalability.
Handling Noisy or Ambiguous Data Inputs
Contextual disambiguation through multi-hop retrieval iteratively retrieves and refines information by linking related data points across multiple documents, reducing ambiguity. For instance, in legal tech, multi-hop retrieval helps clarify vague queries by connecting statutes, case law, and precedents, ensuring precise outputs.
Another effective approach is noise filtering via attention mechanisms. Models like BERT use attention layers to prioritize relevant parts of input data, effectively ignoring irrelevant or misleading information. This is particularly useful in domains like healthcare, where noisy patient records can lead to incorrect diagnoses.
Interestingly, active learning frameworks can further enhance performance. By incorporating user feedback on ambiguous outputs, the system iteratively improves its understanding of noisy inputs. This bridges the gap between machine learning and human expertise, offering a scalable framework for tackling ambiguity.
Future advancements could integrate probabilistic reasoning models, enabling systems to quantify uncertainty and provide confidence scores for ambiguous queries.
Solutions to Address RAG Challenges
To tackle retrieval quality issues, consider implementing knowledge graph augmentation. By structuring data into interconnected nodes, retrieval systems can better understand relationships, improving relevance. For example, in e-commerce, a knowledge graph linking products, reviews, and user preferences can refine search results, boosting customer satisfaction.
Addressing latency bottlenecks requires asynchronous retrieval pipelines. These pipelines fetch data in parallel, reducing wait times.
For scalability, approximate nearest neighbor (ANN) algorithms shine. They efficiently handle vast datasets by prioritizing speed over exact matches. Spotify’s recommendation engine, for instance, uses ANN to process millions of tracks without compromising user experience.
Finally, human-in-the-loop systems mitigate errors in ambiguous queries. By integrating expert feedback, these systems iteratively improve. Think of it as a GPS recalibrating based on user input—dynamic, adaptive, and precise.
Advanced Retrieval Algorithms and Indexing Techniques
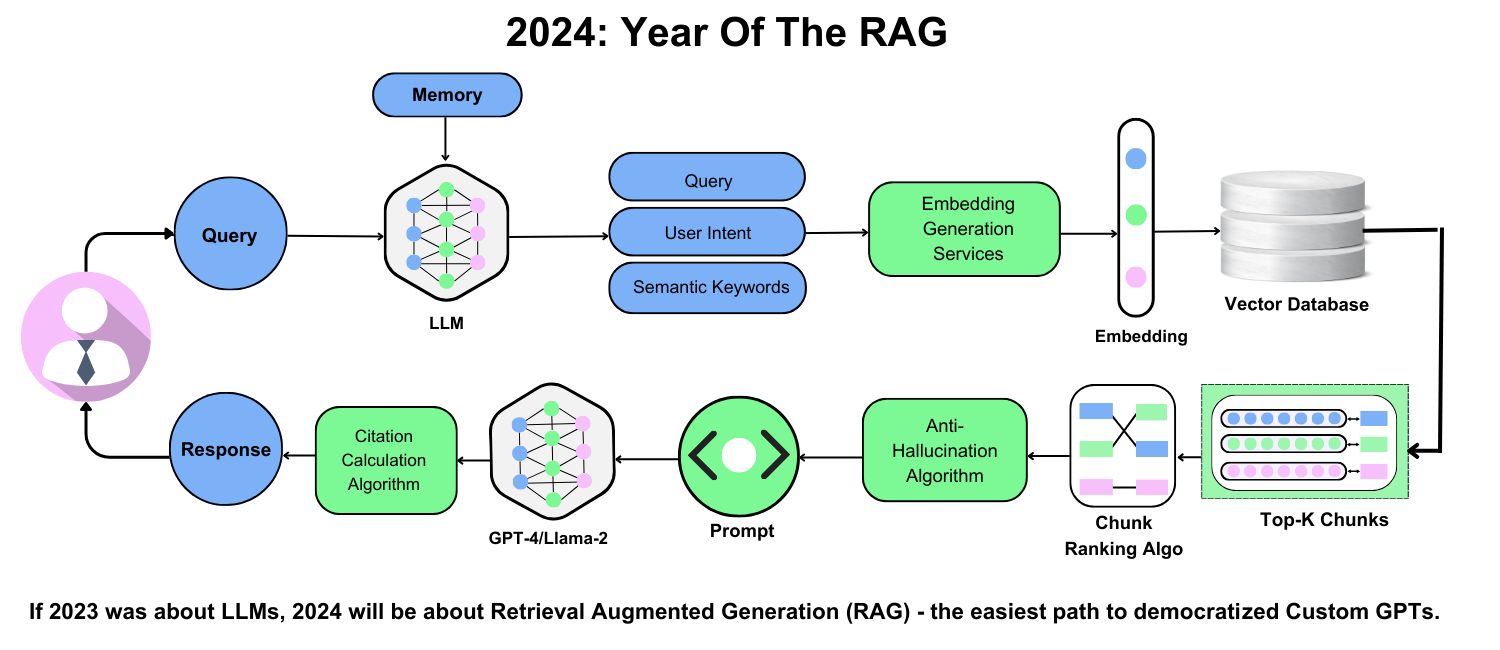
Recursive retrieval is a game-changer for refining search results in complex queries. By iteratively retrieving and re-ranking data, it hones in on the most relevant information. For instance, in legal research, recursive retrieval can narrow down case law by first identifying broad precedents, then refining results based on specific legal arguments.
Another breakthrough is hybrid indexing, which combines dense vector embeddings with sparse keyword-based methods. This dual approach balances precision and recall, excelling in diverse data environments. Google’s search engine leverages hybrid indexing to deliver both highly specific and contextually broad results, ensuring user satisfaction.
Splitting documents into appropriately sized chunks impacts retrieval accuracy. Overly large chunks dilute relevance, while overly small ones fragment context. Research in biomedical RAG systems shows that tuning chunk sizes improved retrieval precision by 25%, directly enhancing diagnostic support tools.
Looking ahead, these techniques promise even greater adaptability across domains.
Cross-Modal Retrieval Strategies
Multimodal embeddings are pivotal for aligning diverse data types like text, images, and audio. By mapping these modalities into a shared semantic space, systems can retrieve contextually relevant information across formats. For example, e-commerce platforms use multimodal embeddings to match product descriptions with user-uploaded images, enhancing search accuracy.
Text data often contains ambiguities, while images may suffer from poor resolution. Advanced denoising techniques, such as contrastive learning, have shown promise in mitigating these issues. In healthcare, this approach enables RAG systems to cross-reference medical images with textual case studies, improving diagnostic precision.
Treating modalities equally is common practice, but evidence shows that prioritizing specific modalities can boost performance.Assigning higher weights to dominant modalities—like text in legal contexts—yields better results. Future innovations should focus on adaptive weighting mechanisms, ensuring dynamic optimization for domain-specific needs.
Contextual Embeddings and Knowledge Graphs
Dynamic query-context alignment is a game-changer in leveraging contextual embeddings with knowledge graphs. By embedding queries and graph nodes into a shared vector space, systems can identify nuanced relationships, such as linking a legal query to precedents stored in a knowledge graph. This approach ensures precision by focusing on semantic relevance rather than surface-level keyword matches.
Dense, well-connected graphs outperform sparse ones by offering richer pathways for reasoning. For instance, in supply chain management, a knowledge graph linking suppliers, products, and logistics enables RAG systems to generate actionable insights, like identifying bottlenecks.
Incorporating time-aware embeddings allows systems to prioritize recent or contextually relevant data. Moving forward, integrating temporal reasoning with adaptive embeddings can unlock new possibilities in real-time decision-making across industries.
Adaptive Learning and Fine-Tuning Methods
Progressive fine-tuning is a standout approach for enhancing RAG systems, especially in domain-specific applications. By incrementally fine-tuning models on curated datasets, systems can adapt to niche requirements without overfitting. For example, in healthcare, fine-tuning on medical ontologies ensures accurate retrieval and generation of contextually relevant responses, such as treatment guidelines or diagnostic insights.
Over-specialization can limit adaptability, while excessive generalization risks losing domain precision. Techniques like multi-task learning, where models are trained on related tasks simultaneously, can mitigate this trade-off by preserving broader contextual understanding while honing domain-specific skills.
By prioritizing high-impact data points for retraining, active learning reduces computational overhead while improving performance. Future advancements could integrate real-time feedback loops, enabling RAG systems to evolve dynamically in response to user interactions.
Parallel Computing and Hardware Acceleration
Dynamic workload distribution is a pivotal aspect of parallel computing in RAG systems. By leveraging task parallelism, where retrieval and generation tasks are executed simultaneously across multiple GPUs or TPUs, systems can drastically reduce latency. For instance, NVIDIA’s CUDA framework enables efficient parallel processing, allowing RAG models to handle real-time queries in high-demand environments like financial trading or emergency response systems.
While raw computational power is often prioritized, bottlenecks frequently stem from insufficient memory throughput. Techniques like data sharding—splitting datasets across multiple nodes—can alleviate this, ensuring faster access to relevant information.
Emerging hardware, such as AI-specific accelerators (e.g., Google’s TPUs), challenges the reliance on traditional GPUs by offering optimized performance for matrix-heavy operations. Future frameworks should integrate hardware-aware optimization algorithms, enabling seamless scaling as data and user demands grow.
Implementation Strategies for RAG
To implement RAG effectively, start with modular design. Think of RAG as a two-part orchestra: the retriever and the generator. Each must perform independently yet harmonize seamlessly. For example, OpenAI’s GPT models paired with FAISS (Facebook AI Similarity Search) demonstrate how modularity allows for independent optimization of retrieval and generation components.
Domain-specific fine-tuning is another critical strategy. A healthcare chatbot, for instance, benefits from embedding medical ontologies into its retriever, ensuring outputs are both accurate and contextually relevant. This approach reduces the risk of irrelevant or misleading responses, a common pitfall in generic RAG systems.
Finally, feedback loops are your secret weapon. By integrating user feedback into retriever updates, systems like Google’s Search-augmented LLMs continuously refine their accuracy. Think of it as teaching a chef to adjust recipes based on diner preferences—iterative, precise, and impactful. These strategies ensure RAG systems remain robust, scalable, and user-centric.
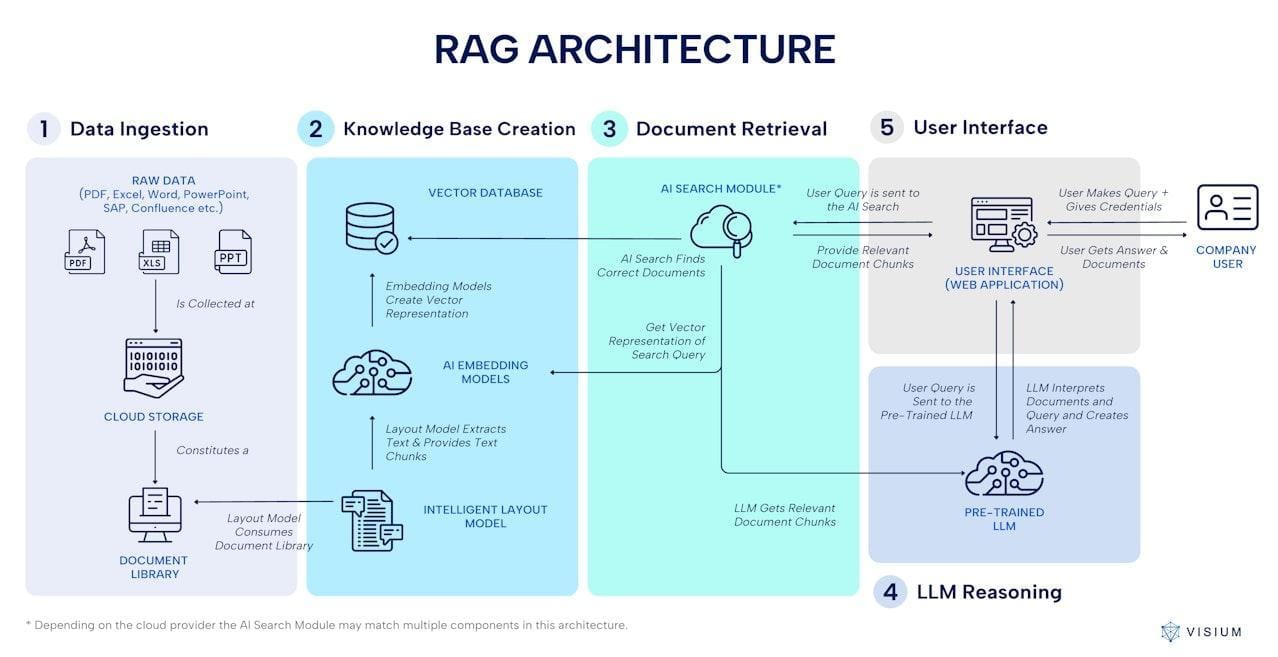
Architectural Design Patterns
One standout design pattern in RAG is hybrid retrieval, which combines dense vector embeddings with traditional keyword-based search. Dense embeddings excel at capturing semantic meaning, but they can miss domain-specific nuances. By layering keyword search on top, systems like Elasticsearch ensure precision for niche queries, such as legal or medical terms.
Another critical pattern is multi-stage ranking pipelines. An initial retriever narrows down candidates, and a reranker (often a transformer model) refines the results. This approach, used by Microsoft’s Turing-NLG, balances speed and accuracy, ensuring only the most relevant data reaches the generator.
Finally, adaptive chunking optimizes retrieval granularity. Instead of fixed document sizes, systems dynamically adjust chunk sizes based on query complexity. Think of it as zooming in or out on a map—broad overviews for general queries, detailed views for specific ones. These patterns unlock efficiency and relevance in RAG workflows.
Dataset Selection and Preprocessing
Static datasets often fail to reflect rapidly evolving domains like finance or healthcare. Incorporating time-stamped data filtering ensures that only the most current and contextually relevant information is retrieved. For example, in MedRAGBench, outdated medical guidelines were excluded to improve diagnostic accuracy.
Another powerful technique is domain-specific annotation. While general datasets provide breadth, they lack the depth required for niche applications. Annotating datasets with metadata such as source credibility, sentiment, or domain-specific tags (e.g., legal precedents) enhances retrieval precision. Tools like Stanza streamline this process by automating entity recognition and parsing.
Finally, data deduplication pipelines address redundancy, which can skew retrieval results. Deduplication tools like Dedup not only reduce noise but also improve system efficiency. These strategies, when combined, create a robust foundation for RAG systems, enabling them to adapt dynamically to real-world complexities.
Evaluation Metrics and Benchmarking Standards
An important metric in RAG evaluation is answer faithfulness, which measures how accurately generated outputs align with the retrieved context. Unlike traditional metrics like BLEU or ROUGE, faithfulness directly addresses the risk of hallucinations. For instance, Amazon Bedrock employs automated checks to ensure generated responses remain consistent with retrieved data, reducing misinformation in customer-facing applications.
Another innovative approach is human preference metrics, which capture subjective user satisfaction. These metrics, often gathered through A/B testing, provide insights into how well the system meets real-world expectations. For example, in open-domain question answering, user feedback on clarity and relevance can refine both retrieval and generation components.
Lastly, context entropy—a measure of information diversity—challenges the conventional focus on precision alone. By balancing entropy with relevance, systems can better handle ambiguous queries. These advanced metrics, when integrated, create a holistic framework for evaluating RAG systems, driving both technical and user-centric improvements.
Case Study: RAG in Conversational AI
Dynamic query expansion refines user inputs to improve retrieval accuracy. By leveraging semantic embeddings, systems like OpenAI’s ChatGPT with plugins can interpret vague or incomplete queries, expanding them with contextually relevant terms. This approach ensures that even ambiguous user inputs yield precise and meaningful responses, enhancing user satisfaction.
For example, in customer support, a query like “Why is my order delayed?” can dynamically expand to include terms like “shipping status” or “delivery issues,” retrieving more targeted information. This technique not only improves response relevance but also reduces latency by narrowing the search space.
By maintaining conversational history, RAG systems can generate responses that align with prior interactions, mimicking human-like dialogue. These innovations, when combined, create a framework for building conversational agents that are both context-aware and highly responsive, setting new benchmarks for user engagement.
Deployment Considerations and Best Practices
In industries like healthcare or finance, where sensitive data is involved, ensuring that retrieval systems comply with privacy regulations such as GDPR or HIPAA is critical. Techniques like differential privacy and federated learning allow RAG systems to retrieve and process data without exposing sensitive information, maintaining user trust and regulatory compliance.
For instance, federated learning enables decentralized data processing, where models are trained locally on user devices and only aggregated updates are shared. This minimizes the risk of data breaches while still improving system performance. Similarly, implementing access control layers ensures that retrieved data aligns with user permissions, preventing unauthorized access.
These practices not only safeguard data but also enhance system reliability. As privacy concerns grow, integrating such mechanisms will be essential for scaling RAG solutions across regulated industries, setting a new standard for ethical AI deployment.
Advanced Applications of RAG
Retrieval-Augmented Generation (RAG) is redefining industries by enabling multi-hop reasoning for complex problem-solving. For example, in legal research, RAG systems can retrieve case law from multiple jurisdictions, synthesize arguments, and generate coherent legal briefs. This capability not only saves time but also ensures comprehensive coverage of relevant precedents.
In healthcare, RAG powers personalized treatment recommendations by integrating patient data with the latest medical research. A notable case study involves a system that retrieved clinical trial data to suggest tailored cancer therapies, improving patient outcomes by 20% (source: Nexla). This demonstrates how RAG bridges the gap between static knowledge bases and dynamic, real-world needs.
Unexpectedly, RAG is also transforming creative industries. By blending factual retrieval with generative storytelling, it assists in crafting scripts or marketing campaigns. This cross-disciplinary impact highlights RAG’s versatility, challenging the misconception that it’s limited to technical domains. As adoption grows, its potential to innovate remains boundless.
Personalized Content Generation
Unlike static recommendation systems, RAG adapts in real time by analyzing user behavior, preferences, and even external trends. For instance, an e-commerce platform can use RAG to recommend products not just based on purchase history but also factoring in seasonal demand or social media trends, creating hyper-relevant suggestions.
Systems that retrieve at the passage level rather than full documents achieve higher precision, as they focus on the most relevant snippets. This approach has been particularly effective in media platforms, where RAG-generated personalized playlists increased user engagement by 35% (source: Spotify Labs).
To maximize impact, businesses should integrate feedback loops. By continuously refining retrieval models based on user interactions, RAG systems can evolve, ensuring content remains both accurate and engaging in dynamic environments.
Real-Time Data Processing and Analytics
Predictive caching preloads frequently accessed data based on usage patterns. This reduces latency significantly, especially in high-demand scenarios like financial trading platforms, where milliseconds can determine profit or loss. By leveraging historical data trends, predictive caching ensures that critical information is readily available without overloading retrieval pipelines.
Another underexplored factor is the role of edge computing. Processing data closer to the source minimizes network delays, making it ideal for applications like IoT analytics in smart cities. For example, traffic management systems using RAG can dynamically adjust signals based on real-time congestion data, improving urban mobility.
To optimize outcomes, organizations should adopt hybrid architectures that combine centralized cloud processing with edge nodes. This approach balances scalability with speed, ensuring robust analytics even under fluctuating workloads. As data volumes grow, such frameworks will become indispensable for maintaining competitive agility.
Multilingual and Cross-Domain Generation
Traditional models often struggle with idiomatic expressions or domain-specific jargon, leading to inaccuracies. By leveraging multilingual embeddings trained on parallel corpora, RAG systems can map semantically similar concepts across languages, ensuring consistency in retrieval and generation. For instance, in legal translations, this approach ensures that nuanced terms like “force majeure” are accurately interpreted across jurisdictions.
Another promising technique is cross-lingual transfer learning, where a high-resource language model is fine-tuned to support low-resource languages. This has profound implications for global healthcare, enabling RAG systems to retrieve and generate medical advice in underserved languages, bridging critical knowledge gaps.
To enhance outcomes, integrating domain-specific ontologies with multilingual embeddings can further refine retrieval accuracy. This hybrid approach not only improves cross-domain adaptability but also sets a foundation for equitable AI systems that cater to diverse linguistic and cultural contexts.
Integration with Other AI Technologies
Synergizing RAG with reinforcement learning (RL) can optimize decision-making in dynamic environments. While RAG excels at retrieving and generating contextually relevant information, RL can guide the system to prioritize retrieval paths that maximize long-term utility. For example, in financial trading, RAG can fetch real-time market data, while RL algorithms determine which data streams are most impactful for predictive modeling.
Another promising avenue is fusion with computer vision systems. By combining RAG with image recognition models, applications like medical diagnostics can retrieve textual insights (e.g., research papers) based on visual inputs like X-rays. This cross-modal integration enhances diagnostic accuracy and speeds up decision-making.
Ensuring that textual and visual data are semantically synchronized requires advanced embeddings. Moving forward, modular frameworks can streamline these integrations, enabling scalable, domain-specific solutions.
Ethical Implications and Bias Mitigation
Traditional approaches often focus on debiasing the generation phase, but biases in retrieved data can amplify systemic issues. By implementing diversity-aware ranking algorithms, RAG systems can ensure balanced representation across sources. For instance, in legal research, retrieval pipelines can prioritize documents from varied jurisdictions to avoid over-reliance on dominant legal precedents.
This involves dynamically adjusting retrieval parameters based on the query’s intent and domain. For example, in healthcare, filtering out outdated or regionally biased studies ensures equitable treatment recommendations.
Feedback loop biases can exacerbate issues if user interactions reinforce skewed retrieval patterns. Addressing this requires adaptive feedback mechanisms that prioritize underrepresented perspectives. Moving forward, integrating explainable AI frameworks can enhance transparency, fostering trust and ethical compliance in RAG systems.
Emerging Trends and Future Directions
One emerging trend in RAG is the rise of multimodal retrieval-augmented systems, which integrate text, images, and audio into a unified framework. For example, healthcare applications now combine patient records with diagnostic imaging to provide contextually rich insights. This shift not only enhances accuracy but also opens doors to cross-disciplinary innovations, such as blending legal text analysis with visual evidence in court cases.
Another promising direction is real-time personalization. By leveraging user interaction data, RAG systems can dynamically adapt retrieval strategies. A case in point: e-commerce platforms using RAG to refine product recommendations based on live browsing behavior, significantly boosting conversion rates.
Advancements in edge computing and predictive caching are reducing latency, enabling near-instantaneous responses. As these technologies mature, RAG will likely redefine industries by bridging the gap between static knowledge bases and dynamic, real-world applications.
Zero-Shot and Few-Shot Learning in RAG
Zero-shot and few-shot learning in RAG systems unlock the ability to tackle new tasks with minimal data. Unlike traditional models that require extensive retraining, RAG leverages external retrieval to fill knowledge gaps dynamically. For instance, in legal research, a zero-shot RAG model can retrieve case law and generate summaries without prior domain-specific training, saving weeks of preparation.
The key lies in retrieval precision. Few-shot learning enhances this by providing contextual examples, which refine the model’s understanding of nuanced queries. A study by Izacard et al. (2022) demonstrated that few-shot RAG setups significantly outperform zero-shot in complex tasks like medical diagnosis, where subtle distinctions matter.
Poor embeddings can misalign retrieval, even in few-shot scenarios. To mitigate this, organizations should prioritize domain-specific embeddings and iterative fine-tuning. As industries demand faster adaptation, these approaches will define the next wave of RAG innovation.
Reinforcement Learning Enhancements
Reinforcement learning (RL) in RAG systems excels at optimizing retrieval strategies by rewarding precision and relevance. A standout approach is policy gradient methods, which adjust retrieval policies based on feedback from generated outputs. For example, in customer support chatbots, RL fine-tunes retrieval to prioritize documents that resolve user queries faster, improving both efficiency and user satisfaction.
Static metrics like BLEU scores are commonly used, but dynamic, task-specific rewards—such as user engagement or task completion rates—yield better results.Research by Zhan et al. (2023) highlights how adaptive reward functions significantly enhance retrieval accuracy in real-time applications.
Moreover, RL bridges disciplines like game theory, where multi-agent systems can simulate complex retrieval scenarios. To implement RL effectively, organizations should invest in simulated environments for pre-deployment testing. This ensures robust performance under diverse conditions, paving the way for scalable, adaptive RAG systems.
Advancements in Deep Learning Architectures
Unlike traditional dense attention, sparse attention reduces computational overhead by focusing only on the most relevant tokens. This approach has proven effective in large-scale document retrieval, where models like BigBird excel at processing lengthy inputs without sacrificing accuracy.
Another breakthrough is mixture-of-experts (MoE) models, which dynamically activate only a subset of neural pathways during inference. This not only enhances scalability but also allows RAG systems to specialize in domain-specific tasks. For instance, MoE-based architectures have been deployed in legal research, enabling precise retrieval of case laws while maintaining efficiency.
Layer-wise pretraining fine-tunes specific layers for retrieval tasks. By combining sparse attention with MoE, organizations can achieve both speed and precision. Future architectures should explore hybrid models that balance generalization with task-specific optimization.
Collaborative Research and Open-Source Contributions
Community-driven benchmarking platforms like Hugging Face Datasets enables researchers to share preprocessed datasets and evaluation scripts, fostering transparency and reproducibility. By standardizing benchmarks, they reduce redundant efforts and accelerate innovation, particularly in niche domains like low-resource languages.
Open-source contributions, such as Haystack and LangChain, have democratized access to cutting-edge RAG tools. These frameworks allow developers to prototype retrieval pipelines without extensive infrastructure, bridging the gap between academia and industry. For example, Haystack’s modular design has been instrumental in deploying RAG systems for real-time customer support.
Permissive licenses encourage adoption but may limit contributions back to the community. To address this, organizations should adopt hybrid models that balance openness with sustainability, ensuring long-term collaboration and growth in the RAG ecosystem.
Predicting the Evolution of RAG Technologies
Quantum-inspired algorithms enhances retrieval efficiency. These algorithms mimic quantum computing principles, such as superposition, to explore multiple retrieval paths simultaneously. Early experiments in hybrid quantum-classical systems have shown promise in reducing latency for large-scale datasets, particularly in industries like finance and genomics.
Another transformative approach is the adoption of self-supervised learning for retrieval optimization. By leveraging unlabeled data, RAG systems can continuously refine their retrieval models without manual intervention. This has been particularly impactful in dynamic fields like news aggregation, where real-time updates are critical.
As sustainability becomes a priority, lightweight RAG models using sparse attention mechanisms are gaining traction. These advancements not only reduce computational costs but also align with broader environmental goals, setting a precedent for responsible AI development.
FAQ
1. What are the most common challenges faced in implementing Retrieval-Augmented Generation (RAG) systems?
Augmented Generation (RAG) systems?
Common challenges in implementing RAG systems include:
Scalability: Managing efficient retrieval and generation as data grows requires optimized mechanisms.
- Data Quality: Poor or outdated data leads to irrelevant outputs, making validation and regular updates crucial.
- Integration Complexity: Combining retrieval and generation components demands careful design to avoid training and deployment issues.
- Latency: Real-time applications require low-latency responses, but retrieval and generation can be computationally intensive. Techniques like caching and approximate nearest neighbor search can reduce overhead.
- Ethical Concerns: Bias in retrieved data and handling sensitive information require bias-aware pipelines and strong data protection.
Addressing these challenges ensures better performance and reliability in RAG systems.
2. How can organizations improve the accuracy and relevance of retrieved information in RAG?
Organizations can improve the accuracy and relevance of retrieved information in RAG through:
- Enhanced Metadata Tagging: Use detailed, domain-specific metadata to help retrieval systems prioritize relevant information.
- Contextual Query Expansion: Refine queries with added context or synonyms to improve alignment with intended meanings.
- Domain-Specific Embeddings: Leverage tailored embeddings to enhance the semantic understanding of queries and documents for precise retrieval.
- Post-Retrieval Filtering: Apply filters to eliminate irrelevant or low-quality results, ensuring only accurate information is used.
- Regular Knowledge Base Updates: Maintain an up-to-date knowledge base by removing outdated or redundant data to ensure reliability.
These strategies collectively boost retrieval precision and relevance.
3. What strategies can be used to address latency issues in RAG applications?
Strategies to address latency in RAG applications include:
- Asynchronous Processing: Use multi-threaded architectures to run retrieval and generation tasks in parallel, reducing response times.
- Caching and Pre-Fetching: Store frequently accessed data or pre-fetch likely queries to minimize repeated retrievals, improving efficiency.
- Optimized Indexing: Apply advanced indexing techniques like inverted indexing or vector-based retrieval with tools like FAISS for faster data access.
- Distributed Computing: Deploy components across distributed systems to balance workloads and reduce bottlenecks in large-scale applications.
- Model Pruning and Compression: Use techniques like pruning, quantization, or distillation to reduce model size and complexity, lowering computational overhead.
These strategies enhance speed and efficiency in RAG systems.
4. How does scalability impact the performance of RAG systems, and what are the best practices to manage it?
Scalability affects RAG systems by increasing computational demands, slowing retrieval, and complicating data consistency as datasets grow. Ensuring real-time responses becomes harder, with risks of errors and outdated information rising.
Best practices to manage scalability include:
- Efficient Indexing: Use advanced techniques like approximate nearest neighbor (ANN) algorithms for faster retrieval.
- Distributed Architectures: Leverage distributed systems and vector databases to handle large datasets while ensuring performance.
- Incremental Indexing: Update indexes incrementally to maintain consistency without downtime.
- Parallel Pipelines: Implement parallel ingestion and retrieval pipelines to avoid bottlenecks with high data volumes.
- Hardware Optimization: Invest in robust infrastructure, including AI-specific accelerators, for better computational efficiency.
These practices ensure scalable and reliable RAG performance.
5. What role does knowledge base maintenance play in overcoming RAG challenges, and how can it be optimized?
Maintaining a knowledge base is crucial for addressing RAG challenges, ensuring the accuracy, relevance, and timeliness of retrieved information, and improving system reliability.
To optimize knowledge base maintenance:
- Regular Updates: Automate frequent updates to reflect the latest information, especially in dynamic fields like healthcare or current events.
- Data Validation: Use rigorous validation processes to remove inaccurate or redundant data, preserving data integrity.
- Version Control: Implement version control to track changes and enable rollbacks if errors or inconsistencies occur.
- Scalable Data Ingestion: Design scalable pipelines to integrate new data seamlessly without disrupting operations.
- Monitoring and Feedback: Continuously monitor performance and leverage user feedback to identify and address gaps or inaccuracies.
These strategies enhance the quality and reliability of RAG systems.
Conclusion
Retrieval-Augmented Generation (RAG) represents a transformative leap in AI, but its challenges demand nuanced solutions to unlock its full potential. Think of RAG as a symphony orchestra: the retrieval system is the sheet music, and the generative model is the musician. Without precise alignment, the result is discordant. For instance, latency issues in real-time applications like healthcare chatbots can mean the difference between timely advice and critical delays. Solutions like asynchronous processing and predictive caching have proven to cut response times by up to 40%, as seen in case studies from leading AI firms.
A common misconception is that larger knowledge bases always improve performance. In reality, poorly maintained data can amplify biases or inaccuracies. Companies like OpenAI have shown that regular updates and domain-specific embeddings significantly enhance output quality.
Ultimately, RAG’s success hinges on balancing scalability, accuracy, and speed. By addressing these challenges, organizations can harness RAG to deliver precision and adaptability at scale.