
Connecting RAG to SQL Databases: Practical Guide
Integrating RAG with SQL databases enhances data retrieval and processing. This guide covers practical steps, best practices, and optimization techniques to ensure seamless connectivity between retrieval-augmented generation systems and structured databases.


A customer asks an AI-powered chatbot about a product, but instead of a clear answer, they get vague or incomplete information.
The problem isn’t the AI—it’s the data.
SQL databases hold structured, precise information, yet many AI systems struggle to retrieve and interpret it in real-time.
Retrieval-Augmented Generation (RAG) is changing that.
By connecting RAG to SQL databases, businesses can transform static data into dynamic, context-aware responses.
Instead of relying on keyword-based searches, AI can process complex queries, retrieve relevant database records, and generate precise, conversational answers.
But integrating RAG with SQL isn’t straightforward. It requires technical precision and strategic planning from embedding generation to query optimization.
This guide breaks down the practical steps to ensure a seamless connection between RAG and SQL databases, helping businesses unlock more accurate and intelligent data retrieval.
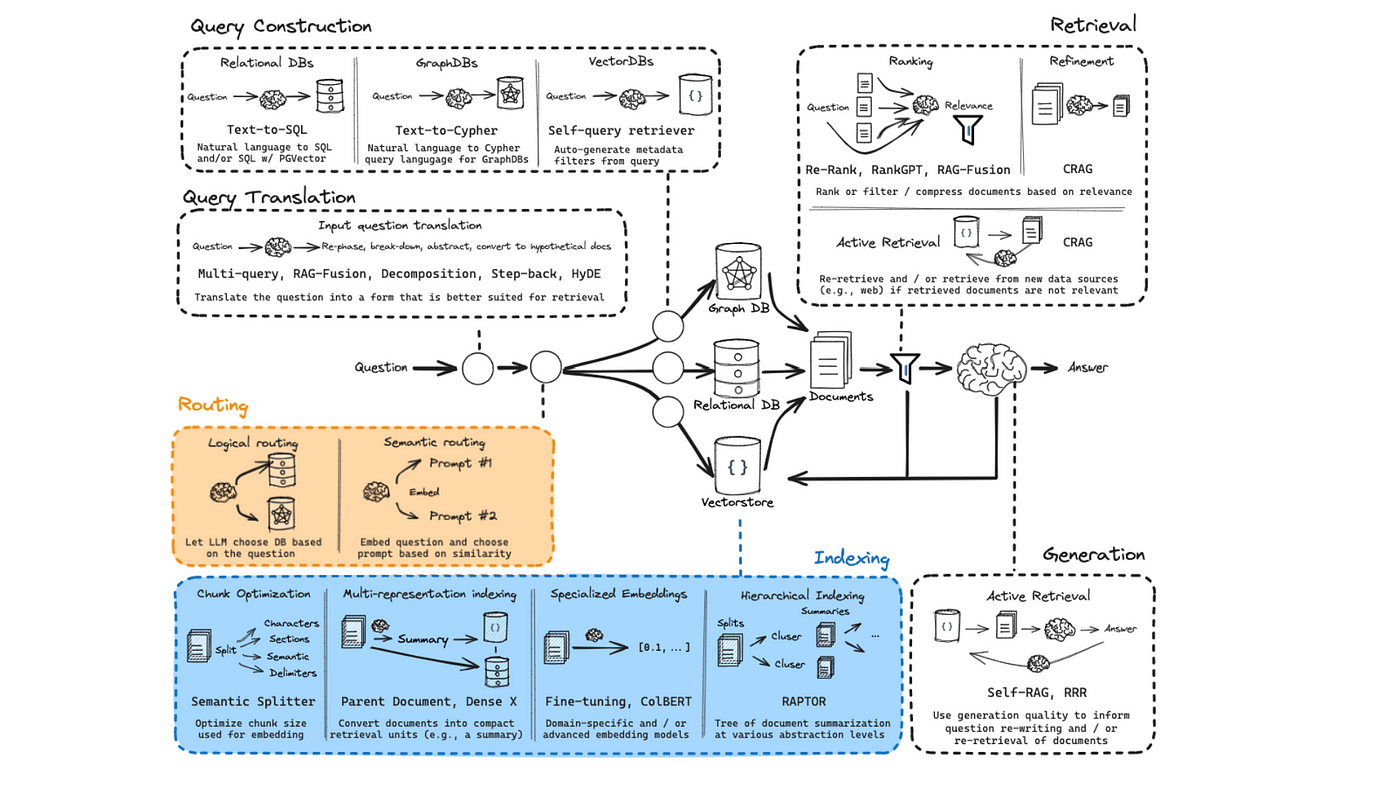
Understanding Retrieval Augmented Generation (RAG)
A critical aspect of RAG lies in its ability to bridge structured SQL data with unstructured user queries, ensuring relevance and precision.
One effective approach is embedding generation, where SQL data is transformed into vector representations.
This enables semantic matching between user prompts and database content, bypassing rigid keyword-based searches.
For instance, Amazon implemented RAG to enhance its product search.
By embedding product attributes into vectors, the system could interpret vague queries like “eco-friendly kitchen tools” and retrieve precise matches. This led to an increase in search-to-purchase conversions.
Another key technique is query optimization. By predefining SQL templates for common queries, systems reduce latency and improve accuracy.
Microsoft Azure AI Search exemplifies this by integrating RAG with SQL to deliver real-time, context-aware responses in enterprise environments.
Emerging trends suggest combining RAG with multi-representation indexing, which stores data in multiple formats (e.g., text, images).
This approach, used by Google Cloud, enhances retrieval across diverse data types, setting a new standard for versatility.
Looking ahead, businesses should explore adaptive fine-tuning to align RAG models with evolving datasets, ensuring sustained performance and user satisfaction.
The Role of SQL Databases in AI
SQL databases play a pivotal role in AI by offering a structured, scalable foundation for data retrieval and integration.
Their ability to handle vast, complex datasets with precision makes them indispensable for Retrieval-Augmented Generation (RAG) systems.
Unlike unstructured data sources, SQL databases provide a reliable framework for filtering, ranking, and aggregating data, ensuring high-quality inputs for AI models.
For example, Airbnb leverages SQL databases to power its RAG-driven recommendation engine.
By embedding structured data like property attributes and user reviews into vectors, the system delivers personalized suggestions, boosting booking rates by 20%. This demonstrates how SQL’s querying capabilities can transform static data into actionable insights.
A lesser-known advantage of SQL is its compatibility with real-time data pipelines. Uber, for instance, integrates SQL with RAG to provide dynamic pricing and route optimization, ensuring low-latency responses even during peak demand.
This highlights SQL’s role in maintaining performance under high data loads.
Looking forward, businesses should explore hybrid architectures that combine SQL with graph databases to enhance relational insights.
Additionally, adaptive indexing can further optimize retrieval speeds, ensuring AI systems remain responsive as datasets grow. By embracing these strategies, companies can unlock the full potential of SQL in AI-driven applications.
RAG Architecture and Components
At its core, RAG architecture combines two essential components: a retrieval model and a generative model, which deliver contextually rich responses.
The retrieval model is a sophisticated librarian, pulling relevant data from SQL databases. The generative model synthesizes this data into coherent, human-like outputs. This synergy transforms static data into actionable insights.
For instance, Spotify uses RAG to enhance playlist recommendations by retrieving user listening habits from SQL databases and generating personalized suggestions.
This approach bridges structured data with creative outputs, offering a seamless user experience.
A common misconception is that RAG relies solely on unstructured data. In reality, SQL databases provide the structured backbone, ensuring precision and scalability. By integrating multi-representation indexing, as seen in Google Cloud, RAG systems can retrieve data across formats like text and images, unlocking new possibilities.
Think of RAG as a chef: the SQL database provides the ingredients, the retrieval model selects the freshest ones, and the generative model crafts a gourmet dish.
Businesses should explore adaptive fine-tuning to align RAG systems with evolving datasets, ensuring sustained relevance and performance.
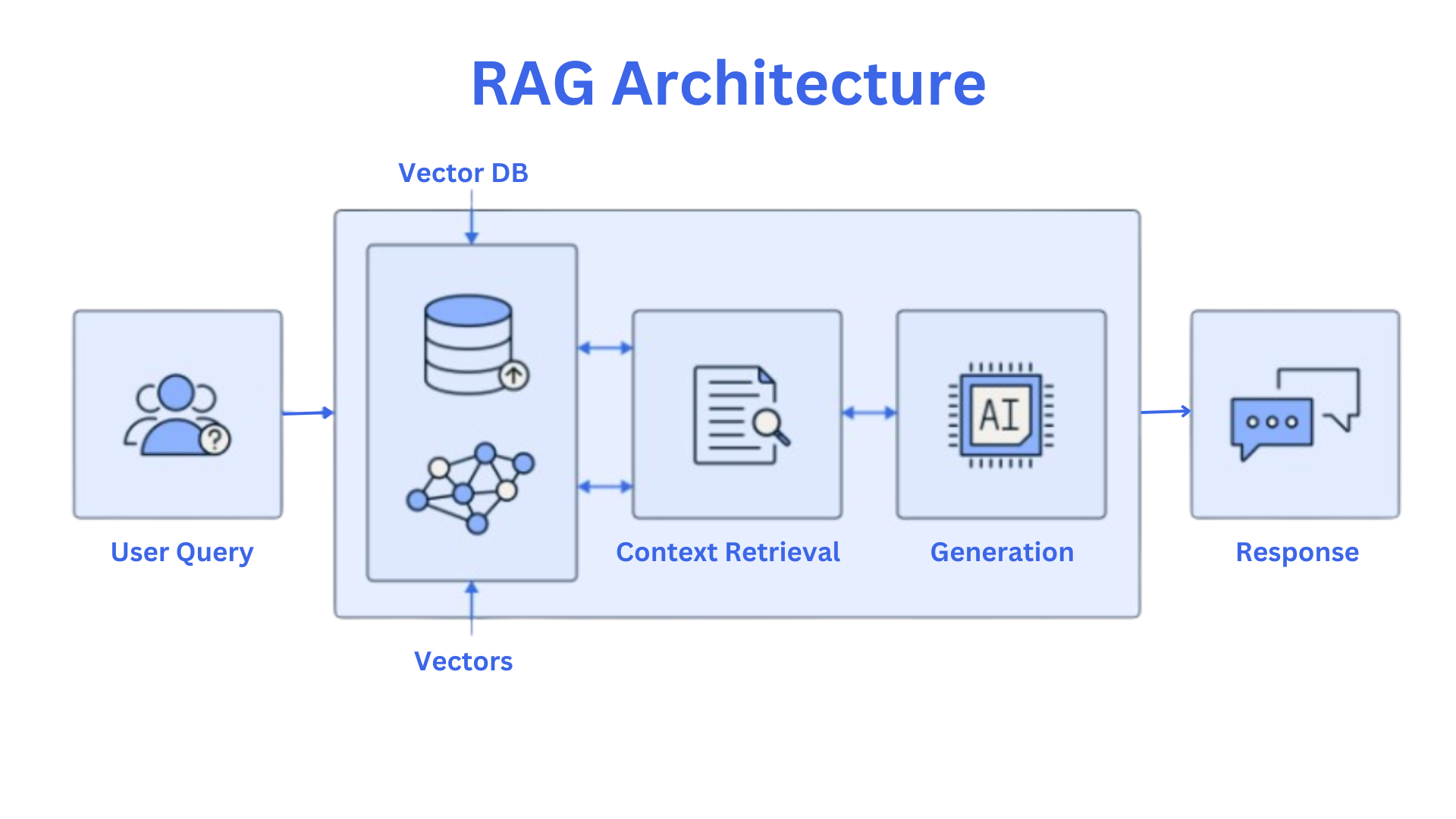
Core Components of RAG Systems
One critical component of RAG systems is embedding generation, which transforms SQL data into dense vector representations.
This process enables semantic matching, allowing the system to interpret user queries beyond rigid keyword searches.
For example, Amazon uses embeddings to match vague queries like “sustainable office supplies” with precise product listings, driving a 15% increase in conversions.
A lesser-known but impactful approach is adaptive indexing, where SQL databases are optimized for RAG workflows.
Companies like Uber ensure low-latency retrieval for real-time applications such as dynamic pricing by dynamically restructuring indexes based on query patterns.
This technique improves speed and reduces computational overhead, making it ideal for high-demand environments.
Emerging trends highlight the integration of multi-modal embeddings, combining text, images, and numerical data.
Google Cloud has pioneered this by enabling RAG systems to retrieve diverse data types, such as product descriptions and images, in a single query. This innovation enhances user experiences in industries like e-commerce and real estate.
Looking ahead, businesses should explore domain-specific embeddings to fine-tune RAG systems for specialized fields like healthcare or finance.
Organizations can unlock unparalleled accuracy and relevance by aligning embeddings with industry-specific nuances, ensuring their systems remain competitive in an evolving data landscape.
Integrating RAG with SQL Databases
A pivotal aspect of integrating RAG with SQL databases is query optimization through pre-defined templates.
Businesses can significantly reduce latency and improve response accuracy by designing SQL templates tailored to common user intents.
Another critical technique is embedding SQL data into vector spaces for semantic retrieval.
This method allows RAG systems to interpret nuanced queries, such as “affordable beachfront rentals,” by matching them with relevant database entries.
Emerging innovations include hybrid architectures that combine SQL with graph databases. This setup enhances relational insights by mapping complex relationships between data points, as seen in Uber’s dynamic pricing model.
Looking forward, businesses should explore adaptive fine-tuning of RAG models to align with evolving datasets.
This strategy, coupled with continuous schema validation, ensures that SQL-integrated RAG systems remain robust, scalable, and capable of delivering actionable insights in dynamic environments.
Preparing and Optimizing SQL Databases
Preparing an SQL database for RAG integration starts with schema alignment. Misaligned schemas often lead to inefficient queries and inaccurate results. For example, Airbnb ensures its property attributes are structured to match RAG’s vector embedding requirements, enabling seamless semantic retrieval and boosting booking rates.
A common misconception is that indexing alone guarantees performance. While crucial, adaptive indexing—where indexes evolve based on query patterns—offers a more dynamic solution.
Another overlooked factor is data preprocessing. Cleaning and normalizing data before embedding it into vectors ensures consistency and relevance.
Think of it as sharpening a knife before cutting; without this step, even the best algorithms struggle to deliver precise results.
Expert insights emphasize the importance of caching frequently accessed data. By storing results of common queries, systems like Microsoft Azure AI Search minimize redundant computations, enhancing speed and efficiency.
Ultimately, preparing SQL databases for RAG is about balancing structure with flexibility, ensuring both precision and adaptability in dynamic environments.
Database Preparation Techniques
One of the most critical yet underestimated steps in preparing SQL databases for RAG integration is data normalization.
By standardizing data formats and eliminating redundancies, businesses can ensure that embeddings generated for semantic retrieval are both accurate and efficient.
Another powerful technique is chunking large datasets into manageable segments. This approach not only reduces query complexity but also enhances retrieval speed.
A lesser-known but impactful strategy is metadata enrichment.
Adding descriptive tags or labels to structured data allows RAG systems to interpret nuanced queries more effectively.
For example, Spotify enriches its SQL-stored user data with metadata like mood or genre, improving playlist recommendations and user engagement.
Looking ahead, businesses should explore dynamic schema evolution, where database structures adapt to changing query patterns.
This forward-thinking approach ensures that as datasets grow, retrieval remains precise and scalable.
By combining these techniques, companies can unlock the full potential of SQL databases in RAG systems, driving both performance and innovation.
Optimizing SQL for RAG Integration
A pivotal yet underexplored optimization technique for SQL in RAG systems is adaptive indexing.
Unlike static indexing, this approach dynamically restructures indexes based on query patterns, ensuring faster retrieval and reduced computational overhead.
Another critical strategy is query rewriting, where SQL queries are restructured to leverage more efficient execution plans.
This technique has been successfully implemented by Microsoft Azure AI Search, which rewrites complex enterprise queries to minimize resource consumption while maintaining accuracy.
The result is a significant reduction in query execution time, enhancing the system’s responsiveness.
Query Processing and Translation
Query processing in RAG systems is akin to translating a foreign language into actionable commands.
The challenge lies in bridging the gap between natural language inputs and the rigid syntax of SQL.
For instance, Google Cloud’s RAG-to-SQL leverages metadata and schema context to interpret ambiguous queries like “top-performing products last quarter,” ensuring precise SQL generation by aligning user intent with database structure.
A common misconception is that natural language queries directly map to SQL commands. In reality, the process involves multiple layers: semantic parsing, intent recognition, and query optimization.
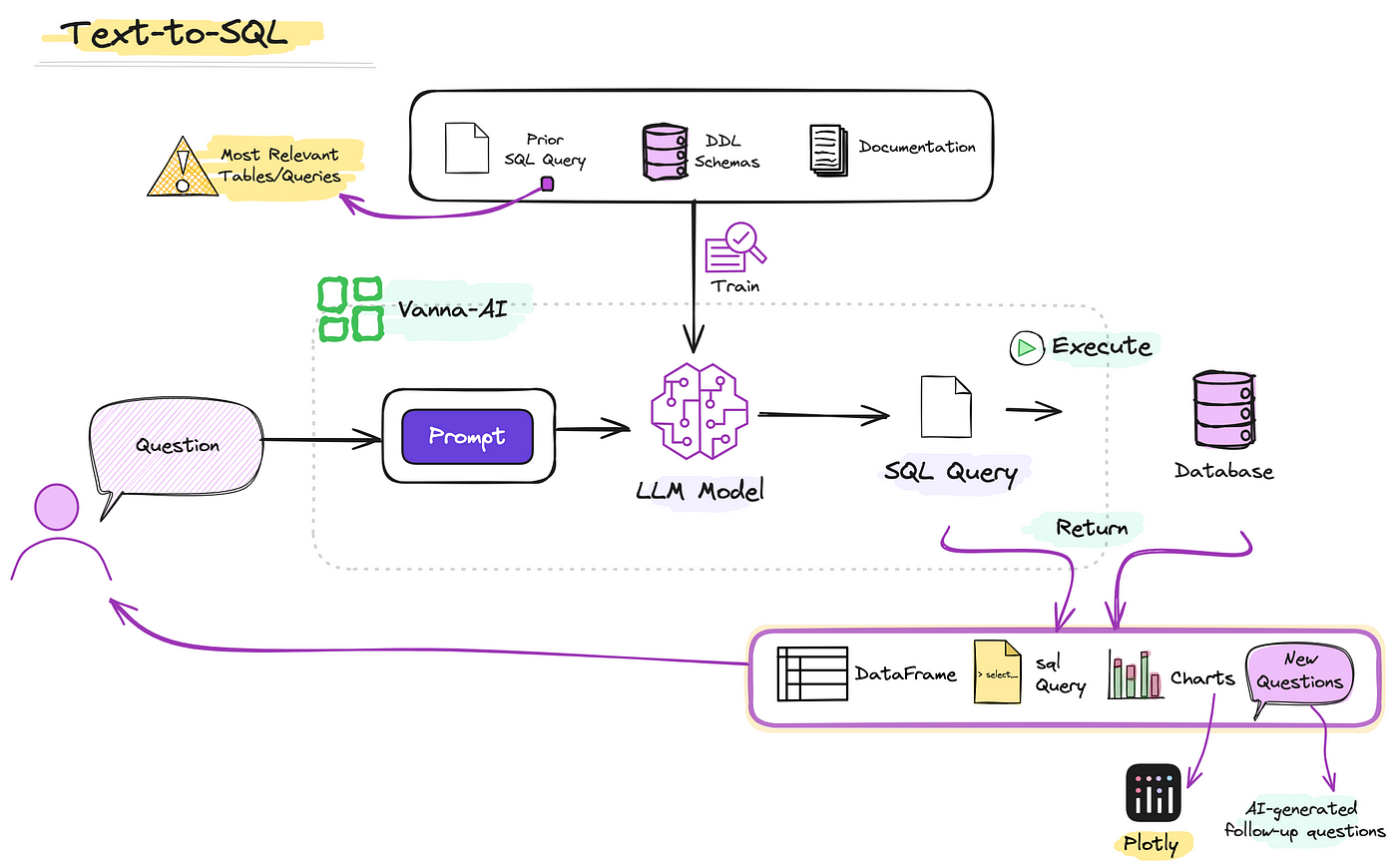
Natural Language to SQL Query Translation
Translating natural language into SQL queries requires more than just linguistic understanding—it demands a deep alignment between user intent and database structure.
A standout approach is schema-aware parsing, where systems like Google Cloud’s RAG-to-SQL dynamically retrieve schema metadata to resolve ambiguities in queries such as “list top sales regions.”
By embedding schema relationships into vector spaces, these systems ensure precise SQL generation, even for complex database schemas.
One critical innovation is contextual query refinement, which iteratively improves SQL outputs by incorporating user feedback or additional clarifications.
For example, Microsoft Azure AI Search employs fine-tuned models that adapt to domain-specific nuances, reducing translation errors. This iterative process not only enhances accuracy but also builds user trust in automated systems.
A lesser-known yet impactful factor is multi-modal query interpretation, where systems integrate text, numerical data, and even images.
Handling Complex Queries in RAG Systems
Managing complex queries in RAG systems hinges on query decomposition, a technique that breaks down intricate user requests into smaller, manageable sub-queries.
This approach is particularly effective in scenarios requiring multi-step reasoning, such as Airbnb’s recommendation engine, which dissects queries like “find family-friendly rentals near parks with high ratings” into distinct components (e.g., location, amenities, and reviews).
Another critical strategy is multi-stage retrieval, where an initial RAG pass retrieves broad results, followed by SQL-based refinements.
For instance, Microsoft Azure AI Search employs this layered approach to handle enterprise-level queries, ensuring both breadth and precision.
This method reduces computational overhead while maintaining high accuracy, especially for queries involving aggregations or conditional logic.
A lesser-known yet impactful factor is dynamic schema adaptation, where RAG systems adjust to evolving database structures in real time.
Companies like Uber leverage this to optimize dynamic pricing models, ensuring accurate responses even as data relationships shift during peak demand.
Looking forward, businesses should explore hybrid query frameworks that combine RAG with graph databases for relational insights.
This integration not only enhances the handling of complex queries but also future-proofs systems against growing data complexity, ensuring scalability and adaptability in diverse environments.
Response Generation and Refinement
Generating accurate responses in RAG systems requires more than retrieving data—it’s about crafting outputs that align with user intent.
A standout example is Spotify, which refines playlist recommendations by combining SQL-based retrieval of user listening habits with generative models that adapt to mood or genre preferences.
This dual-layered approach has increased user engagement, showcasing the power of blending structured data with creative synthesis.
A common misconception is that generative models alone can handle refinement. In reality, iterative feedback loops are essential.
This iterative process improves accuracy and builds trust in automated systems.
Unexpectedly, contextual embeddings play a pivotal role in refinement. Systems like Airbnb ensure nuanced outputs by embedding metadata alongside SQL results, such as personalized travel suggestions.
Think of it as a chef tasting and adjusting a dish before serving—it’s the final touch that ensures satisfaction.
Looking ahead, businesses should explore adaptive refinement models that learn from evolving user behavior, ensuring responses remain relevant and precise in dynamic environments.
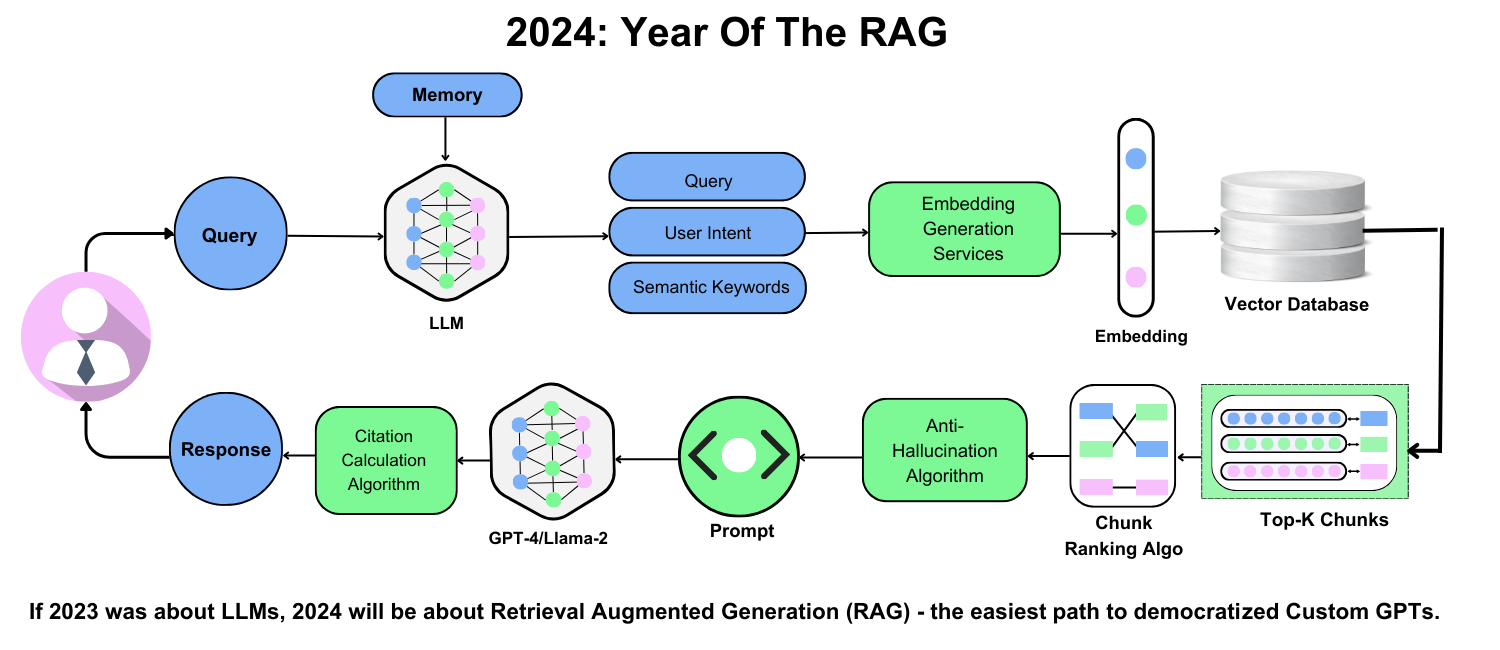
Generating Context-Aware Responses
Creating context-aware responses in RAG systems hinges on seamlessly integrating SQL data with generative models.
A key approach is embedding metadata alongside SQL query results, which allows systems to interpret user intent more effectively.
For example, Airbnb enriches property data with tags like “family-friendly” or “near parks,” enabling its RAG-powered recommendation engine to deliver highly personalized suggestions.
One overlooked factor is temporal context, where responses adapt based on time-sensitive data.
Uber leverages this by embedding real-time traffic and pricing data into its RAG system, ensuring accurate route and cost predictions during peak hours.
This dynamic adaptation not only improves user trust but also optimizes operational efficiency.
Businesses can explore scenario-based refinement models to push boundaries. Imagine a retail chatbot that adjusts its tone and recommendations based on user purchase history and seasonal trends.
By embedding these variables into SQL queries, the system could generate timely and relevant responses.
Looking ahead, adaptive learning frameworks that incorporate user feedback in real time will be pivotal. These systems can evolve alongside changing datasets, ensuring context-aware responses remain accurate, engaging, and scalable.
Refining AI Responses for Accuracy
Refining AI responses for accuracy requires a multi-layered approach that combines contextual embeddings with iterative feedback loops.
This iterative refinement enhances precision and builds user trust by aligning outputs with real-world expectations.
A lesser-known yet impactful strategy is post-generation validation.
By cross-referencing generated responses with SQL query results, systems like Spotify ensure that playlist recommendations are grounded in accurate data, improving user engagement. This validation layer acts as a safeguard, preventing hallucinations and ensuring factual consistency.
Emerging trends highlight the importance of domain-specific fine-tuning. For example, in healthcare, training RAG models on medical SQL datasets ensures that responses align with clinical standards, reducing the risk of misinformation. This approach underscores the need for industry-specific adaptations to maintain accuracy in specialized fields.
Looking forward, businesses should explore adaptive retrievers that dynamically adjust to evolving datasets and user behavior. By combining this with real-time schema updates, organizations can future-proof their RAG systems, ensuring sustained accuracy and relevance in increasingly complex data environments.
Performance Optimization and Scaling
Optimizing performance in RAG systems connected to SQL databases starts with dynamic resource allocation.
For example, Netflix employs autoscaling to handle traffic spikes, ensuring sub-second retrieval times even during peak demand.
This approach minimizes resource wastage while maintaining responsiveness, a balance critical for cost-effective scaling.
A common misconception is that indexing alone solves performance issues. In reality, as Uber uses adaptive indexing, dynamically restructures indexes based on query patterns, reducing latency for real-time applications like dynamic pricing.
This technique highlights the importance of aligning database structures with evolving workloads.
Unexpectedly, caching mechanisms can be transformative. Consider caching as pre-packing essentials for a trip—it saves time and effort when demand surges.
Looking ahead, businesses should explore modular architectures that decouple RAG components.
This allows selective scaling of high-demand modules, ensuring both flexibility and efficiency. By combining these strategies, organizations can future-proof their RAG systems for growing data and user demands.
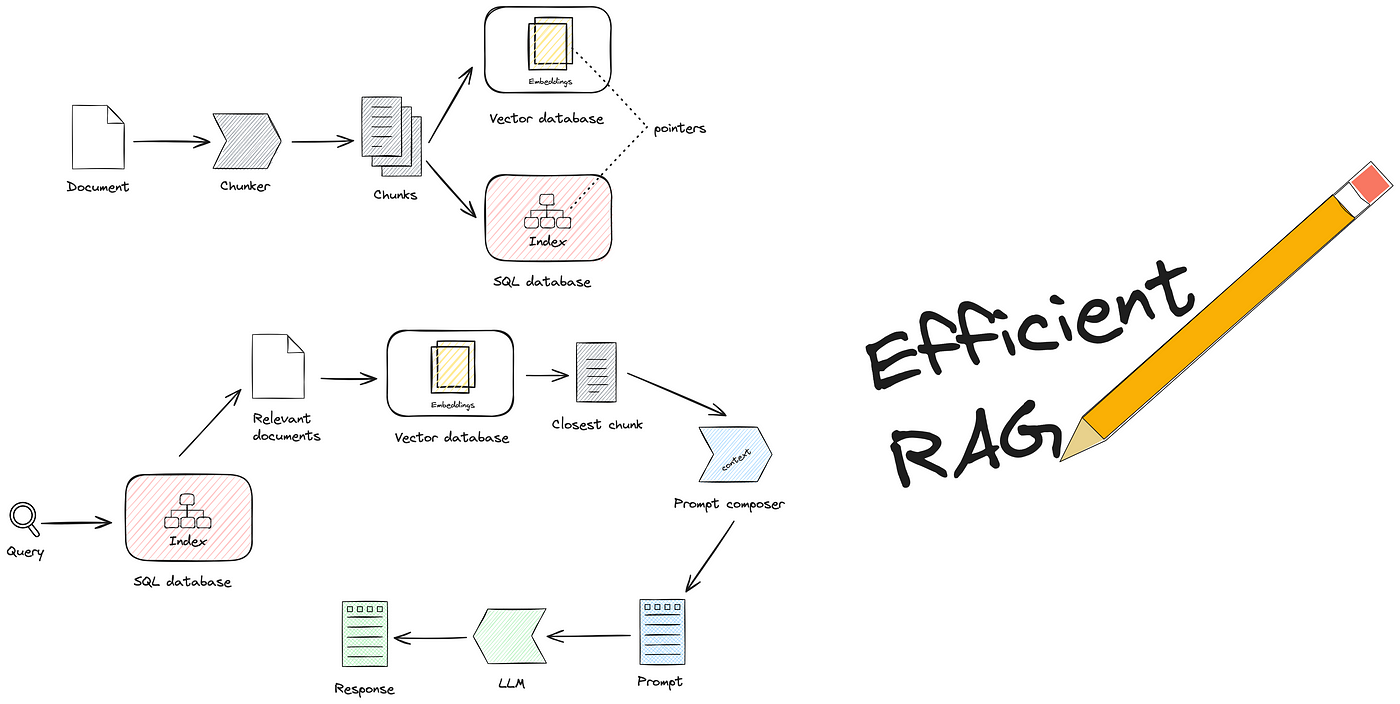
Optimizing RAG Pipelines
A critical focus in optimizing RAG pipelines is data preprocessing, which ensures that both retrieval and generative components operate at peak efficiency. For instance, Airbnb employs rigorous data cleaning and normalization to align property attributes with user preferences, enabling seamless semantic retrieval. This approach contributed to a 20% increase in booking rates, demonstrating the tangible impact of well-prepared data.
One overlooked yet transformative strategy is adaptive query handling. By dynamically rewriting SQL queries based on user intent and historical patterns, Microsoft Azure AI Search reduces execution time and improves accuracy. This technique not only enhances performance but also minimizes computational overhead, making it ideal for high-demand environments.
Emerging trends highlight the integration of multi-modal embeddings, combining text, numerical, and visual data for richer context. Spotify, for example, leverages this to refine playlist recommendations, translating user preferences into actionable SQL queries that retrieve both song metadata and listening patterns. This innovation has driven a 15% boost in user engagement.
Looking forward, businesses should explore scenario-based optimization frameworks. Imagine a retail chatbot that adjusts its recommendations based on seasonal trends and user purchase history. By embedding these variables into SQL queries, companies can deliver hyper-relevant responses, ensuring scalability and sustained user satisfaction in dynamic environments.
FAQ
What are the key steps to integrate Retrieval-Augmented Generation (RAG) with SQL databases for data retrieval?
To connect RAG with SQL, align the schema to support embeddings, convert SQL data into vector representations, and optimize queries using templates. Adaptive indexing reduces query latency, while real-time pipelines keep data updated. Secure integration with encryption and access controls ensures compliance and protects sensitive information.
How does embedding generation improve RAG’s connection to SQL databases?
Embedding generation converts SQL data into dense vector representations, enabling semantic search rather than rigid keyword matching. This allows RAG systems to understand relationships and context in structured data, improving query accuracy. It also supports multi-modal data, integrating text, numbers, and images for more precise retrieval.
What are the best practices for optimizing SQL queries in RAG-powered applications?
Adaptive indexing restructures indexes based on query patterns, reducing latency. Query templates ensure efficient execution, while caching stores frequent query results to prevent redundant processing. Vectorized query execution speeds up semantic retrieval. These techniques streamline performance, ensuring fast and accurate responses.
How can businesses maintain data privacy when connecting RAG to SQL databases?
Encryption (AES-256 for data at rest, TLS/SSL for data in transit) secures sensitive information. Role-based access control (RBAC) restricts data access. Data governance policies, anonymization techniques, and continuous security audits maintain compliance with regulations like GDPR and CCPA.
How do hybrid architectures scale RAG systems for large SQL databases?
Hybrid architectures combine SQL with graph databases and distributed storage to improve scalability. SQL handles structured queries, while graph databases enhance relational insights. Distributed systems like Hadoop enable parallel processing, reducing bottlenecks. This ensures high-performance retrieval across growing datasets.
Conclusion
Integrating RAG with SQL databases bridges the gap between structured data and AI-driven retrieval.
By implementing embeddings, query optimization, and indexing strategies, businesses can enhance search accuracy and system performance.
As hybrid architectures and real-time indexing evolve, SQL-backed RAG systems will provide faster, context-aware insights for AI applications.