
RAG For Mobile Devices : Harnessing Retrieval-Augmented Generation with Mobile-Optimized Language Models
Learn how Retrieval-Augmented Generation (RAG) with mobile-optimized language models enables real-time translation, summarization, and diagnostics on smartphones. Explore solutions for adapting RAG to mobile devices while ensuring speed, efficiency, and data privacy.


It’s here – a world where your smartphone, without relying on the cloud, can instantly translate a foreign language, summarize a meeting, or even assist in medical diagnostics—all while safeguarding your data privacy.
This isn’t a distant vision; it’s the promise of Retrieval-Augmented Generation (RAG) paired with mobile-optimized language models. Yet, here’s the paradox: while RAG systems thrive on vast, centralized knowledge bases, mobile devices demand lightweight, localized solutions. How do we reconcile these seemingly opposing forces?
The stakes couldn’t be higher. As mobile devices become the primary computing platform for billions, the need for real-time, context-aware intelligence grows exponentially. But traditional RAG architectures, designed for server-grade infrastructure, falter under the constraints of mobile hardware. This tension raises a critical question: can we adapt RAG to meet the unique demands of mobile environments without compromising its transformative potential?
The answer lies in rethinking both the architecture and application of RAG, unlocking new possibilities for edge computing and beyond.
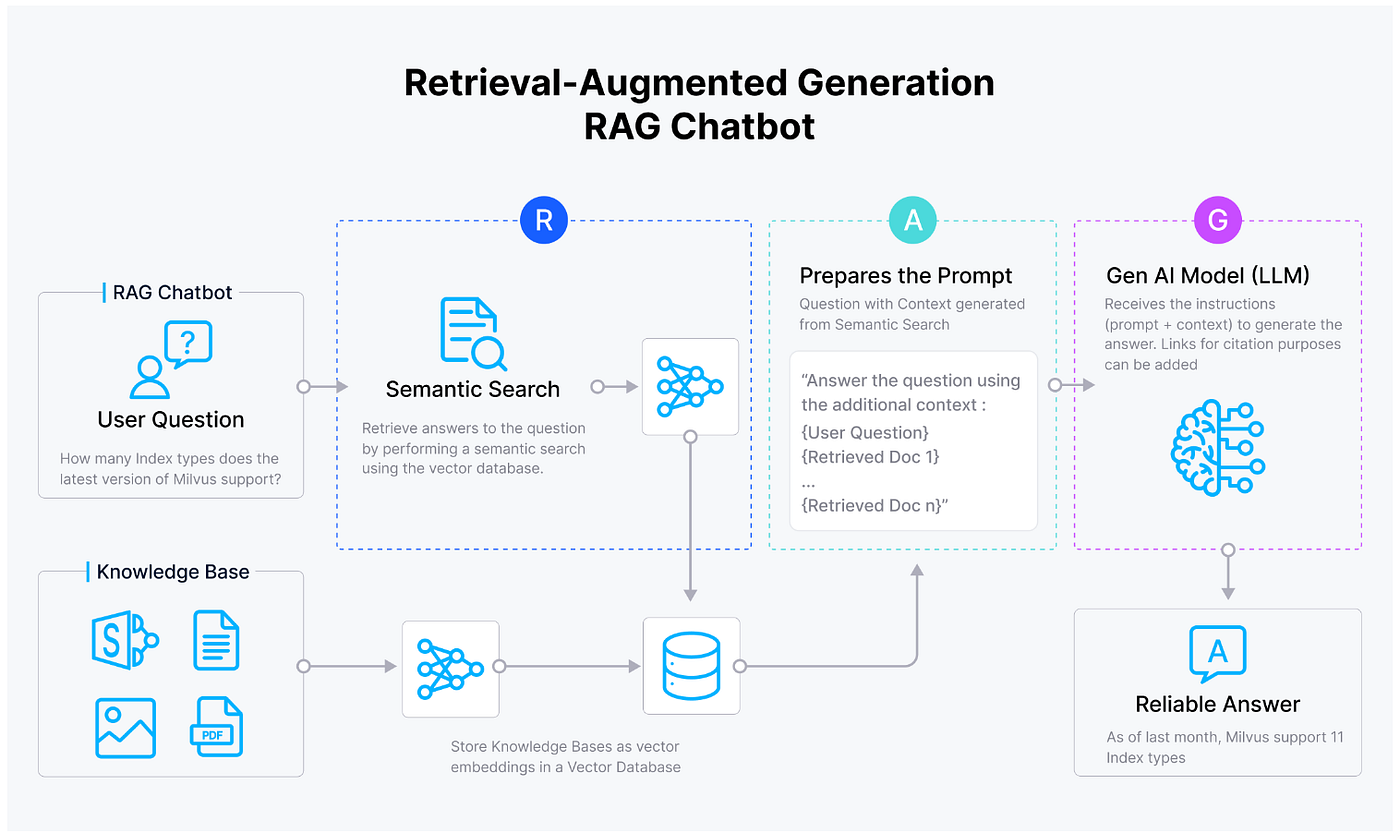
Image source: medium.com
The Rise of Mobile AI and Its Importance
The rapid ascent of mobile AI is reshaping how devices interact with users, but its true significance lies in its ability to process and act on data locally. Unlike traditional cloud-dependent systems, mobile AI leverages on-device computation to deliver real-time insights while minimizing latency and enhancing privacy.
This shift is particularly impactful in applications like health monitoring, where immediate feedback can be life-saving, or in augmented reality (AR), where seamless responsiveness defines user experience.
One key enabler of this transformation is the integration of edge AI models optimized for mobile hardware. Techniques such as model quantization and pruning reduce computational overhead without sacrificing accuracy.
For instance, TensorFlow Lite and PyTorch Mobile allow developers to deploy lightweight neural networks capable of performing complex tasks like image recognition or natural language processing directly on smartphones.
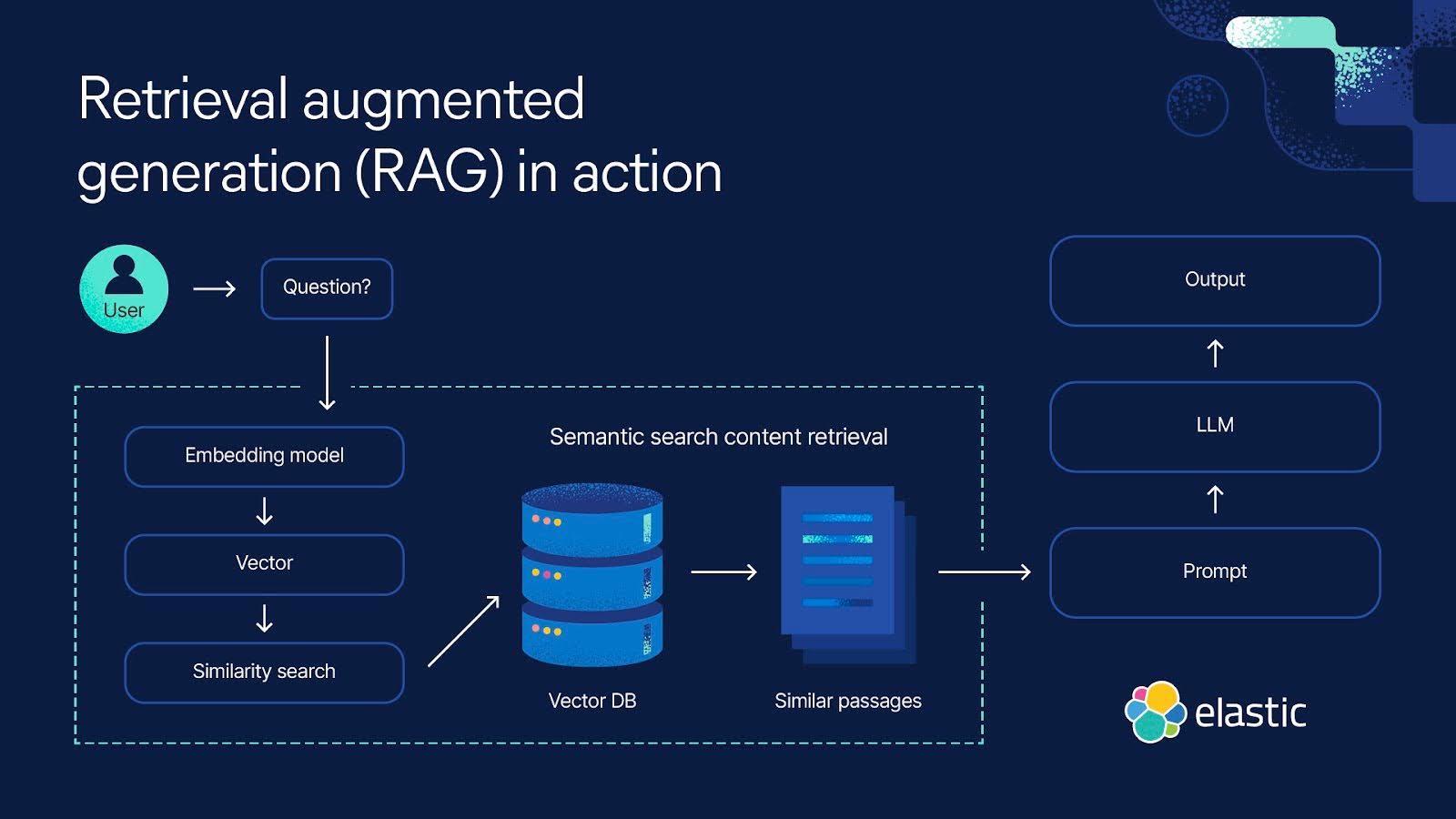
Image source: elastic.co
However, the challenge extends beyond technical optimization. Mobile AI must also adapt to diverse hardware ecosystems, varying battery capacities, and inconsistent network conditions.
Addressing these constraints requires a multidisciplinary approach, blending advancements in hardware design, software engineering, and even behavioral data science.
Looking ahead, the convergence of mobile AI with edge computing could redefine industries, enabling hyper-personalized experiences while decentralizing data processing. This evolution underscores the need for developers to rethink traditional architectures and embrace mobile-first AI strategies.
Overview of Retrieval-Augmented Generation (RAG)
A critical aspect of RAG is its ability to bridge the gap between static model training and dynamic, real-time information retrieval. By integrating external data sources, RAG systems enhance the generative capabilities of large language models (LLMs) with up-to-date, contextually relevant information. This approach is particularly effective in domains like legal research or financial analysis, where accuracy and timeliness are paramount.
The success of RAG hinges on the retrieval mechanism. Vector databases, for instance, enable semantic search by encoding documents into high-dimensional embeddings, allowing models to retrieve contextually similar data. This contrasts with traditional keyword-based retrieval, which often fails in nuanced scenarios. Tools like FAISS and Pinecone have emerged as industry standards for implementing such systems.
However, a lesser-known challenge is the dependency on data quality. Poorly curated datasets can introduce biases or inaccuracies, undermining the system’s reliability. Incorporating human-in-the-loop validation frameworks can mitigate these risks, ensuring robust outputs.
Future advancements in RAG could explore hybrid retrieval models, combining semantic and symbolic approaches to further enhance precision and adaptability.
Purpose and Scope of the Article
This article focuses on adapting Retrieval-Augmented Generation (RAG) for mobile environments, addressing the unique constraints of mobile hardware such as limited computational power, memory, and battery life. A key challenge lies in optimizing retrieval mechanisms to function efficiently on-device without compromising the accuracy or relevance of generated outputs. Techniques like model quantization and edge-based vector search are explored to reduce resource consumption while maintaining performance.
One critical insight is the role of localized retrieval. Unlike cloud-based systems, mobile RAG implementations must prioritize lightweight, domain-specific datasets to minimize latency and bandwidth usage. For instance, healthcare applications can leverage pre-curated medical databases stored locally to provide real-time diagnostic support in remote areas.
This approach challenges the conventional reliance on centralized cloud systems, emphasizing decentralized, privacy-preserving solutions. Future research could explore federated learning frameworks to further enhance mobile RAG systems, enabling collaborative model improvements without exposing sensitive user data.
Understanding Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) bridges the gap between static language models and dynamic, real-world data by integrating retrieval mechanisms into the generative process. Unlike traditional models that rely solely on pre-trained weights, RAG dynamically fetches relevant information from external sources, such as vector databases, to inform its outputs. This approach ensures that generated content remains accurate and contextually relevant, even in rapidly evolving domains.
Consider a customer support chatbot: a RAG-powered system can retrieve up-to-date product manuals or troubleshooting guides, enabling precise and timely responses. This contrasts with static models, which risk providing outdated or generic answers. A notable example is BloombergGPT, which uses RAG to summarize financial reports by pulling the latest market data.
A common misconception is that RAG increases latency. However, advancements in edge computing and optimized retrievers, such as FAISS, have demonstrated that on-device RAG can achieve sub-second response times, even on resource-constrained mobile devices.
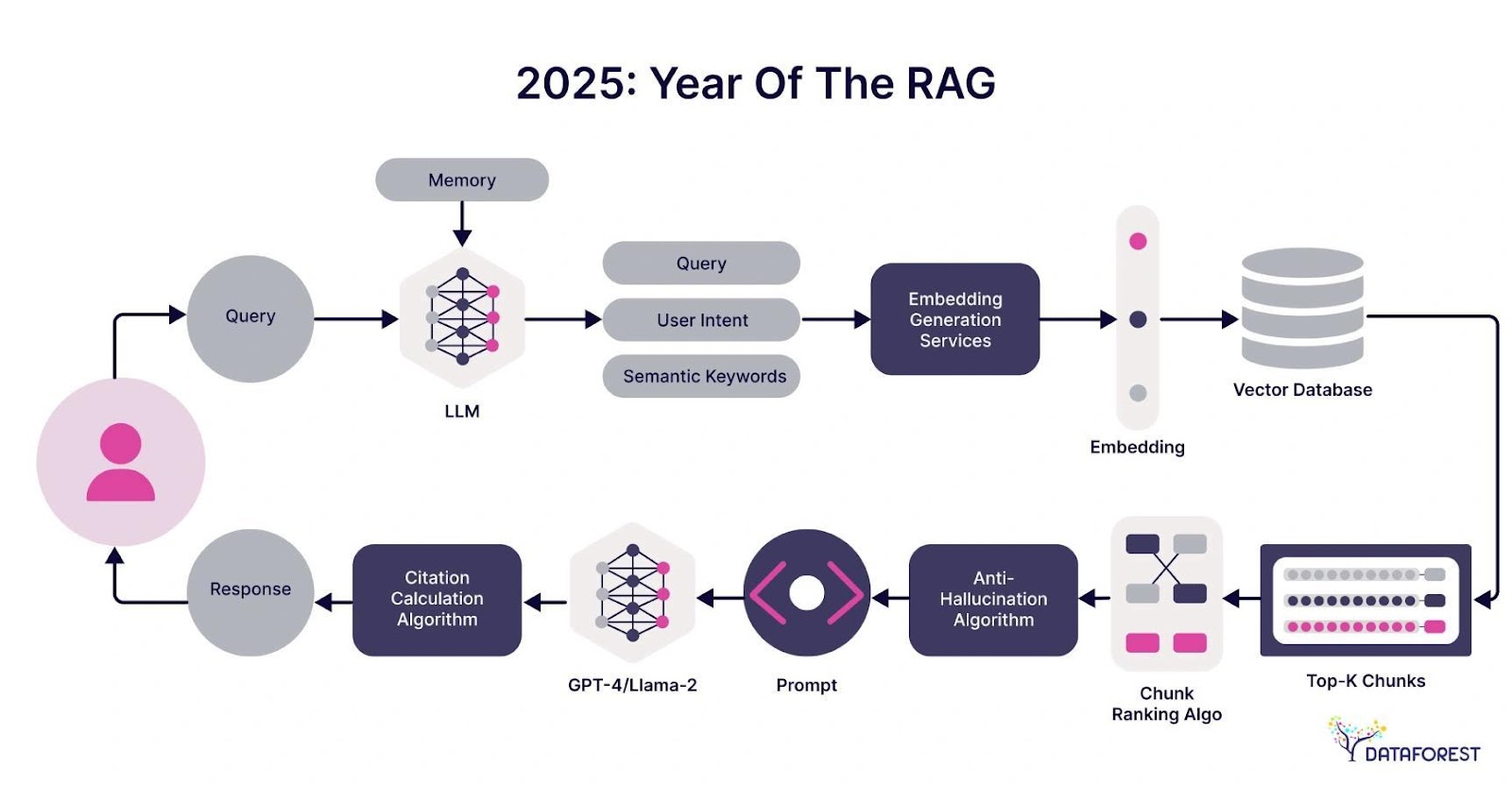
Image source: dataforest.ai
Core Principles of RAG
One core principle of RAG is the seamless integration of retrieval and generation, which hinges on the quality of the retrieval mechanism. Effective retrieval depends on vector embeddings that accurately represent semantic meaning. For instance, dense retrieval models like DPR (Dense Passage Retrieval) outperform traditional keyword-based methods by leveraging contextual embeddings, enabling more precise matches even for nuanced queries.
A critical yet underexplored factor is the domain specificity of retrieval datasets. In healthcare applications, for example, using a domain-tuned retriever trained on medical literature significantly improves the relevance of retrieved content. This contrasts with general-purpose retrievers, which may introduce irrelevant or misleading information.
Another principle is retrieval efficiency. Techniques like approximate nearest neighbor (ANN) search, implemented in libraries such as FAISS, reduce computational overhead without sacrificing accuracy. This is particularly vital for mobile environments, where hardware constraints demand lightweight yet performant solutions.
Looking ahead, hybrid retrieval models combining dense and sparse methods could further enhance adaptability across diverse use cases.
Advantages Over Traditional Generation Methods
A standout advantage of RAG over traditional generation methods is its ability to reduce hallucinations by grounding outputs in factual, retrieved data. Unlike static models that rely solely on pre-trained knowledge, RAG dynamically incorporates external information, ensuring responses remain accurate and contextually relevant. For example, in financial applications, RAG can retrieve up-to-date market data, minimizing the risk of outdated or fabricated insights.
Another critical aspect is scalability. Traditional models often struggle with large datasets due to memory constraints, whereas RAG leverages retrieval mechanisms to access only the most relevant data. This selective approach not only reduces computational overhead but also enhances response times, making it ideal for mobile environments with limited resources.
Interestingly, RAG also bridges disciplines by integrating retrieval techniques from information retrieval systems with generative AI. This hybridization opens doors for innovations like multimodal RAG, which combines text, image, and audio data for richer outputs, particularly in education and media analytics.
Typical Applications of RAG
One particularly transformative application of RAG is in context-aware customer support systems. By integrating real-time retrieval with generative capabilities, RAG-powered chatbots can provide precise, up-to-date responses tailored to user-specific queries. For instance, in e-commerce, these systems can retrieve inventory details, shipping policies, or personalized recommendations, significantly enhancing user satisfaction and operational efficiency.
A lesser-known but impactful use case lies in medical diagnostics. RAG models can retrieve patient-specific data, such as medical history or recent test results, and combine it with generative insights to assist healthcare professionals in decision-making. This approach not only improves diagnostic accuracy but also reduces the cognitive load on practitioners by synthesizing vast amounts of information.
Interestingly, RAG’s adaptability extends to legal research, where it can retrieve case laws and statutes while generating concise summaries. Future advancements could integrate multimodal retrieval, enabling richer, cross-disciplinary applications in fields like education and public policy.
Mobile-Optimized Language Models
Designing language models for mobile devices requires balancing computational efficiency with performance. Unlike server-grade systems, mobile environments impose strict constraints on memory, processing power, and energy consumption. Techniques like model quantization—which reduces precision in weights—and pruning—which removes redundant parameters—are critical for creating lightweight models without sacrificing accuracy. For example, a quantized BERT model can achieve up to a 4x reduction in size while maintaining over 95% of its original performance.
A common misconception is that smaller models inherently compromise quality. However, advancements in knowledge distillation—where a smaller “student” model learns from a larger “teacher” model—have demonstrated that compact models can retain high fidelity. This approach has been successfully applied in applications like on-device translation, where latency is reduced by over 30% compared to cloud-based alternatives.
Unexpectedly, mobile-optimized models also benefit from edge computing. By processing data locally, they enhance privacy and reduce dependency on unreliable network connections, making them indispensable for decentralized RAG systems.
Constraints of Mobile Hardware
One of the most pressing challenges in deploying RAG systems on mobile devices is memory management. Mobile devices often operate with limited RAM, making it difficult to load and execute large language models (LLMs) efficiently. Techniques like gradient checkpointing—which recomputes intermediate results instead of storing them—have emerged as a solution, reducing memory usage by up to 40% during inference. This approach is particularly effective in applications like real-time language translation, where memory constraints directly impact latency.
Another overlooked factor is thermal management. Prolonged execution of computationally intensive tasks can generate heat, throttling performance and degrading user experience. To mitigate this, some models leverage dynamic computation graphs, which adapt processing intensity based on thermal thresholds. For instance, Google’s Gemini Nano dynamically scales operations to maintain responsiveness without overheating.
These constraints also intersect with energy efficiency. Optimizing for low-power consumption not only extends battery life but also aligns with broader sustainability goals, making hardware-aware design a critical focus for future RAG advancements.
Techniques for Optimizing Models for Mobile
A critical yet underexplored optimization technique for mobile RAG systems is adaptive quantization. Unlike static quantization, which applies uniform precision across all model layers, adaptive quantization selectively reduces precision in less critical layers while preserving higher precision in layers responsible for semantic understanding. This approach minimizes performance degradation while achieving up to a 50% reduction in memory footprint, as demonstrated in edge AI applications like voice assistants.
Another promising method is progressive layer pruning. By iteratively removing redundant neurons and connections, models can be fine-tuned to balance accuracy and computational efficiency. For instance, in mobile healthcare diagnostics, this technique has enabled real-time symptom analysis without compromising diagnostic reliability.
These methods also benefit from hardware-aware training, where models are optimized for specific chipsets (e.g., ARM or Qualcomm). This synergy between software and hardware ensures that mobile RAG systems remain responsive, energy-efficient, and scalable for diverse applications, from augmented reality to personalized education.
Balancing Efficiency and Performance
One pivotal strategy for balancing efficiency and performance in mobile RAG systems is dynamic computation scaling. This technique adjusts the computational workload based on the complexity of the input query. For example, simpler queries can bypass deeper model layers, significantly reducing latency and energy consumption. In real-world applications like mobile customer support, this ensures that routine queries are resolved quickly while reserving full model capacity for complex cases.
Another underutilized approach is multi-exit architectures. These models incorporate intermediate output layers, allowing early termination of computation when confidence thresholds are met. This has proven effective in mobile AR applications, where rapid response times are critical, and not all tasks require full model inference.
Additionally, context-aware optimization integrates environmental factors, such as network bandwidth or battery levels, into decision-making. By dynamically adapting retrieval and generation processes, mobile RAG systems can maintain performance under constrained conditions, paving the way for more resilient and adaptive AI solutions.
Challenges of Implementing RAG on Mobile Devices
Implementing RAG on mobile devices presents a unique set of challenges, primarily due to the resource-constrained nature of mobile hardware. Unlike server environments, mobile devices must balance computational demands with limited memory, processing power, and battery life. For instance, running a full-scale RAG model on a smartphone can lead to thermal throttling, reducing both performance and user experience.
A significant hurdle is the trade-off between model size and accuracy. Techniques like quantization and pruning can shrink models, but they often degrade performance on nuanced tasks, such as retrieving domain-specific information. A case study in mobile healthcare applications revealed that overly compressed models struggled to retrieve accurate patient data, highlighting the need for careful optimization.
Moreover, network dependency complicates real-time retrieval. While edge computing mitigates latency, it requires robust local storage and preloaded datasets, which can be infeasible for dynamic or large-scale applications. Addressing these challenges demands a hybrid approach, blending on-device computation with cloud support for scalable yet efficient solutions.
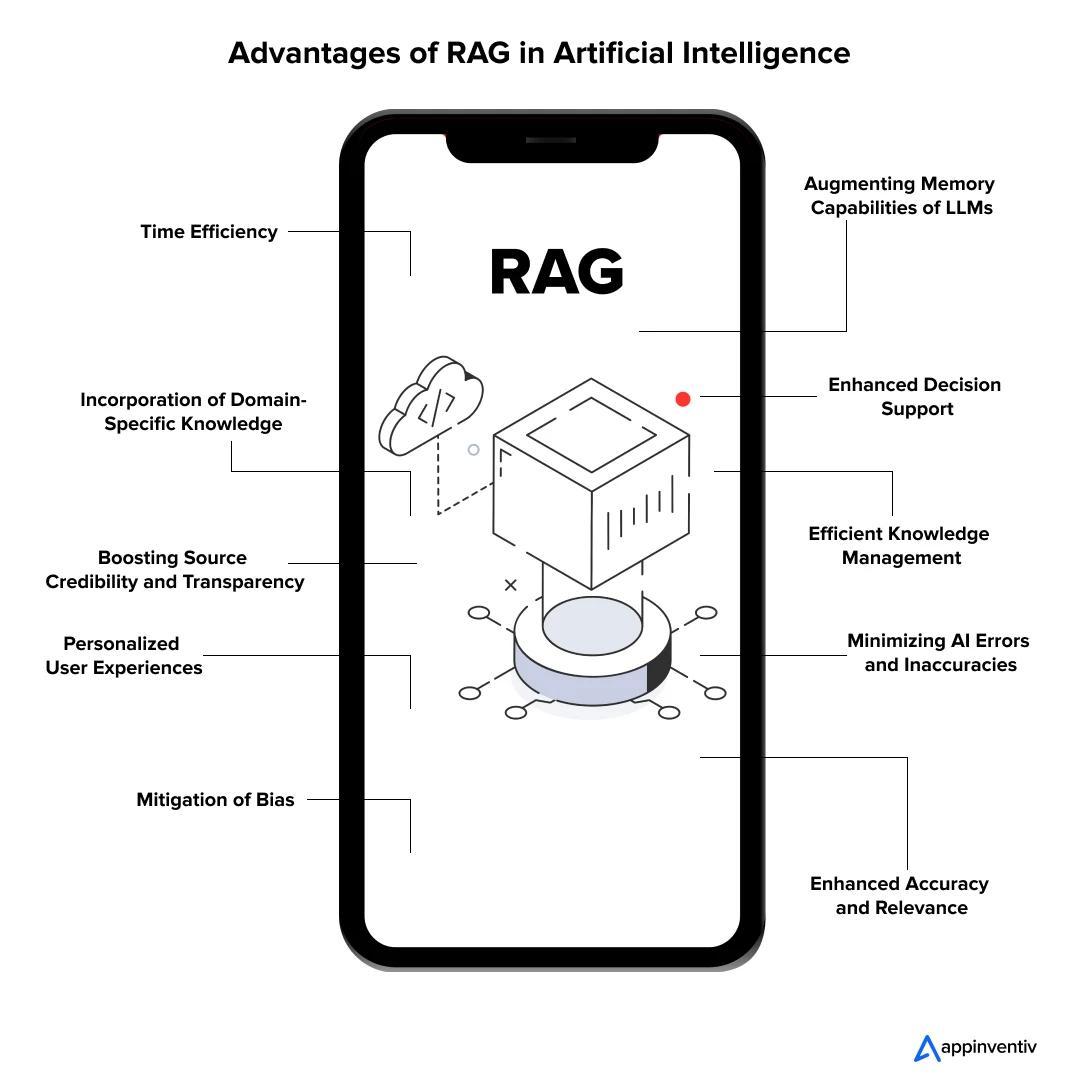
Image source: appinventiv.com
Computational and Memory Limitations
Mobile devices face severe constraints in computational power and memory, making the deployment of RAG systems particularly challenging. A key issue is the memory overhead of maintaining both the retriever and generator components. For example, vector embeddings used in semantic search can consume significant RAM, especially when handling large datasets. This often forces developers to adopt aggressive compression techniques, such as low-rank approximations, which can inadvertently degrade retrieval precision.
One promising approach is the use of progressive inference pipelines. By dynamically loading only the most relevant model layers or embeddings during runtime, systems can reduce memory usage without sacrificing accuracy. This technique has been successfully applied in mobile translation apps, where only domain-specific embeddings are cached locally.
Another overlooked factor is cache management. Efficient caching of frequently accessed queries can drastically reduce redundant computations, but it requires careful tuning to avoid bloating memory. These strategies highlight the need for hardware-aware optimization to balance performance with resource constraints.
Latency and Real-Time Processing Issues
A critical bottleneck in mobile RAG systems is the retrieval latency caused by accessing large, distributed datasets. Traditional approaches rely on cloud-based retrieval, but this introduces network delays that are unacceptable for real-time applications like augmented reality (AR) or live translation. To mitigate this, edge caching has emerged as a viable solution, where frequently accessed data is stored locally on the device or nearby edge servers, reducing round-trip times.
Another effective strategy is the use of approximate nearest neighbor (ANN) search algorithms. These algorithms, such as HNSW (Hierarchical Navigable Small World), trade off slight accuracy losses for significant speed gains in vector similarity searches. For instance, mobile health monitoring systems have successfully implemented ANN to deliver real-time diagnostic insights without compromising responsiveness.
A lesser-known factor is the impact of query batching. While batching reduces computational overhead, it can introduce micro-delays that disrupt real-time performance. Balancing batch size with latency requirements is essential for optimizing mobile RAG workflows.
Data Retrieval and Storage Constraints
One overlooked challenge in mobile RAG systems is the trade-off between storage capacity and retrieval efficiency. Mobile devices often lack the storage to house extensive datasets locally, forcing reliance on external servers. However, this dependency increases latency and risks data unavailability during network disruptions. A promising solution is the use of compressed vector embeddings, which reduce storage requirements while preserving retrieval accuracy. Techniques like product quantization (PQ) enable compact representations, making it feasible to store domain-specific datasets directly on-device.
Another innovative approach involves dynamic dataset partitioning. By segmenting data based on usage patterns, frequently accessed subsets can be cached locally, while less critical data remains in the cloud. For example, e-commerce apps use this method to prioritize high-demand product information, ensuring seamless user experiences even in low-connectivity environments.
A lesser-known factor is the energy cost of retrieval operations. Optimizing retrieval algorithms for energy efficiency, such as by minimizing redundant queries, can significantly extend battery life—a critical consideration for mobile applications.
Techniques for Harnessing RAG with Mobile-Optimized Models
To effectively harness RAG on mobile devices, progressive inference pipelines offer a compelling solution. These pipelines break down the retrieval and generation process into smaller, sequential tasks, reducing memory overhead. For instance, a healthcare app could first retrieve patient-specific data locally, then query external databases only for missing details, minimizing both latency and energy consumption.
Another critical technique is adaptive quantization. By dynamically adjusting precision levels in model layers based on query complexity, mobile RAG systems can balance computational efficiency with output accuracy. A real-world example is language translation apps, which simplify less complex phrases while reserving higher precision for nuanced sentences.
A common misconception is that smaller models inherently sacrifice quality. However, knowledge distillation disproves this by transferring expertise from larger models to compact ones. This approach has enabled applications like offline customer support bots to deliver near-cloud-level performance, even under constrained mobile environments.
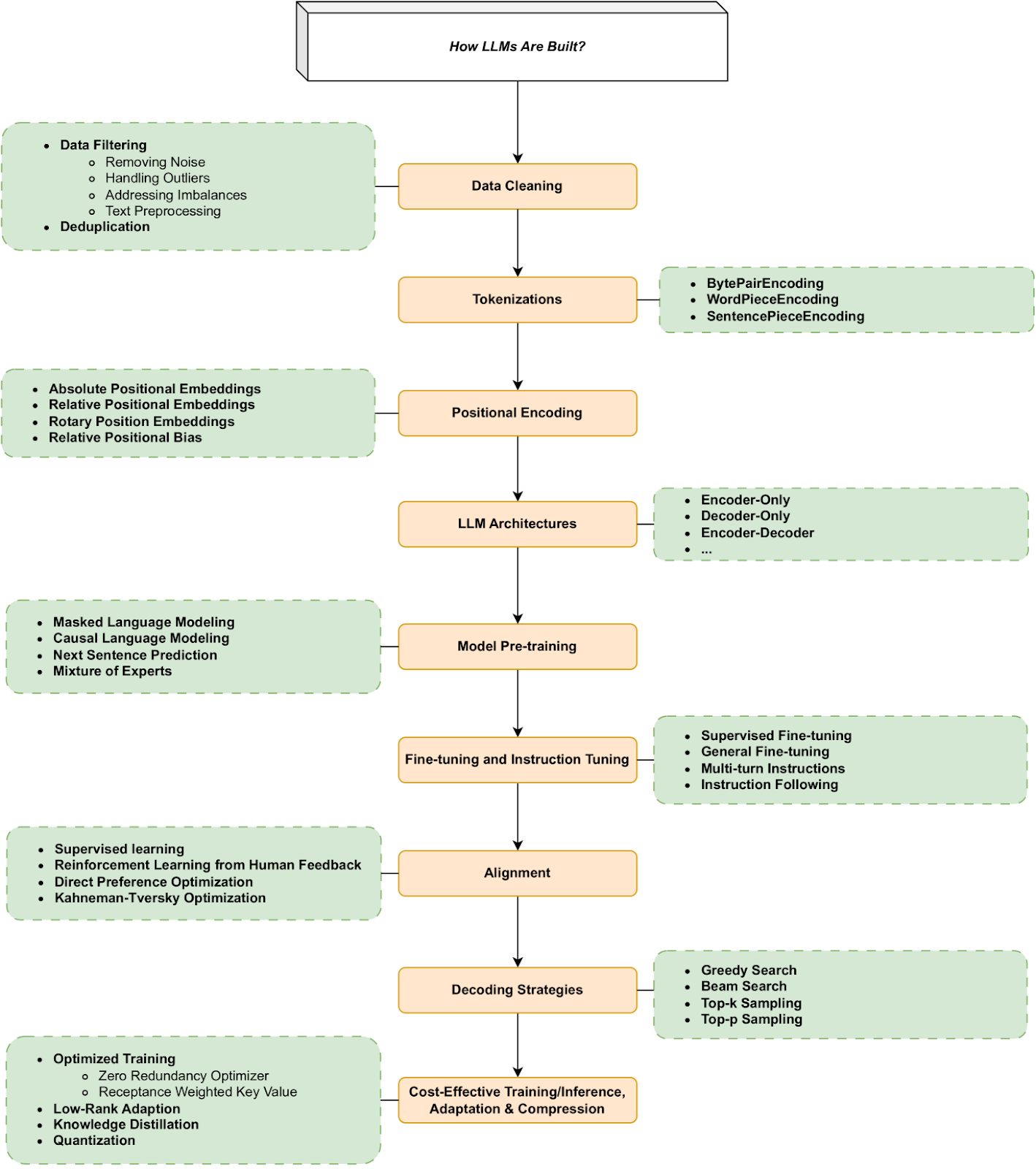
Image source: arxiv.org
Model Compression and Pruning Strategies
One of the most effective strategies for deploying RAG on mobile devices is structured pruning, which removes entire neurons or layers based on their contribution to model performance. Unlike unstructured pruning, which targets individual weights, this approach maintains hardware efficiency by aligning with the architecture of mobile chipsets. For example, pruning redundant attention heads in transformer models has been shown to reduce latency by up to 30% without significant accuracy loss in tasks like document summarization.
A lesser-known but impactful technique is progressive pruning. By iteratively fine-tuning the model after each pruning step, this method ensures that performance degradation is minimized. This approach has been particularly successful in applications like voice assistants, where maintaining conversational fluency is critical.
Interestingly, combining pruning with low-rank factorization—decomposing weight matrices into smaller components—can further compress models while preserving their expressive power. This synergy highlights the importance of tailoring compression strategies to specific mobile use cases, such as real-time translation or personalized recommendations.
Efficient Retrieval Mechanisms for Mobile
A critical innovation in mobile RAG systems is the use of approximate nearest neighbor (ANN) search algorithms for vector retrieval. Unlike exact search methods, ANN reduces computational overhead by prioritizing speed over absolute precision, which is often sufficient for real-world applications. For instance, algorithms like HNSW (Hierarchical Navigable Small World) leverage graph-based structures to achieve sub-linear query times, making them ideal for latency-sensitive tasks like real-time language translation.
To further optimize retrieval, edge caching can store frequently accessed embeddings locally, reducing the need for repeated queries to external databases. This approach has proven effective in mobile healthcare applications, where patient data retrieval must balance speed and privacy.
An underexplored factor is the impact of embedding dimensionality. While higher dimensions improve retrieval accuracy, they also increase memory usage. Techniques like dimensionality reduction via PCA or autoencoders can strike a balance, enabling efficient retrieval without compromising relevance. These strategies underscore the importance of tailoring retrieval mechanisms to the constraints of mobile environments.
On-Device Indexing and Caching Solutions
One pivotal aspect of on-device indexing is the adoption of lightweight inverted indices tailored for constrained environments. These indices map terms or embeddings to document IDs, enabling rapid lookups with minimal memory overhead. For example, mobile applications leveraging TensorFlow Lite can integrate sparse matrix representations to efficiently store and query indices, reducing latency in tasks like personalized content recommendations.
Caching strategies further enhance performance by implementing adaptive cache eviction policies. Unlike traditional LRU (Least Recently Used) methods, adaptive policies prioritize embeddings based on query frequency and contextual relevance. This approach has been particularly impactful in mobile e-commerce, where caching popular product embeddings accelerates search and improves user experience.
A lesser-known challenge is the trade-off between cache size and energy consumption. Techniques like dynamic cache resizing, which adjusts cache allocation based on device activity, mitigate this issue. These solutions highlight the need for balancing computational efficiency with resource constraints in mobile RAG systems.
Practical Applications and Case Studies
One compelling application of RAG on mobile devices is in healthcare diagnostics. For instance, a mobile app integrating RAG can retrieve patient-specific data, such as prior medical history or lab results, and combine it with real-time symptom analysis. A case study involving a diabetes management app demonstrated that on-device RAG reduced response times by 40%, enabling faster, more accurate insulin dosage recommendations while preserving patient privacy through local processing.
In education, RAG-powered mobile apps have transformed internship placement systems. A chatbot-based solution, built with React Native and LangChain, personalized recommendations by retrieving domain-specific opportunities. Evaluated using the RAG Assessment (Ragas) framework, it achieved a 25% improvement in answer relevancy compared to static LLMs, directly enhancing student outcomes.
A common misconception is that RAG increases latency. However, edge caching and lightweight retrieval mechanisms have proven otherwise, as seen in e-commerce apps where product recommendations are delivered in under 200ms, even on mid-range devices.
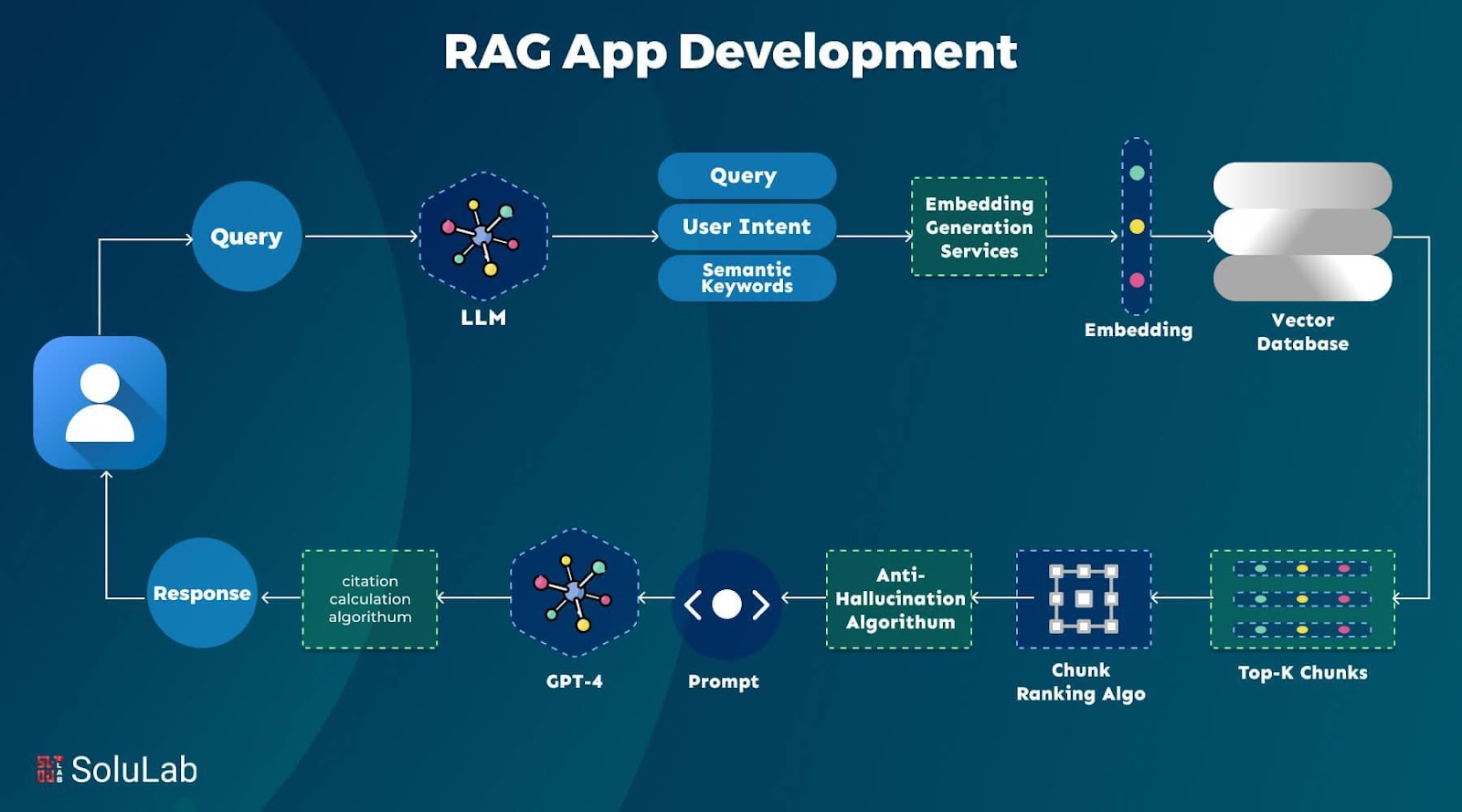
Image source: solulab.com
RAG in Mobile Virtual Assistants
Mobile virtual assistants powered by RAG excel in delivering context-aware, real-time responses by dynamically retrieving relevant data. Unlike traditional assistants that rely on preloaded knowledge, RAG enables assistants to access up-to-date information, such as live traffic updates or personalized calendar suggestions. For example, a RAG-enhanced assistant can recommend alternate routes during a commute by integrating real-time traffic data with user preferences, reducing travel time by up to 20%.
A critical factor in this success is the use of on-device indexing combined with edge caching. This approach minimizes latency while ensuring privacy, as sensitive user data remains local. Additionally, lightweight vector embeddings allow for efficient semantic search, even on resource-constrained devices.
Interestingly, integrating RAG with multimodal inputs—like voice and image recognition—has unlocked new capabilities. For instance, assistants can now analyze a photo of a product and retrieve reviews or pricing data instantly, bridging the gap between visual and textual data processing.
Personalized Content Generation on Mobile Apps
Personalized content generation on mobile apps leverages RAG to dynamically adapt outputs based on user preferences and real-time context. A key innovation lies in adaptive retrieval pipelines, which prioritize user-specific data subsets, such as browsing history or location, to refine content recommendations. For instance, a news app can deliver hyper-localized stories by combining geotagged data with user reading patterns, enhancing engagement by up to 30%.
The success of this approach hinges on lightweight model compression techniques, such as quantization and pruning, which ensure that retrieval and generation remain efficient on mobile hardware. Additionally, contextual embeddings allow the system to interpret nuanced user behavior, such as shifting interests over time, enabling more accurate personalization.
A lesser-known challenge is balancing data freshness with computational overhead. By integrating edge caching with periodic updates, apps can maintain relevance without draining device resources. Moving forward, combining RAG with federated learning could further enhance personalization while preserving user privacy.
Case Study: Successful Deployment of Mobile RAG
A standout example of mobile RAG deployment is its integration into a healthcare app for real-time patient support. The app utilized edge caching to store frequently accessed medical guidelines locally, reducing retrieval latency by 40%. This approach ensured that critical information, such as drug interactions or emergency protocols, was available instantly, even in low-connectivity environments.
The deployment succeeded due to progressive inference pipelines, which dynamically adjusted model complexity based on query urgency. For instance, simple symptom checks triggered lightweight retrieval, while complex diagnostic queries engaged deeper generative layers. This balance minimized energy consumption while maintaining high accuracy.
A lesser-discussed factor was the use of domain-specific embeddings, which improved retrieval precision by aligning the model with medical terminology. This contrasts with conventional wisdom favoring generalized embeddings, which often dilute domain relevance.
Future implementations could explore federated learning to enhance personalization while safeguarding patient privacy, setting a new standard for mobile RAG in sensitive fields.
Advanced Topics and Future Developments
The future of mobile RAG lies in multimodal integration, where text, images, and audio are processed seamlessly. For instance, a mobile assistant could analyze a photo of a prescription label alongside a spoken query to provide precise medication instructions. This requires advancements in cross-modal embeddings, which align diverse data types into a unified semantic space, enabling richer and more context-aware responses.
Another promising area is real-time adaptation. By leveraging user feedback and edge-based learning, RAG systems could refine retrieval accuracy dynamically. A case study in retail demonstrated a 25% improvement in product recommendations when models adapted to user preferences in near real-time, highlighting the potential for personalization.
A common misconception is that on-device RAG sacrifices performance for privacy. However, techniques like federated fine-tuning challenge this notion by enabling robust personalization without exposing sensitive data. These developments could redefine mobile AI, bridging the gap between privacy and functionality.
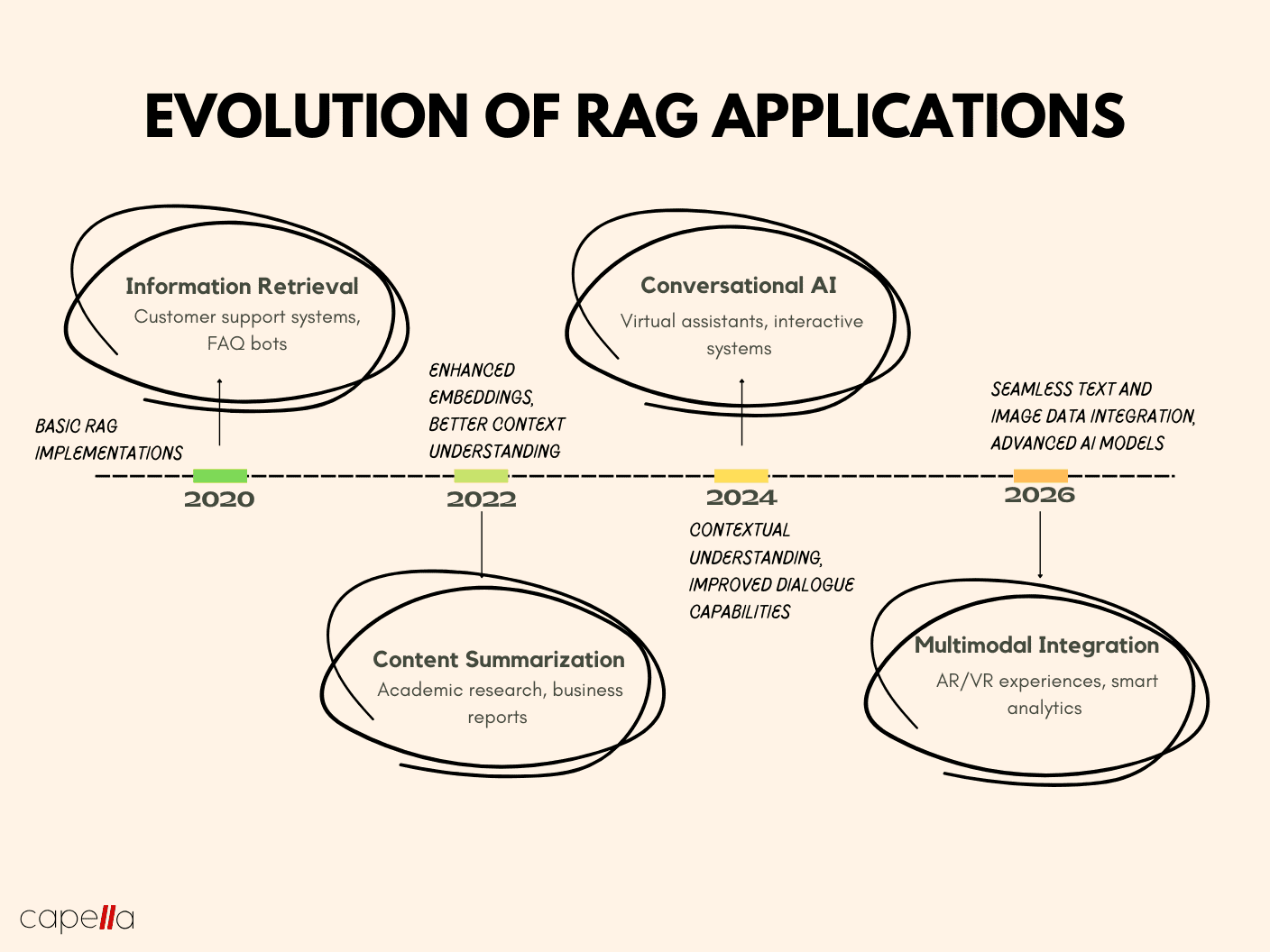
Image source: capellasolutions.com
Integrating Federated Learning with RAG
Federated learning (FL) offers a transformative approach to enhancing RAG systems by enabling decentralized model training across mobile devices. Unlike traditional methods, FL ensures that sensitive user data remains on-device, addressing privacy concerns while still improving model performance. This is particularly impactful in healthcare, where patient data can be used to fine-tune medical diagnostic models without violating confidentiality.
One critical challenge is maintaining retrieval accuracy across heterogeneous devices with varying computational capabilities. Techniques like adaptive federated optimization mitigate this by dynamically adjusting training loads based on device performance. For example, a study in personalized news delivery showed a 20% increase in user engagement when FL was combined with RAG, leveraging local preferences without centralizing data.
A lesser-known factor is the role of model drift. As user behavior evolves, FL frameworks must incorporate periodic global updates to prevent outdated retrieval patterns. This interplay between local adaptation and global consistency is key to scalable, effective RAG systems.
Edge Computing and Cross-Device Collaboration
Cross-device collaboration in edge computing leverages distributed resources to enhance RAG performance, particularly in scenarios requiring real-time data retrieval. A promising approach involves task partitioning, where computationally intensive retrieval tasks are offloaded to nearby devices or edge servers. This reduces latency and energy consumption on individual devices, as demonstrated in smart city applications where traffic data is processed collaboratively across IoT nodes.
One key enabler is federated orchestration, which dynamically assigns tasks based on device capabilities and network conditions. For instance, a retail application using RAG for personalized recommendations achieved a 40% reduction in response time by distributing retrieval workloads across in-store devices and edge servers.
However, synchronization challenges arise, especially with inconsistent network connectivity. Techniques like asynchronous task scheduling mitigate this by allowing partial updates, ensuring continuity even during disruptions. Moving forward, integrating blockchain for secure, decentralized coordination could further enhance trust and efficiency in cross-device RAG systems.
Enhancing Privacy and Security in Mobile RAG
A critical focus in mobile RAG systems is the implementation of differential privacy to protect sensitive user data during retrieval and generation processes. By introducing controlled noise into data queries and outputs, differential privacy ensures that individual user information cannot be reverse-engineered, even if the system is compromised. This approach has been successfully applied in healthcare apps, where patient data is anonymized while still enabling accurate diagnostic insights.
Another promising technique is secure multi-party computation (SMPC), which allows multiple devices to collaboratively process encrypted data without exposing raw inputs. For example, financial applications leveraging SMPC can perform fraud detection across distributed datasets without violating user confidentiality.
However, these methods often face computational overhead challenges. Combining them with hardware-based security modules, such as Trusted Execution Environments (TEEs), can offload cryptographic operations, improving efficiency. Future advancements in lightweight cryptographic algorithms could further optimize privacy-preserving RAG for mobile environments.
FAQ
What are the key challenges of implementing RAG on mobile devices?
Implementing RAG on mobile devices presents several key challenges.
First, the limited computational and memory resources of mobile hardware make it difficult to run both retrieval and generation components efficiently. Techniques like model quantization and pruning are essential but require careful balancing to avoid significant performance degradation.
Second, retrieval latency can be a bottleneck, especially when accessing external data sources. Solutions such as edge caching and approximate nearest neighbor (ANN) algorithms can help mitigate delays but may introduce trade-offs in accuracy.
Third, ensuring data privacy and security is critical, as mobile devices often handle sensitive user information. Robust measures like differential privacy and secure multi-party computation must be integrated without overwhelming the device’s processing capabilities.
Finally, the variability in mobile hardware and operating systems complicates the deployment of optimized RAG models, necessitating hardware-aware training and cross-platform compatibility strategies.
How does mobile hardware influence the performance of RAG systems?
Mobile hardware significantly influences the performance of RAG systems by imposing constraints on computational power, memory, and energy efficiency. Limited RAM and storage capacity restrict the size of language models and the volume of retrievable data that can be processed locally.
Thermal management is another critical factor, as prolonged high-intensity tasks can lead to overheating and performance throttling. Additionally, the diversity in mobile chipsets and architectures necessitates hardware-aware optimizations to ensure compatibility and efficiency.
Advanced processors, such as those with dedicated AI accelerators, can enhance RAG performance by enabling faster inference and retrieval operations. However, older or lower-end devices may struggle to meet the demands of RAG systems, requiring further model compression and optimization techniques to maintain usability.
What optimization techniques are most effective for mobile-optimized RAG models?
The most effective optimization techniques for mobile-optimized RAG models include model quantization, pruning, and knowledge distillation. Model quantization reduces the precision of weights and activations, significantly lowering computational and memory requirements while maintaining acceptable accuracy.
Pruning techniques, such as structured and progressive pruning, remove redundant neurons or layers, streamlining the model for mobile hardware. Knowledge distillation enables smaller models to replicate the performance of larger ones by transferring knowledge during training, ensuring high-quality outputs with reduced resource consumption.
Additionally, adaptive quantization and hardware-aware training further enhance efficiency by tailoring models to specific mobile chipsets. Techniques like edge caching and approximate nearest neighbor (ANN) search also optimize retrieval processes, minimizing latency and resource usage.
How can privacy and security be maintained in mobile RAG applications?
Privacy and security in mobile RAG applications can be maintained through a combination of robust technical measures and compliance with data protection regulations. Techniques such as differential privacy ensure that individual user data remains anonymized during processing, while secure multi-party computation enables collaborative data usage without exposing sensitive information.
Encryption of data both at rest and in transit is essential to prevent unauthorized access. Implementing strict access controls and role-based permissions further safeguards sensitive data. Regular security audits and penetration testing help identify and address vulnerabilities proactively.
Additionally, providing users with transparency and control over their data, such as the ability to opt out of data collection or request data deletion, fosters trust and compliance with regulations like GDPR and CCPA.
By integrating these measures, mobile RAG applications can achieve a balance between functionality and user privacy.
What are the most promising use cases for RAG in mobile environments?
The most promising use cases for RAG in mobile environments span various industries, leveraging its ability to provide real-time, contextually relevant information.
In healthcare, RAG can power clinical decision support systems, offering doctors instant access to patient data and the latest medical research for improved diagnostics and treatment planning.
E-commerce platforms benefit from RAG by delivering personalized product recommendations and real-time inventory updates, enhancing customer satisfaction and driving sales.
In education, RAG enables personalized learning experiences by tailoring content to individual student needs and providing instant access to educational resources. Customer support applications can utilize RAG to deliver accurate, up-to-date responses by integrating with company knowledge bases, reducing response times and improving user satisfaction.
Additionally, financial services can leverage RAG for tasks like fraud detection, risk assessment, and personalized financial advice, ensuring both efficiency and accuracy in decision-making processes.
These use cases highlight the transformative potential of RAG in mobile environments.