
Building a Codebase Exploration Tool Using RAG
RAG can power smarter codebase exploration tools. This guide shows how to implement RAG to improve code search, documentation access, and developer assistance-boosting productivity and enabling efficient understanding of large codebases.


Codebases are growing faster than developers can make sense of them.
A single repository might span years of updates, thousands of files, and layers of undocumented decisions.
Finding the right function, understanding its purpose, or tracing a bug through old commits can feel like searching for a sentence in a library with no index.
That’s where Building a Codebase Exploration Tool Using RAG starts to matter. Traditional search tools don’t understand structure. They match strings, not meaning.
But Building a Codebase Exploration Tool Using RAG—Retrieval-Augmented Generation—lets you search by context, not just keywords. It gives developers what they actually need: relevant, accurate chunks of code, pulled from the noise.
This article walks through how to make that happen—how to turn a chaotic repository into a system you can navigate with confidence.
We discuss the mechanisms that make modern code exploration possible, from chunking and embeddings to dynamic retrieval and IDE integration.
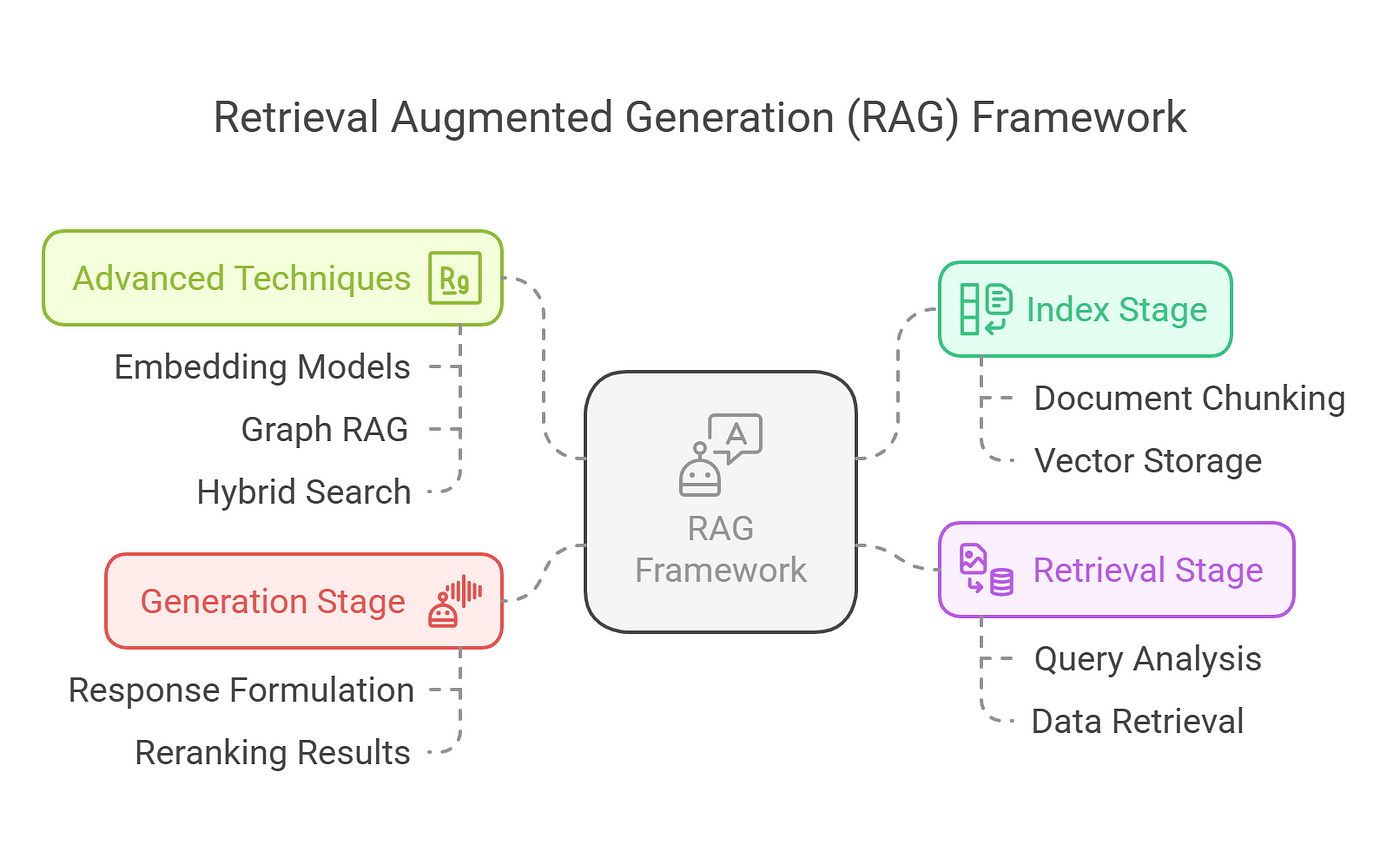
Core Mechanisms of RAG
The retrieval module in RAG systems is not merely a data-fetching tool; it is the linchpin for contextual precision.
By leveraging dense vector representations, this module ensures that retrieved code snippets or documents align semantically with the query, preserving the intricate relationships within the codebase. This alignment is critical in software engineering, where even minor contextual mismatches can lead to significant inefficiencies.
One of the most effective techniques involves dynamic retrieval mechanisms that adapt to evolving query patterns.
Unlike static retrieval, these systems recalibrate their strategies based on real-time feedback, ensuring relevance even as project requirements shift.
For instance, hybrid approaches combining dense and sparse retrieval methods have shown promise in balancing precision and recall, particularly in large-scale repositories.
However, challenges persist.
Ambiguities in unstructured code comments or incomplete documentation can hinder retrieval accuracy.
Addressing these requires integrating corrective RAG techniques, such as re-ranking retrieved results based on contextual coherence, to refine outputs further.
Ultimately, the interplay between retrieval precision and adaptive mechanisms transforms RAG into a tool capable of navigating the complexities of modern codebases.
Role of Vector Databases in RAG
Vector databases excel in transforming raw code into semantically rich embeddings, enabling precise retrieval that respects the intent behind the code.
This capability is particularly critical when dealing with sprawling repositories, where the relationships between code components often transcend simple keyword matches.
By embedding code into high-dimensional vector spaces, these databases allow RAG systems to retrieve contextually relevant snippets, even when queries are phrased differently from the stored data.
One often-overlooked aspect is the importance of fine-tuning the embedding model to align with the codebase's domain-specific nuances.
For example, in a financial software project, embeddings must capture the unique semantics of regulatory compliance logic. Failure to do so can lead to retrieval mismatches, undermining the system’s utility.
Tools like FAISS and Pinecone offer configurable parameters to optimize this alignment, but their effectiveness depends on careful calibration.
A practical implementation challenge arises in balancing retrieval speed with accuracy. Approximate nearest neighbor (ANN) algorithms, while fast, may occasionally sacrifice precision.
To mitigate this, hybrid approaches combining ANN with re-ranking mechanisms based on contextual coherence have proven effective. These methods ensure that retrieved results are not only relevant but also actionable, particularly in debugging scenarios.
The implications are profound: vector databases, when adequately configured, transform RAG systems into intuitive tools that empower developers to navigate even the most complex codebases with confidence.
Indexing and Embedding Codebases
Indexing a codebase begins with a fundamental shift: treating code as a structured ecosystem rather than isolated text.
This perspective enables the creation of embeddings that reflect the semantic relationships within the code.
The key lies in chunking—dividing the code into meaningful units like methods, classes, or modules.
Unlike arbitrary text splits, this approach preserves the code's logical flow and intent, ensuring embeddings capture its true essence.
A critical step is selecting the right embedding model. Domain-specific fine-tuning is non-negotiable; for instance, embeddings for a healthcare application must grasp the nuances of compliance and data privacy.
Tools like OpenAI’s Codex or sentence transformers excel here, but their effectiveness hinges on preprocessing. Metadata tagging—annotating chunks with details like programming language or function type—further enhances retrieval accuracy.
Think of embeddings as a map, and chunking as the act of drawing boundaries. Without thoughtful segmentation, the map becomes a blur, leading to irrelevant or incomplete retrievals. Proper indexing transforms codebases into intuitive, query-ready resources.
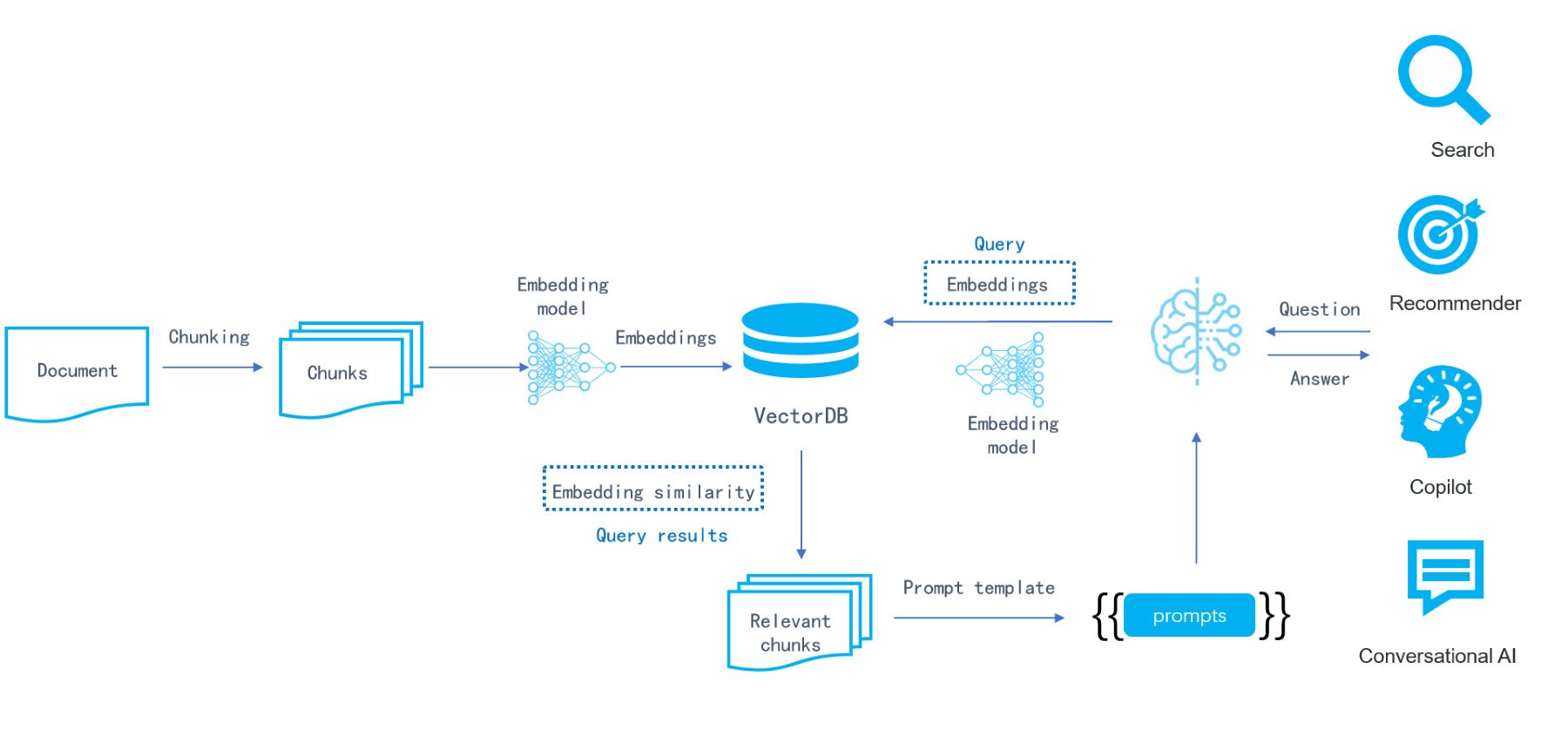
Techniques for Code Chunking
One of the most effective techniques for code chunking is embedding-model-aware segmentation, which aligns chunk boundaries with the code's semantic structure.
This approach ensures that each chunk represents a coherent unit of meaning, such as a function or class, rather than arbitrary slices of text.
This technique's importance lies in its ability to preserve the logical flow of the code, which is critical for generating high-quality embeddings.
When chunks are misaligned with the code’s structure, embeddings often fail to capture the relationships between components, leading to retrieval errors.
By contrast, embedding-model-aware chunking leverages the strengths of models like sentence-transformers to optimize chunk size and content for semantic clarity.
A key challenge in implementing this technique is balancing chunk size with model constraints.
While larger chunks capture more context, they risk introducing noise, whereas smaller chunks may lose critical relationships.
Fine-tuning the embedding model to the domain-specific nuances of the codebase can mitigate these issues, ensuring that the resulting chunks are both precise and actionable.
Generating and Managing Embeddings
The process of generating embeddings for codebases hinges on one critical principle: preserving semantic integrity.
Unlike natural language, code is inherently structured, and this structure must be reflected in the embeddings to ensure meaningful retrieval.
A key technique involves using language-specific static analysis to segment code into coherent units, such as methods or classes, while maintaining contextual relationships.
This approach matters because embeddings that fail to capture these relationships often lead to irrelevant or incomplete retrievals.
For instance, splitting a method across multiple chunks can obscure its purpose, reducing the utility of the embedding. By contrast, embedding entire methods or classes ensures that the resulting vectors encapsulate both functionality and intent.
A practical enhancement is the inclusion of metadata during the embedding process. Annotating chunks with details like programming language, function type, or dependencies enriches the retrieval pipeline, enabling more precise and context-aware searches.
This transforms the embedding process from mere vector generation into a comprehensive indexing strategy.
Ultimately, managing embeddings is not just about technical precision; it’s about crafting a system that aligns with the developer’s mental model, turning static codebases into dynamic, navigable resources.
Implementing RAG in Development Environments
Integrating Retrieval-Augmented Generation (RAG) into development environments transforms how developers interact with codebases, making exploration seamless and intuitive.
By embedding RAG into Integrated Development Environments (IDEs) and version control systems, developers gain immediate access to contextually relevant insights, reducing cognitive load and enhancing productivity.
For instance, pairing RAG with tools like JetBrains IntelliJ or Microsoft Visual Studio Code allows real-time retrieval of function dependencies, historical changes, and even peer-reviewed annotations.
This integration ensures that developers can navigate sprawling repositories without losing sight of the bigger picture.
A critical aspect of implementation is aligning RAG with the team’s workflow.
This involves curating a structured knowledge base enriched with metadata—such as author notes, dependencies, and timestamps—to ensure precision in retrieval.
Think of it as equipping your IDE with a dynamic map that evolves with your project, guiding you through even the most intricate code landscapes.
The result? A development process that feels less like searching for a needle in a haystack and more like following a well-lit path.
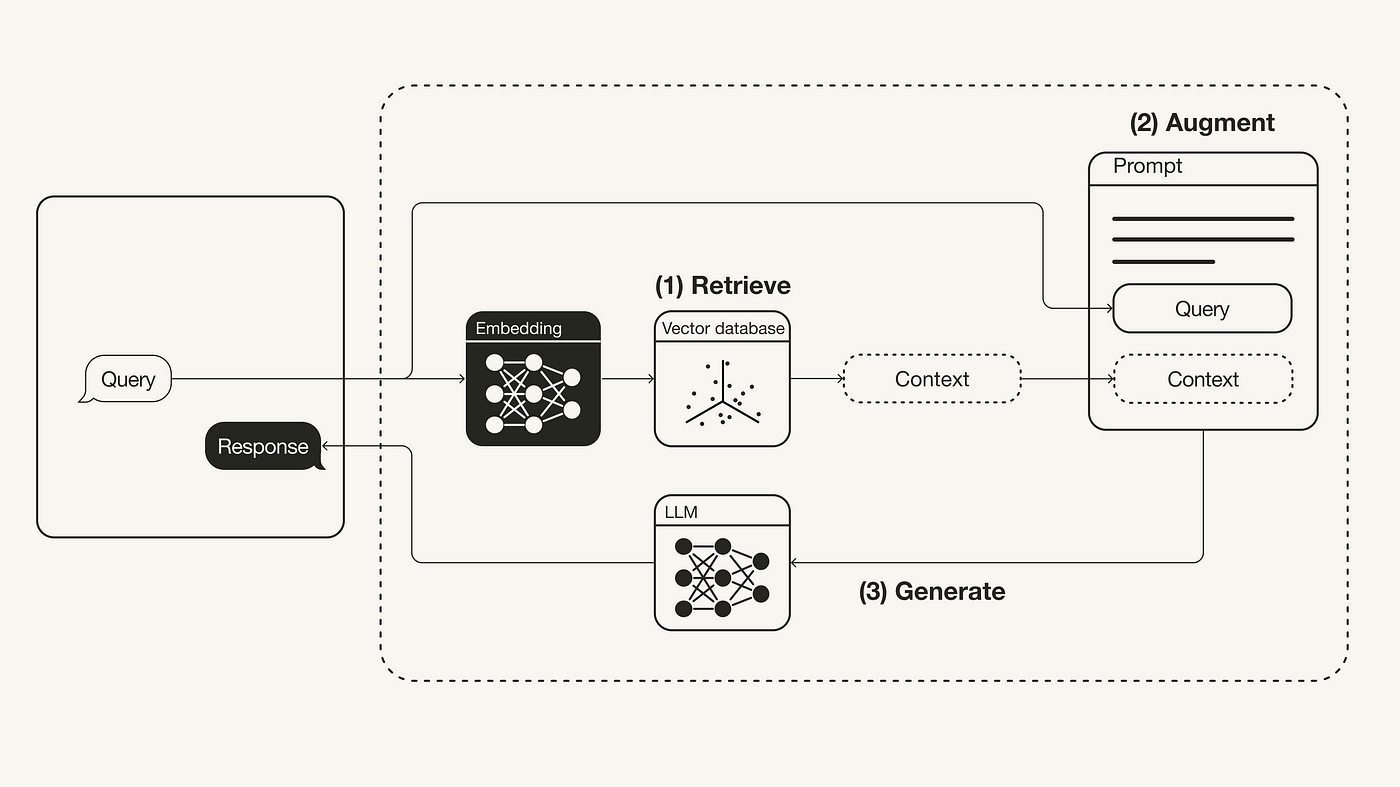
Integrating RAG with IDEs and Version Control
Integrating RAG with IDEs and version control systems hinges on one critical principle: synchronizing real-time retrieval with the evolving state of your codebase.
This isn’t just about fetching relevant snippets; it’s about embedding a dynamic layer of contextual awareness into your development environment.
The key lies in leveraging version control metadata—commit histories, branch structures, and dependency graphs—to inform RAG’s retrieval mechanisms. By aligning retrieval queries with these evolving elements, RAG can surface insights that are not only relevant but also temporally accurate.
For example, when debugging, the system can prioritize code snippets tied to recent changes, reducing noise and accelerating resolution.
Balancing retrieval precision with system performance emerges as a nuanced challenge.
Over-reliance on exhaustive metadata can slow retrieval, while underutilization risks missing critical context. Hybrid indexing strategies, which combine lightweight metadata tagging with selective deep retrieval, offer a practical solution.
This integration transforms IDEs into proactive collaborators, enabling developers to navigate complex codebases with clarity and confidence.
Workflow Optimization for Code Exploration
Dynamic retrieval mechanisms are the cornerstone of optimizing workflows for code exploration.
By enabling real-time updates to embeddings, these systems ensure that retrieval aligns with the latest state of the codebase. This approach minimizes the risk of outdated or irrelevant results, a common pitfall in static retrieval setups.
The process begins with lightweight metadata tagging, which captures essential details—such as commit timestamps and dependency changes—without overloading the system.
This balance is critical; excessive metadata can slow retrieval, while insufficient tagging risks losing context. A hybrid indexing strategy, combining shallow metadata with selective deep retrieval, often strikes the right equilibrium.
To further enhance efficiency, embedding updates can be triggered by version control events, such as merges or pull requests. This synchronization transforms the IDE into a responsive tool that adapts seamlessly to the evolving codebase.
Ultimately, these refinements elevate code exploration from a reactive task to a proactive, streamlined process.
Applications of RAG in Software Development
Retrieval-Augmented Generation (RAG) is reshaping software development by addressing challenges that traditional tools often overlook. One of its most transformative applications lies in debugging complex systems.
Unlike static debugging tools, RAG dynamically retrieves relevant error logs, dependency graphs, and historical fixes, enabling developers to pinpoint root causes with unprecedented accuracy.
Another compelling use case is streamlining onboarding for new developers. RAG systems can curate project-specific knowledge, such as annotated code snippets and architectural overviews, tailored to individual learning curves. This approach not only accelerates onboarding but also ensures consistency in understanding across teams.
Moreover, RAG excels in enhancing code reviews.
Retrieving contextually relevant coding standards and past review comments ensures that feedback is both precise and actionable. This fosters a culture of continuous improvement, where every review becomes a learning opportunity.
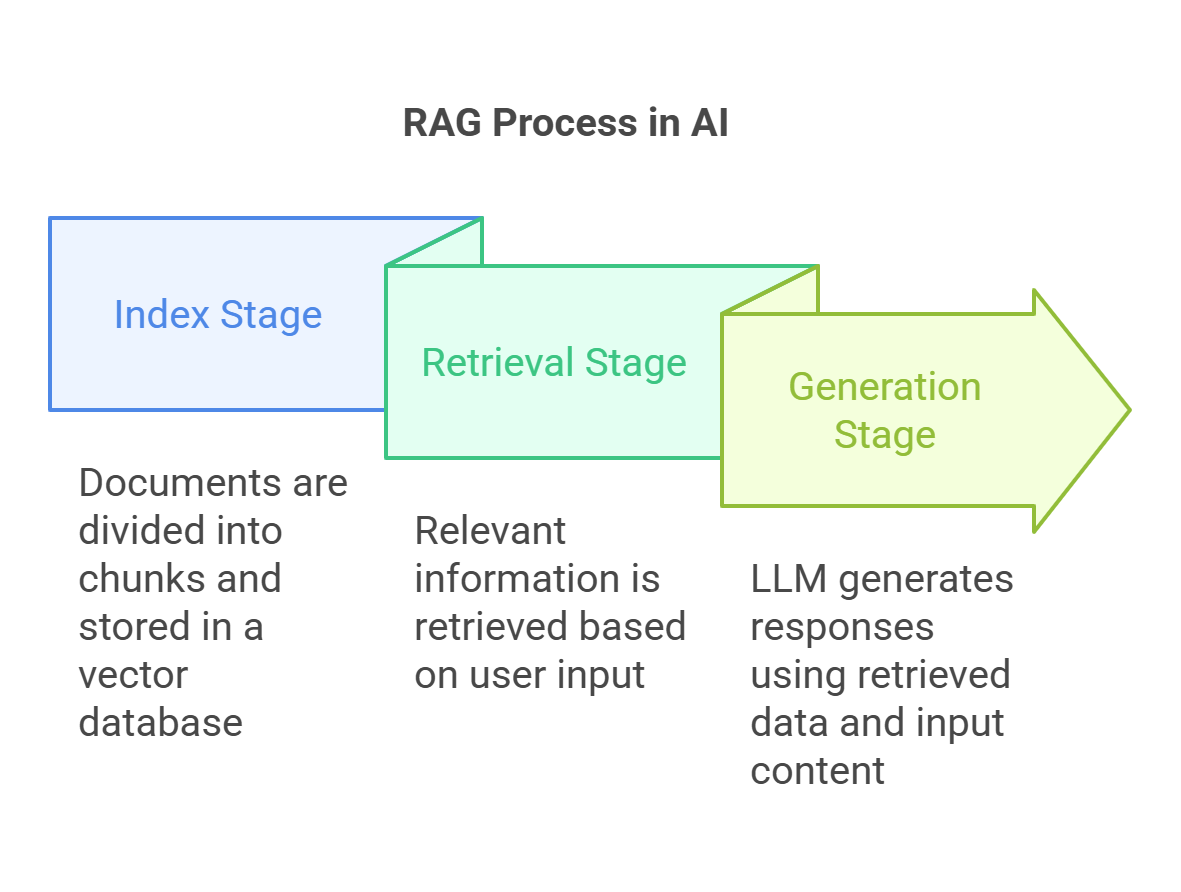
Enhancing Debugging and Code Review
Debugging and code review often hinge on understanding the intricate relationships within a codebase, yet traditional tools rarely provide this level of contextual depth.
RAG fundamentally changes this dynamic by enabling real-time retrieval of relevant historical fixes, dependency graphs, and coding standards, creating a more interactive and informed debugging process.
One key technique is context-aware retrieval, where RAG systems prioritize snippets tied to recent commits or specific error logs.
This ensures that developers are not overwhelmed by irrelevant data, focusing instead on actionable insights.
For example, integrating RAG with version control metadata allows the system to surface changes that directly impact the issue at hand, streamlining the debugging workflow.
Understanding and Modernizing Legacy Code
Modernizing legacy code isn’t just a technical challenge—it’s an exercise in uncovering the intent and history embedded within a system.
Legacy codebases often act as living archives, where every line reflects decisions shaped by past constraints, priorities, and trade-offs. This makes modernization a nuanced process, requiring tools that can interpret not just the code but its context.
Retrieval-Augmented Generation (RAG) offers a transformative approach by enabling semantic retrieval of historical data, such as old commits, annotations, and architectural notes.
Unlike traditional methods that treat legacy systems as static artifacts, RAG dynamically reconstructs the relationships and logic that underpin the code. This capability is particularly powerful when paired with embedding-model-aware chunking, which ensures that retrieved segments maintain their semantic integrity.
One overlooked complexity is the interplay between outdated documentation and evolving system dependencies.
RAG addresses this by integrating metadata tagging, allowing developers to trace dependencies and identify obsolete components without manual effort.
For instance, a financial institution used RAG to modernize a 20-year-old trading platform, uncovering undocumented workflows that were critical to compliance.
By bridging historical context with modern development needs, RAG transforms legacy systems into assets rather than liabilities. This approach not only preserves institutional knowledge but also accelerates the transition to scalable, future-ready architectures.
Challenges and Limitations of RAG
Building a codebase exploration tool using Retrieval-Augmented Generation (RAG) reveals challenges that extend beyond surface-level inefficiencies. One critical issue is scalability under dynamic conditions.
As codebases grow and evolve, RAG systems must process increasingly complex relationships between components. This requires retrieval algorithms capable of maintaining both speed and precision, a balance often disrupted by high computational demands.
For instance, dense vector retrieval, while precise, can falter in real-time environments due to latency.
Another limitation lies in retrieval relevance and bias. RAG systems depend on embeddings to interpret queries, but these embeddings can inherit biases from training data. This skews retrieval results, favoring frequently accessed or well-documented code while sidelining edge cases.
Such imbalances can mislead developers, especially in debugging scenarios where nuanced context is critical.
These challenges underscore the need for adaptive indexing strategies and bias mitigation techniques, ensuring RAG tools remain reliable as repositories expand and diversify.
Technical and Practical Constraints
The interplay between retrieval latency and computational efficiency in RAG systems often reveals a hidden bottleneck: the trade-off between embedding granularity and system responsiveness.
When embeddings are too detailed, retrieval precision improves, but the computational overhead can cripple real-time performance.
Conversely, coarse embeddings may speed up retrieval but at the cost of contextual relevance.
This balance becomes particularly critical in dynamic environments where codebases evolve rapidly.
A practical solution involves adaptive embedding strategies, where the system dynamically adjusts embedding granularity based on query complexity.
For instance, simpler queries trigger lightweight embeddings, while complex, multi-faceted queries engage deeper, more detailed representations. This approach minimizes unnecessary computational strain while preserving retrieval quality.
Addressing Common Misconceptions
One common misconception about RAG is that increasing the volume of data in the knowledge base will automatically enhance retrieval quality.
In reality, an overabundance of irrelevant or poorly structured data can dilute the system’s effectiveness, leading to slower performance and less accurate results.
This issue stems from the way RAG systems process embeddings. When the knowledge base includes excessive noise, such as outdated code snippets or redundant documentation, the retrieval module struggles to prioritize relevant information.
A practical solution involves implementing data curation pipelines that filter and preprocess inputs before embedding.
For instance, tagging code with metadata like dependencies or function types ensures that only contextually significant chunks are indexed.
Ultimately, treating RAG as a precision tool rather than a catch-all solution ensures its integration delivers meaningful results.
FAQ
What are the components needed to build a codebase exploration tool using Retrieval-Augmented Generation (RAG)?
To build a codebase exploration tool using RAG, you need a retrieval system, a large language model, and a vector database. These parts work together to match developer queries with meaningful code snippets from an indexed knowledge base.
How does semantic chunking improve retrieval in codebase exploration tools?
Semantic chunking improves retrieval by breaking code into logical units like functions or classes. This structure helps the system return results that reflect the original meaning and use of the code, reducing irrelevant or fragmented outputs.
What role do vector databases play in Retrieval-Augmented Generation for codebases?
Vector databases store code as embeddings, which capture its structure and meaning. They allow fast, accurate searches by comparing vectors instead of keywords, making it easier to match developer questions with the most relevant code blocks.
How does metadata tagging help in retrieving relevant code snippets in RAG systems?
Metadata tagging adds context such as file type, language, or timestamps to code. This helps RAG systems filter and return more accurate results by aligning queries with code that shares the same traits or usage patterns.
What are best practices for integrating RAG into development tools and version control systems?
Best practices include indexing code after each commit, using metadata from version control, and updating embeddings regularly. These steps keep retrieval accurate and aligned with recent changes in the codebase.
Conclusion
Building a Codebase Exploration Tool Using RAG reshapes how developers interact with large and complex codebases.
By combining structured indexing, semantic chunking, and adaptive retrieval through vector databases, RAG helps surface the right code in the right context.
When integrated into development tools and workflows, it reduces time spent searching and debugging, turning static repositories into dynamic, searchable systems. As RAG systems evolve, they will continue to redefine software development by aligning model behavior with how developers think and work.