
Best Tools to Analyze Your RAG Knowledge Base
Analyzing your RAG knowledge base is key to optimizing retrieval and accuracy. This guide explores the best tools to evaluate performance, detect gaps, and enhance AI-driven knowledge management for more effective and reliable results.


In 2023, a financial institution’s RAG system made a costly mistake: It pulled outdated regulations for compliance checks. The AI wasn’t broken, but its knowledge base was. Inconsistent, cluttered, and full of irrelevant data, it turned a cutting-edge tool into a liability.
This exposed a hard truth: a RAG system is only as good as its knowledge base. No matter how advanced the model, the output will be unreliable if the underlying data is flawed.
Now, organizations are turning to specialized tools that clean, refine, and analyze knowledge bases to ensure accuracy and relevance.
These tools reshape how AI retrieves and generates information, from legal research to adaptive learning. Without them, even the most powerful RAG models risk losing credibility.
This article explores the best tools to analyze your RAG knowledge base. We will examine their key features, real-world applications, and how they improve retrieval accuracy.
Understanding these tools is essential for maintaining a RAG system that delivers precise, reliable, and context-aware responses.
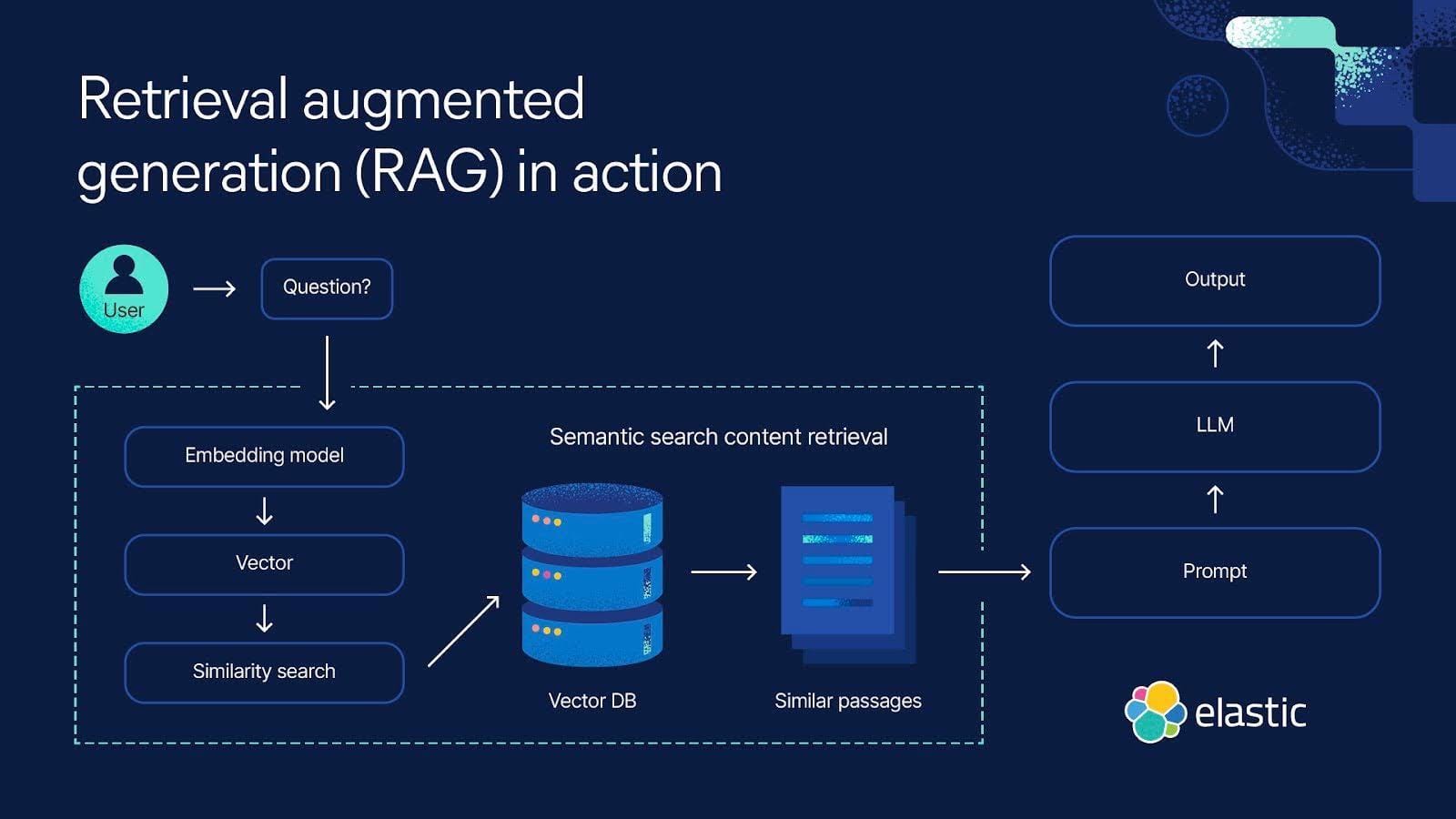
Components of RAG Architecture
A Retrieval-Augmented Generation (RAG) system consists of three key components: retrieval, reranking, and generation.
The retrieval mechanism searches a knowledge base for relevant information based on a query. Traditional keyword-based retrieval is common, but more advanced methods like dense passage retrieval (DPR) improve accuracy by matching queries with semantically similar documents using vector embeddings.
Once retrieval is complete, a reranking system sorts the retrieved documents based on their relevance to the query.
Rerankers use context-aware models to filter out noise and ensure only the most useful data is passed to the generative model. In domains like legal research and customer support, rerankers help prioritize high-quality sources, reducing irrelevant or misleading responses.
Metadata enrichment further refines retrieval accuracy by providing additional context. Tagging documents with structured metadata—such as timestamps, authorship, or domain-specific labels—enhances retrieval precision.
In medical applications, metadata-driven filtering ensures patient diagnoses align with the most up-to-date clinical guidelines.
The final stage is generation, where a language model synthesizes a response based on the retrieved and ranked documents. Effective RAG systems balance all three components to maintain accuracy, consistency, and domain-specific relevance. Organizations optimizing these elements can improve response quality, making RAG a powerful tool across industries.
Key Tools for RAG Analysis
Analyzing and optimizing a Retrieval-Augmented Generation (RAG) system requires tools that ensure data quality, improve retrieval efficiency, and refine generative accuracy.
These tools fall into three categories: vector databases, modular frameworks, and evaluation platforms.
Vector databases like Pinecone and Weaviate store and retrieve dense embeddings, enabling fast and precise query matching. They are essential for reducing search latency and improving retrieval accuracy in large-scale systems.
Frameworks such as LangChain and LlamaIndex provide modular architectures that allow developers to fine-tune RAG components. They support adaptive pipelines, enabling real-time optimization of retrievers, rerankers, and indexing strategies across different domains.
Evaluation platforms, including dynamic validation tools, help maintain dataset integrity and retrieval consistency. They prevent model drift by continuously monitoring knowledge base quality, ensuring retrieved data remains accurate and relevant.
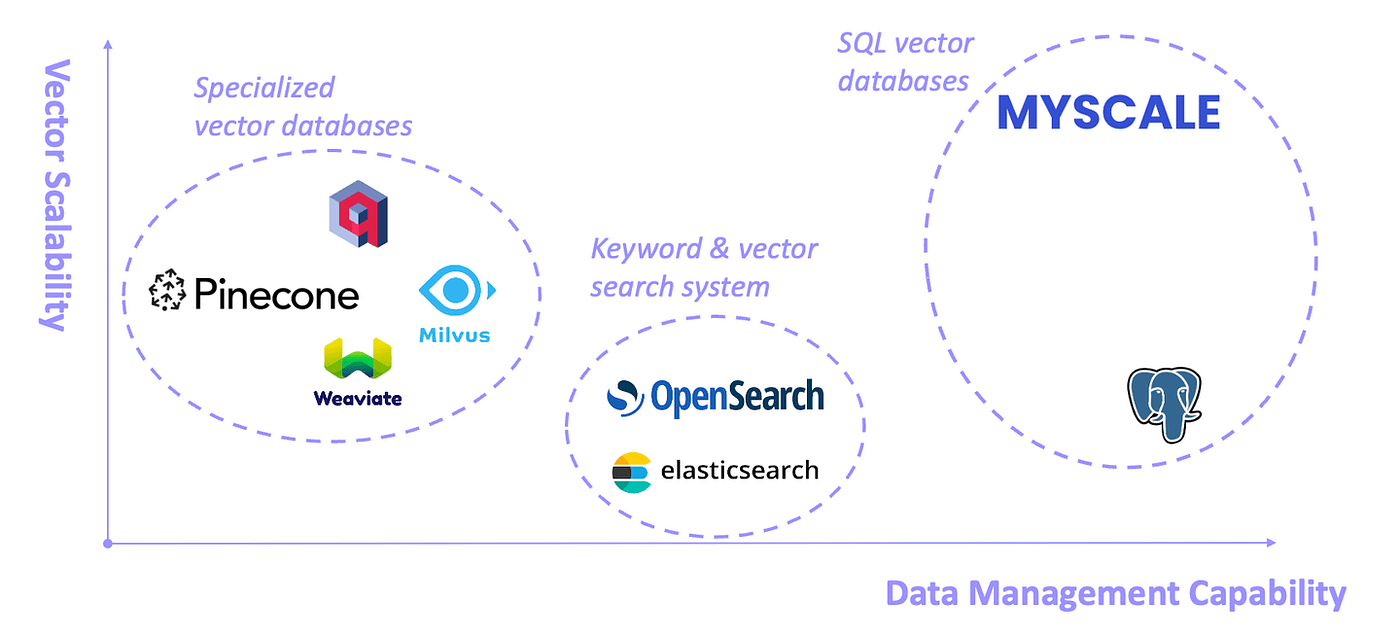
Vector Databases: Pinecone and Weaviate
Vector databases like Pinecone and Weaviate are pivotal in optimizing RAG systems by enabling efficient storage and retrieval of dense embeddings.
These databases excel in handling high-dimensional vector spaces, ensuring rapid and accurate query matching based on semantic similarity rather than keyword overlap.
Pinecone has demonstrated its value in e-commerce, where Shopify integrated it to enhance product recommendation systems. Pinecone’s real-time indexing capabilities also reduce latency, a critical factor in dynamic environments like online retail.
On the other hand, Weaviate offers a unique advantage with its built-in support for hybrid search, combining dense and sparse retrieval. Weaviate’s modular architecture allows seamless integration with domain-specific models, making it adaptable across industries.
These platforms' lesser-known yet impactful feature is their support for contextual filtering. By applying metadata constraints, organisations can refine search results to meet specific criteria.
Looking ahead, integrating adaptive feedback loops with these databases can further enhance retrieval precision, ensuring RAG systems remain robust and contextually aware in evolving use cases.
Frameworks: LangChain and LlamaIndex
LangChain and LlamaIndex are transformative frameworks for building modular, domain-specific RAG systems. Their ability to fine-tune individual components—retrievers, rerankers, and generators—enables unparalleled flexibility and scalability.
LangChain excels at creating adaptive pipelines for complex use cases. Its modular design allows seamless experimentation with retrieval strategies. A critical yet underutilized feature is its support for dynamic retriever swapping, which enables real-time adaptation to evolving datasets without disrupting workflows.
LlamaIndex (formerly GPT Index) specializes in indexing large, unstructured datasets for efficient retrieval. A notable application is its use by Bloomberg to enhance financial analysis tools.
LlamaIndex’s graph-based indexing further enhances retrieval precision by mapping relationships between data points, a feature particularly impactful in financial modeling.
Emerging trends suggest combining these frameworks with active learning loops to refine retrievers based on user feedback.
This approach improves accuracy and mitigates biases in sensitive domains like legal and finance. Organizations should prioritize hybrid implementations, leveraging LangChain’s modularity and LlamaIndex’s indexing capabilities to build robust, future-proof RAG systems.
Evaluating Retrieval Performance
Evaluating retrieval performance in RAG systems requires a nuanced approach that goes beyond traditional metrics like Recall@K or Mean Reciprocal Rank (MRR).
While these measures assess basic retrieval accuracy, they often fail to capture retrieved data's contextual relevance and real-world applicability.
A common misconception is that higher retrieval precision always equates to better outcomes.
However, reliability-weighted metrics, such as RA-RAG’s Reliability-Weighted Precision (RWP), reveal that balancing precision with trustworthiness is critical in high-stakes domains like finance.
Effective evaluation frameworks must prioritize relevance, coherence, and domain alignment, similar to a librarian curating books for a specific audience.
Integrating adaptive feedback loops and user-specific scoring models will ensure retrieval systems remain robust, equitable, and contextually aware.
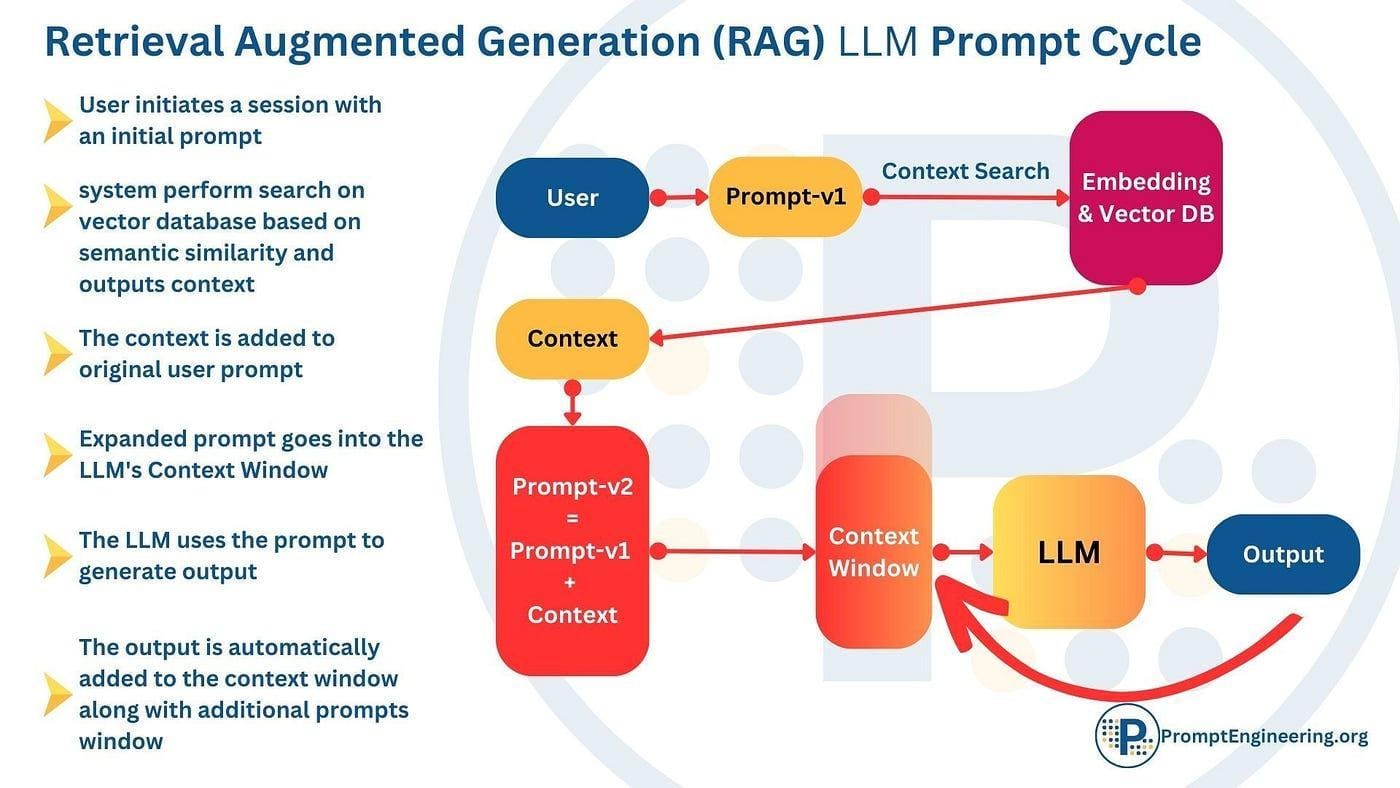
Metrics: Precision, Recall, and MRR
Precision, Recall, and Mean Reciprocal Rank (MRR) are foundational metrics for evaluating retrieval performance, yet their application in RAG systems reveals critical nuances.
While Precision measures the proportion of relevant documents among retrieved results, Recall evaluates the system’s ability to retrieve all relevant documents. MRR, on the other hand, emphasizes the rank of the first relevant result, making it particularly valuable in time-sensitive domains.
Emerging trends advocate for hybrid metrics like Reliability-Weighted Precision (RWP), which balance relevance with trustworthiness.
Advanced Retrieval Techniques
Advanced retrieval techniques, such as hybrid search and dense vector embeddings, have redefined the precision and adaptability of RAG systems.
Hybrid search, which combines dense and sparse retrieval methods, ensures both semantic understanding and keyword matching, addressing the limitations of standalone approaches.
A critical innovation is contextual reranking, where retrieved documents are dynamically prioritized based on query-specific relevance.
Emerging trends highlight adaptive retrieval pipelines, which incorporate user feedback to improve performance iteratively. These pipelines enhance accuracy and mitigate biases by continuously aligning retrieval strategies with evolving datasets.
Retrieval latency optimisation is a lesser-known yet impactful factor, crucial for real-time applications.
Organizations can reduce computational overhead without compromising accuracy by employing sparse retrieval models alongside dense embeddings.
Looking ahead, integrating neuro-symbolic AI with retrieval systems could unlock new possibilities, enabling the synthesis of structured and unstructured data.
Organizations should prioritize modular frameworks that support iterative refinement, ensuring scalability and contextual relevance in diverse applications.
Enhancing Response Generation
Enhancing response generation in RAG systems requires a nuanced balance between retrieval precision and generative fluency.
A pivotal insight is the role of retrieval-context alignment, where retrieved data must seamlessly integrate with the generative model’s linguistic and contextual capabilities.
A common misconception is that larger retrieval sets inherently improve response quality. Curated retrieval subsets often outperform broader datasets by reducing noise
Looking forward, integrating neuro-symbolic reasoning could further enhance coherence, enabling RAG systems to generate responses that are not only accurate but also contextually enriched.
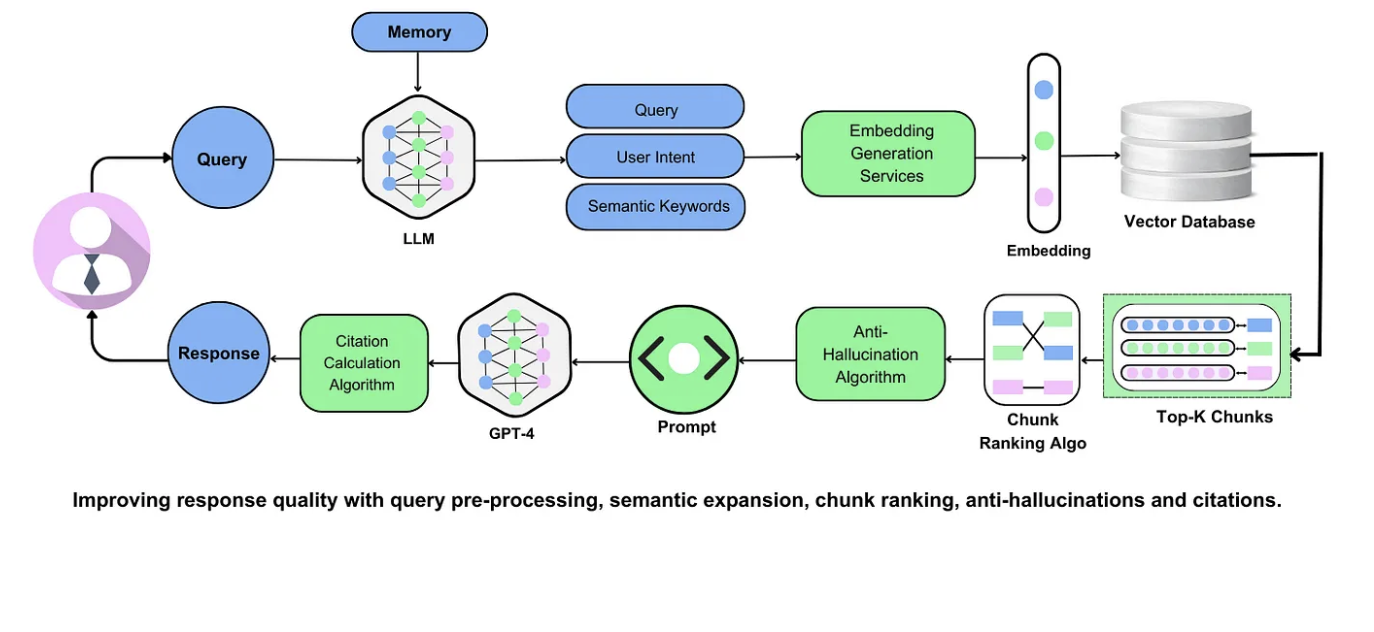
Role of Embedding Models
Embedding models are the cornerstone of effective response generation in RAG systems, transforming raw data into high-dimensional vectors that capture semantic meaning.
A critical advancement is the adoption of multi-functional embeddings, such as the M3-Embedding model, which supports dense, sparse, and multi-vector retrieval across over 100 languages.
This versatility enables seamless processing of diverse inputs, from short queries to documents spanning 8,192 tokens, ensuring robust retrieval-context alignment.
Granularity control is a lesser-known yet impactful factor, where embeddings adapt to varying input lengths.
This approach mitigates truncation issues, particularly in domains like legal research, where context-rich documents are critical.
Emerging trends also highlight embedding lifecycle management, ensuring vectors remain aligned with evolving datasets through continuous retraining.
Looking ahead, embedding models must integrate neuro-symbolic reasoning to bridge structured and unstructured data. Organizations should adopt embedding quality indexes—measuring semantic coherence, retrieval accuracy, and adaptability—to benchmark performance and drive innovation in response generation.
Optimizing Prompt Engineering
Prompt engineering is pivotal in maximizing the efficiency of RAG systems, as it directly influences the quality of generated responses.
A focused approach involves contextual prompt design, where prompts are tailored to align with domain-specific nuances.
A critical yet underexplored technique is dynamic prompt chaining, which breaks complex queries into smaller, sequential prompts.
Emerging trends highlight the importance of feedback-driven prompt optimization, where user interactions refine prompt structures over time. This iterative approach enhances system adaptability and mitigates biases in sensitive domains like finance and healthcare.
Organizations should adopt prompt evaluation indexes—measuring clarity, contextual alignment, and retrieval efficiency—to benchmark performance.
Integrating neuro-symbolic reasoning into prompt engineering could further enhance interpretability, enabling RAG systems to deliver precise and contextually enriched responses.
FAQ
What are the best tools for analyzing and optimizing a RAG knowledge base?
LangChain, Neo4j, and DataRobot help refine retrieval accuracy and structure knowledge bases. Pinecone and Weaviate support vector-based retrieval, while FAISS and Elasticsearch improve keyword search. Combining these tools with real-time feedback loops ensures relevant and high-performing RAG systems.
How do vector databases like Pinecone and Weaviate improve RAG performance?
Pinecone and Weaviate store and retrieve high-dimensional vector embeddings, enabling faster, more accurate search. Pinecone supports real-time indexing, while Weaviate blends keyword and semantic search. These databases enhance retrieval precision, reduce irrelevant results, and improve knowledge base relevance across industries.
What is the role of metadata in improving retrieval accuracy in RAG systems?
Metadata helps structure and filter retrieved data, ensuring relevance and reducing noise. Proper tagging aligns queries with context-specific information. Tools like Neo4j and Weaviate use metadata to refine retrieval, improving precision in applications like legal research and medical diagnostics.
How do LangChain and LlamaIndex optimize domain-specific RAG knowledge bases?
LangChain enables retriever customization, while LlamaIndex structures data for efficient searches. Both allow modular adjustments, making them useful for finance, healthcare, and legal applications. These frameworks ensure that retrieval remains accurate and aligned with evolving datasets.
What are the key metrics for evaluating RAG knowledge base quality?
Recall@K and Mean Reciprocal Rank (MRR) measure retrieval accuracy. FActScore assesses factual consistency, and Reliability-Weighted Precision (RWP) evaluates the trustworthiness of responses. Combining these with adaptive benchmarking and feedback loops ensures continuous retrieval and response accuracy improvement.
Conclusion
An RAG system's effectiveness depends on the accuracy of its knowledge base. Tools like LangChain, Pinecone, and Neo4j help optimize retrieval, while metadata structuring and real-time feedback improve response quality.
Organizations can apply adaptive evaluation metrics to ensure their RAG systems remain precise, scalable, and aligned with real-world applications.