
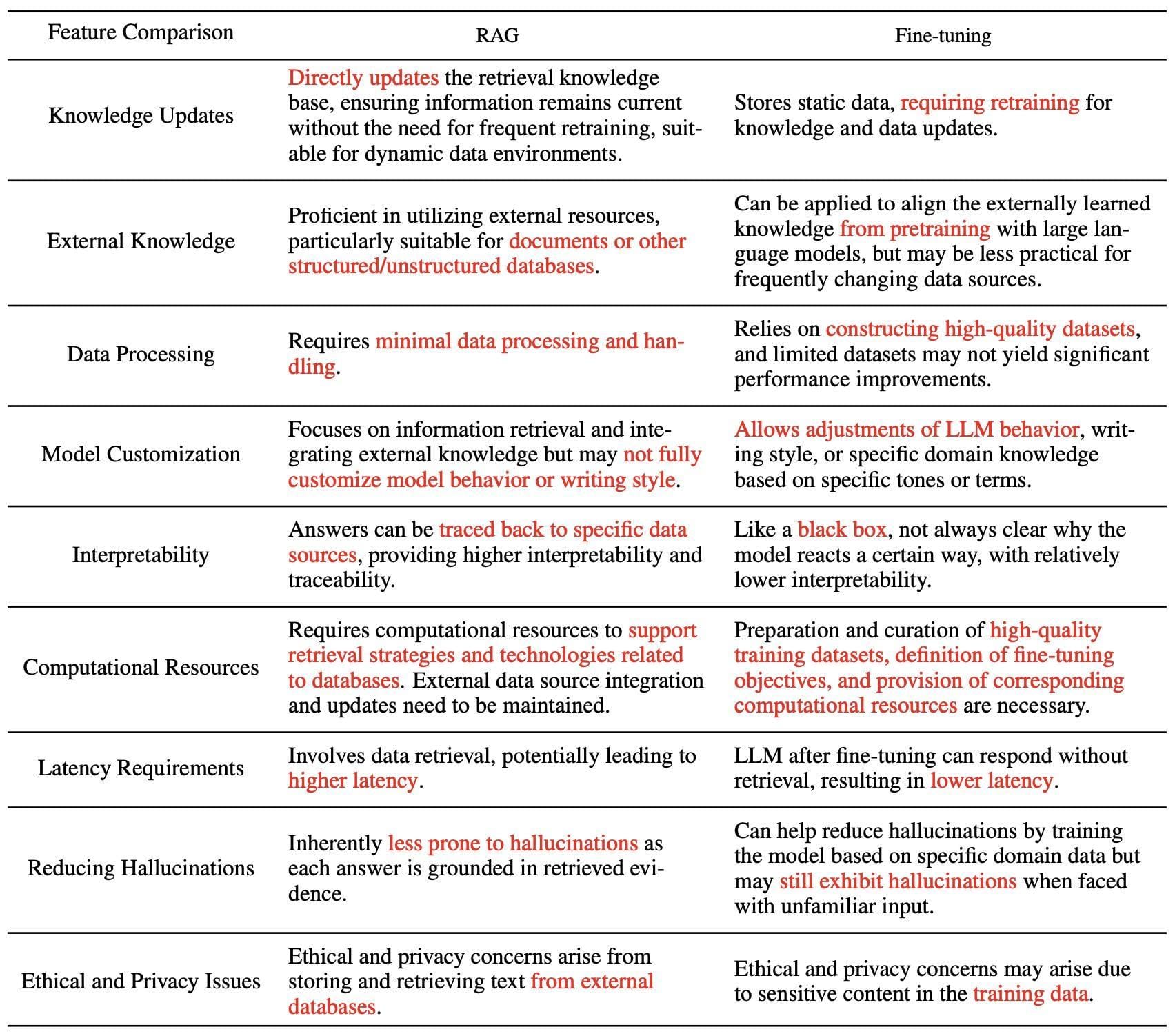
RAG vs Finetuning vs Prompt Engineering: A Comprehensive Comparison
Ever wonder why some AI solutions feel like magic while others fall flat? In this comparison of RAG, Finetuning, and Prompt Engineering, explore the power behind each method and find out how to pick the perfect path for your AI breakthrough.



A cutting-edge AI model, trained on terabytes of data, confidently delivers an answer—only for you to discover it’s outdated or completely wrong. This isn’t a rare glitch; it’s a systemic limitation of static training data. As businesses increasingly rely on AI for critical decisions, the stakes couldn’t be higher. How do we ensure these models stay relevant, accurate, and adaptable in real time?
Enter three transformative techniques: Retrieval-Augmented Generation (RAG), Fine-Tuning, and Prompt Engineering. Each promises to bridge the gap between static AI capabilities and dynamic, real-world demands. But here’s the catch—choosing the right approach isn’t just a technical decision; it’s a strategic one, with implications for cost, scalability, and precision.
This article unpacks the nuances of these methods, exploring not just their mechanics but their broader impact on how we harness AI in an ever-changing world. Which path will you take? Let’s find out.
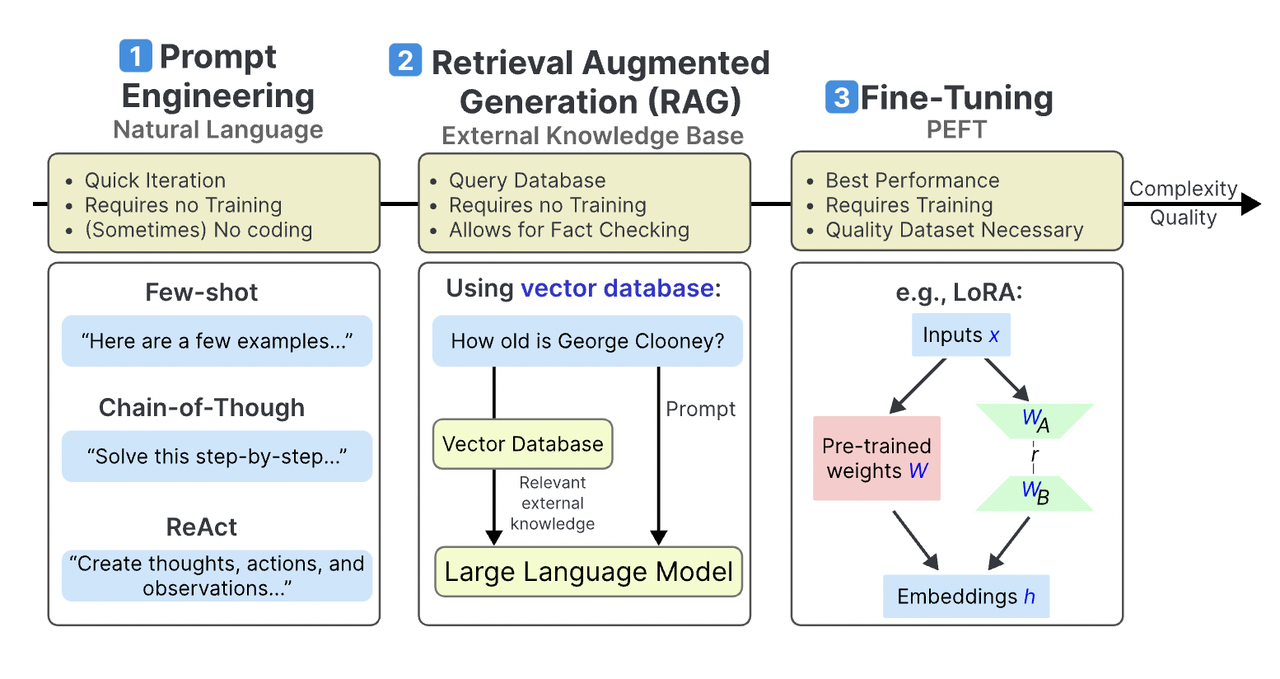
Defining RAG, Finetuning, and Prompt Engineering
At their core, RAG, Fine-Tuning, and Prompt Engineering tackle the same challenge: how to make AI models more relevant and effective. But their mechanisms couldn’t be more different. RAG, for instance, thrives on real-time adaptability by integrating external knowledge bases. This makes it indispensable for industries like healthcare, where up-to-date research can mean the difference between accurate diagnoses and outdated advice.
Fine-Tuning, on the other hand, excels in precision. By retraining models on domain-specific datasets, it creates bespoke solutions for niche applications—think legal analysis or financial forecasting. However, its reliance on curated data and computational resources often limits scalability, making it a high-investment choice.
Prompt Engineering flips the script entirely. Instead of altering the model, it optimizes the input. This lightweight approach is ideal for rapid prototyping but struggles with complex, domain-specific tasks.
Significance in AI Language Models
The significance of RAG, Fine-Tuning, and Prompt Engineering lies in their ability to address the inherent limitations of static AI models. RAG, for example, bridges the gap between pre-trained models and real-world relevance by integrating external, dynamic data sources. This capability is transformative in fields like customer support, where real-time updates ensure accurate responses to evolving queries.
Fine-Tuning, however, shines in scenarios demanding domain-specific expertise. By retraining models on curated datasets, it enables unparalleled accuracy in tasks like legal document analysis or medical diagnostics. Yet, its high resource demands often make it impractical for applications requiring rapid scalability.
Prompt Engineering offers a minimalist yet effective alternative. By refining input prompts, it enhances model outputs without altering the underlying architecture. This approach is particularly valuable in creative industries, such as content generation, where flexibility outweighs precision.
The interplay of these techniques suggests a hybrid future, leveraging their strengths to overcome individual limitations.
Foundations of Language Model Adaptation
Adapting language models hinges on three core techniques—RAG, Fine-Tuning, and Prompt Engineering—each addressing unique challenges in AI customization. At its heart, adaptation is about bridging the gap between generic model capabilities and specific, real-world needs. For example, RAG excels in dynamic environments like e-commerce, where integrating live inventory data ensures accurate recommendations.
Fine-Tuning, by contrast, transforms a generalist model into a domain expert. A case in point: fine-tuned models in healthcare have demonstrated up to 30% improved diagnostic accuracy when trained on specialized datasets. However, this precision comes at a cost—high computational demands and reduced flexibility for new tasks.
Prompt Engineering offers a lightweight alternative, akin to crafting a well-phrased question to elicit the best answer. Yet, its effectiveness often depends on the user’s expertise, making it less intuitive for non-technical stakeholders. Together, these methods reveal a spectrum of trade-offs, underscoring the importance of context-driven decision-making.
Overview of Language Models
One overlooked aspect of language models is their reliance on context windows—the amount of text they can process at once. This limitation directly impacts the effectiveness of techniques like RAG, which depends on retrieving and integrating external data. For instance, in legal research, RAG systems often struggle when case law exceeds the model’s context window, requiring creative solutions like chunking or summarization.
Fine-Tuning, while powerful, introduces another challenge: catastrophic forgetting. When models are fine-tuned on niche datasets, they risk losing general knowledge. This is particularly problematic in industries like finance, where both domain-specific insights and broader economic trends are critical.
Prompt Engineering sidesteps these issues but introduces its own: prompt drift. Over time, as prompts grow more complex, they can inadvertently confuse the model, reducing output quality. Addressing these nuances requires a hybrid approach—leveraging RAG for real-time data, Fine-Tuning for precision, and Prompt Engineering for adaptability.
Challenges in Model Adaptation
For RAG, the retrieval system’s ability to fetch relevant, high-quality data hinges on the alignment between the knowledge base and the model’s training data. Misaligned datasets can lead to contradictory outputs, especially in dynamic fields like healthcare, where outdated or inconsistent information can have serious consequences.
Fine-Tuning faces a different hurdle: dataset bias. Even well-curated datasets can inadvertently reinforce biases, limiting the model’s applicability across diverse user groups. For example, fine-tuned customer support models may fail to generalize to multilingual or culturally nuanced queries, reducing their effectiveness in global markets.
Prompt Engineering, while flexible, struggles with contextual ambiguity. Subtle variations in phrasing can drastically alter outputs, making it unreliable for high-stakes applications like legal document drafting. Addressing these challenges requires robust validation pipelines and interdisciplinary collaboration to ensure ethical, accurate, and scalable model adaptation strategies.
Criteria for Technique Comparison
RAG excels in dynamic environments by leveraging external knowledge bases, but its computational overhead can strain systems with limited infrastructure. For instance, small-scale e-commerce platforms may struggle to implement RAG effectively, despite its potential to enhance product recommendations with real-time data.
Fine-Tuning, while precise, often falters in scalability due to its reliance on extensive datasets and computational power. This makes it impractical for startups or projects with tight budgets. However, in fields like legal services, where accuracy outweighs cost, fine-tuning remains indispensable.
Prompt Engineering offers unmatched accessibility, requiring minimal resources. Yet, its reliance on iterative refinement can lead to inefficiencies in time-sensitive scenarios, such as crisis management. A hybrid framework—combining RAG for real-time insights, fine-tuning for domain-specific accuracy, and prompt engineering for adaptability—can address these trade-offs, ensuring both scalability and performance across diverse applications.
Retrieval-Augmented Generation (RAG)
RAG is like equipping a language model with a personal librarian—one that retrieves the most relevant books in real time. By integrating external knowledge bases, RAG ensures outputs are not only accurate but also up-to-date. For example, in healthcare, RAG-powered systems can pull the latest treatment guidelines during patient consultations, bridging the gap between static training data and evolving medical research.
A common misconception is that RAG is prohibitively complex. While it does require robust infrastructure, advancements in vector databases and embedding models have streamlined implementation. Tools like Pinecone and Weaviate simplify the retrieval process, making RAG accessible even to mid-sized enterprises.
RAG’s reliance on external data introduces a unique challenge: data quality. Poorly curated sources can lead to misinformation. This highlights the need for precise prompt engineering to guide retrieval systems effectively. When done right, RAG transforms static AI into a dynamic, context-aware assistant, redefining real-time applications.
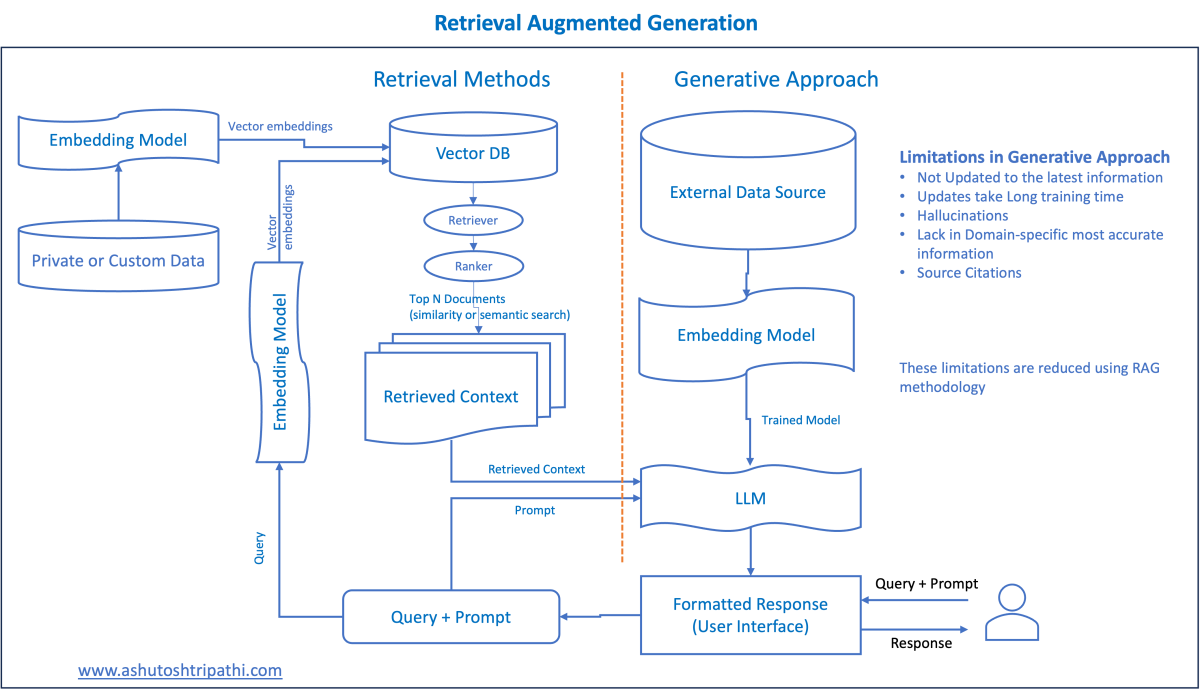
Understanding RAG Mechanisms
At its core, RAG operates through two tightly interwoven processes: retrieval and generation. The retrieval phase uses advanced techniques like dense vector search or semantic embeddings to locate the most contextually relevant data from external sources. This ensures that the model’s outputs are grounded in real-world, up-to-date information. For instance, legal tech platforms leverage RAG to pull case law precedents, enabling lawyers to craft arguments with unparalleled precision.
What sets RAG apart is its ability to balance breadth and depth. Unlike static fine-tuned models, RAG dynamically adapts to queries, but this flexibility depends heavily on retrieval quality. Factors like embedding accuracy, database structure, and ranking algorithms can significantly influence outcomes.
Retrieval latency can bottleneck performance. To mitigate this, organizations are exploring hybrid approaches, combining local caching with cloud-based retrieval. This not only accelerates response times but also enhances scalability, making RAG a cornerstone for real-time AI systems.
Architecture and Workflow
The architecture of RAG hinges on the seamless integration of retrieval systems and language models. Fusion mechanism—how retrieved data is combined with the input query before generation. Techniques like attention-based weighting allow the model to prioritize the most relevant retrieved information, significantly improving output accuracy. For example, in healthcare, RAG systems can synthesize patient histories with real-time medical guidelines to provide actionable insights.
However, the workflow’s success depends on data preprocessing. Splitting documents into optimal chunk sizes ensures efficient retrieval without overwhelming the model’s context window. This step is often overlooked, yet it directly impacts retrieval precision and latency.
Balancing retrieval depth with speed. Emerging solutions, such as hierarchical retrieval pipelines, address this by layering coarse-to-fine search strategies. Moving forward, integrating multimodal data (e.g., text and images) into RAG workflows could unlock new possibilities in fields like diagnostics and personalized education.
Advantages and Limitations of RAG
One advantage of RAG is its ability to reduce hallucinations in language models by grounding outputs in retrieved, factual data. This is particularly impactful in high-stakes fields like legal or medical applications, where accuracy is non-negotiable. For instance, a legal assistant powered by RAG can retrieve case law precedents, ensuring its advice is both relevant and verifiable.
However, a key limitation lies in retrieval bias. The quality of outputs heavily depends on the diversity and alignment of the external knowledge base. If the retrieval system favors outdated or skewed sources, the generated content inherits these flaws, undermining reliability.
To mitigate this, organizations should implement dynamic knowledge base updates and robust filtering mechanisms. Additionally, integrating user feedback loops can refine retrieval accuracy over time. Looking ahead, combining RAG with reinforcement learning could further enhance its adaptability, making it a cornerstone for real-time, domain-specific AI solutions.
Practical Applications of RAG
One standout application of RAG is in customer support automation. By integrating RAG with proprietary knowledge bases, companies can deliver real-time, context-aware responses to user queries. For example, e-commerce platforms use RAG to retrieve product-specific details, such as warranty policies or return procedures, ensuring accurate and personalized customer interactions.
RAG can retrieve and synthesize data from vast, domain-specific repositories, enabling researchers to quickly access relevant studies or datasets. This reduces time spent on literature reviews and accelerates hypothesis generation.
However, success hinges on retrieval precision. Poorly curated knowledge bases can lead to irrelevant or misleading outputs. To address this, organizations should adopt semantic search techniques and continuously refine their data sources.
Looking forward, combining RAG with multimodal inputs—like images or graphs—could unlock new possibilities in fields like healthcare diagnostics and financial analysis, driving innovation across industries.
Finetuning
Finetuning transforms a general-purpose language model into a domain-specific expert. By exposing the model to curated datasets, it learns to generate outputs tailored to niche applications. For instance, a finetuned model for legal analysis can parse contracts with precision, identifying risks or inconsistencies that generic models might overlook.
However, the process is resource-intensive. It demands substantial computational power and high-quality datasets, which are often expensive to compile. A common misconception is that finetuning guarantees perfection; in reality, poorly designed datasets can entrench biases, limiting the model’s applicability across diverse scenarios.
An unexpected advantage of finetuning is its ability to retain stylistic consistency. For example, media companies use it to generate content that aligns with their brand voice. Yet, experts caution against overfitting, where the model becomes too specialized and loses general knowledge—a phenomenon akin to memorizing answers without understanding the questions.
To mitigate risks, iterative validation and diverse datasets are essential.
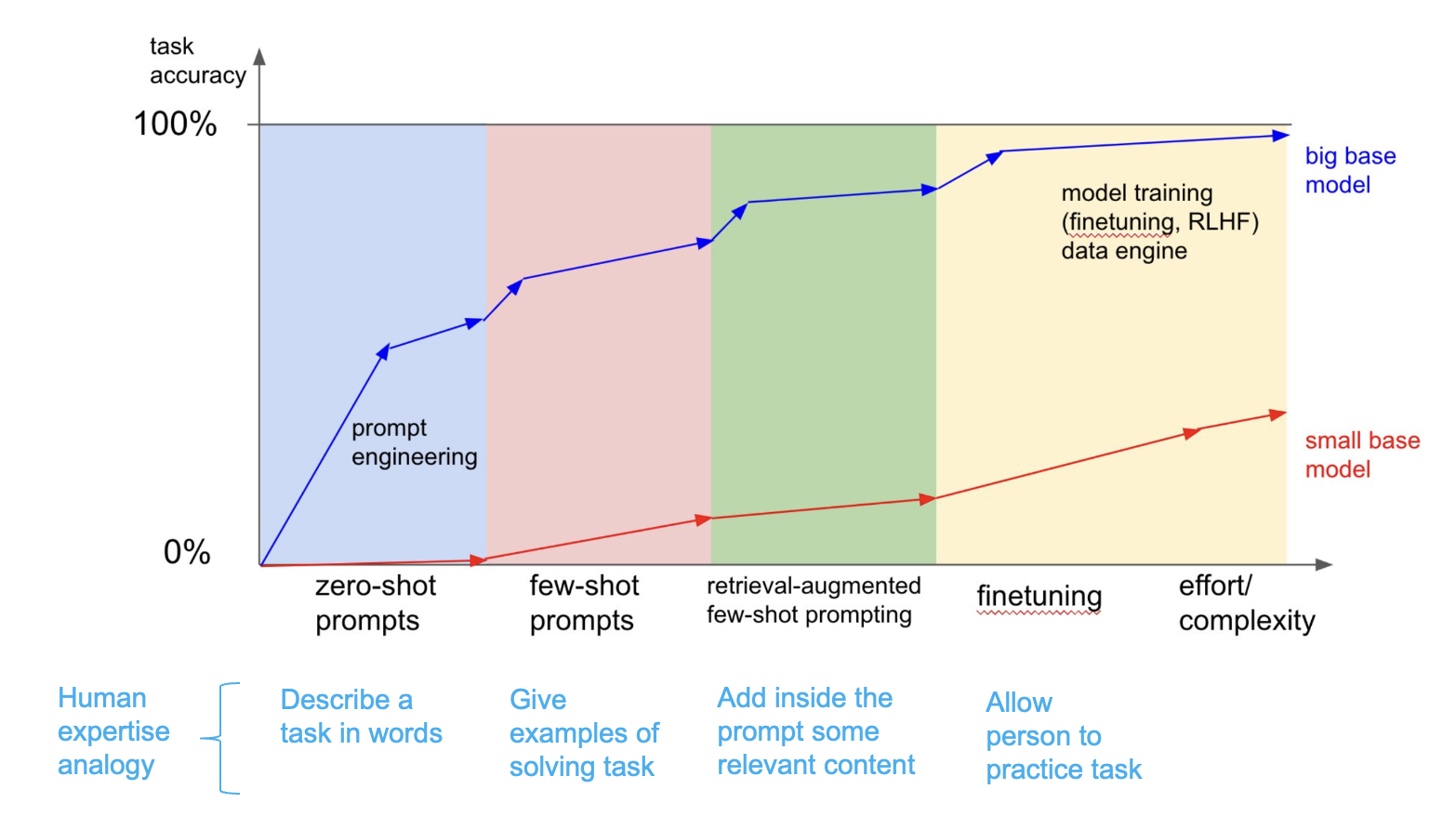
The Concept of Finetuning
Finetuning operates on the principle of specialized learning, where a pre-trained model is adapted to excel in a specific domain. Unlike general training, which prioritizes breadth, finetuning hones in on depth. For example, in healthcare, finetuned models trained on radiology datasets can identify anomalies in medical imaging with remarkable accuracy, outperforming generic AI systems.
The quality and diversity of the dataset directly influence the model’s performance. Over-reliance on narrow datasets can lead to overfitting, where the model becomes too rigid to handle edge cases. This is why industries like finance often employ hybrid datasets—combining historical data with simulated scenarios—to ensure robustness.
Interestingly, finetuning also intersects with transfer learning. By leveraging pre-trained knowledge, it reduces training time and costs. For practitioners, the actionable takeaway is clear: prioritize dataset quality and iterative testing to balance precision with adaptability.
Methods and Techniques
One standout technique in finetuning is instruction-based finetuning, where models are trained using detailed task-specific instructions. This approach excels in scenarios requiring procedural knowledge, such as legal document analysis or step-by-step troubleshooting in technical support. By embedding explicit instructions into the training data, the model learns not just the “what” but the “how,” improving interpretability and task execution.
LoRA (Low-Rank Adaptation) reduces computational overhead by fine-tuning only a subset of the model’s parameters. This makes it ideal for resource-constrained environments, such as startups or edge computing applications. For instance, LoRA has been successfully applied in personalized recommendation systems, where rapid adaptation to user preferences is critical.
The interplay between instruction-based finetuning and transfer learning reveals a key insight: combining these methods can amplify efficiency and accuracy. Practitioners should explore modular finetuning frameworks to balance cost, scalability, and precision.
Advantages and Limitations of Finetuning
A critical advantage of finetuning is its ability to mitigate bias in pre-trained models. By retraining on domain-specific, labeled datasets, finetuning aligns model outputs with real-world expectations, reducing disparities in sensitive applications like hiring algorithms or medical diagnostics. This targeted approach ensures the model adapts to nuanced contexts, outperforming generic models in accuracy and fairness.
When finetuning on narrow datasets, models risk losing general knowledge acquired during pretraining. This is particularly problematic in multi-domain applications, such as financial forecasting, where both domain-specific and general insights are essential. Techniques like progressive freezing—where earlier layers of the model remain untouched—help mitigate this issue.
Finetuning’s success hinges on dataset quality and diversity. Practitioners should prioritize data augmentation strategies to enhance robustness. Moving forward, hybrid approaches combining finetuning with retrieval-based systems could balance precision and adaptability, unlocking broader use cases.
Implementation Examples
One compelling implementation of finetuning is in healthcare diagnostics. By training models on curated datasets of radiology images, finetuning enables AI to detect anomalies like tumors with remarkable precision. This approach works because the model learns domain-specific patterns, such as subtle differences in tissue density, that generic pre-trained models might overlook. For instance, fine-tuned models have been used to identify early-stage cancers, significantly improving patient outcomes.
Finetuning on annotated legal texts allows models to parse complex clauses, assess risks, and even draft contracts. This is particularly effective in jurisdictions with unique legal frameworks, where pre-trained models often fail to generalize.
To maximize success, practitioners should integrate active learning—iteratively refining datasets based on model errors. This not only enhances accuracy but also reduces dataset bias. As industries demand higher precision, finetuning combined with real-time data retrieval could redefine AI’s role in specialized fields.
Prompt Engineering
Prompt engineering is the art of crafting precise inputs to guide AI models toward desired outputs. Think of it as giving a chef a detailed recipe instead of vague instructions—specificity drives better results. For example, in customer support, prompts structured as “If the user asks about refunds, provide policy details in bullet points” can significantly improve response clarity and relevance.
A common misconception is that prompt engineering is simple. In reality, it requires a deep understanding of the model’s behavior. For instance, chain-of-thought prompting—where the model is guided step-by-step—has been shown to improve reasoning tasks by 30% in benchmark tests.
Interestingly, prompt engineering bridges creativity and logic. It’s not just about asking questions but designing scenarios that unlock the model’s potential. As AI evolves, this technique will likely intersect with disciplines like linguistics and psychology, offering new ways to optimize human-AI interaction.
Principles of Prompt Engineering
Unlike static instructions, prompts often require multiple iterations to align outputs with user intent. For instance, in legal document analysis, starting with a broad query like “Summarize this contract” may yield generic results. Refining it to “Highlight clauses related to termination and penalties” narrows the focus, improving relevance and utility.
By embedding key details within the prompt—such as “You are a financial advisor analyzing investment risks”—models can generate domain-specific insights. This approach mirrors priming in psychology, where initial cues shape subsequent responses.
Prompt engineering also thrives on feedback loops. Systematic evaluation of outputs, using metrics like accuracy or user satisfaction, ensures continuous improvement. Tools like prompt templates or A/B testing frameworks can streamline this process, making it scalable for production environments.
Ultimately, these principles emphasize adaptability, blending technical precision with creative problem-solving.
Techniques and Best Practices
A pivotal technique in prompt engineering is chain-of-thought prompting. By structuring prompts to guide the model through step-by-step reasoning, this approach enhances logical coherence. For example, instead of asking “What is the total cost?”, a prompt like “First calculate the tax, then add it to the base price to find the total cost” ensures more accurate outputs. This mirrors procedural thinking in disciplines like mathematics or programming.
Another best practice is leveraging few-shot prompting. By including examples within the prompt, such as “Translate: ‘Bonjour’ → ‘Hello’”, the model learns task-specific patterns without additional training. This technique is particularly effective in multilingual applications or niche domains.
Finally, contextual anchoring—embedding constraints or goals directly in the prompt—can mitigate ambiguity. For instance, specifying “Respond in 50 words or less” ensures concise outputs, critical for applications like SMS-based customer support.
These methods underscore the importance of precision and adaptability, paving the way for more robust AI-human collaboration.
Advantages and Limitations of Prompt Engineering
Unlike fine-tuning, which demands computational resources and technical expertise, prompt engineering allows non-technical users to achieve meaningful results. For instance, a marketing team can craft prompts to generate ad copy without needing to retrain the model, saving both time and budget. This democratization of AI usage aligns with broader trends in no-code solutions.
Small changes in phrasing can lead to drastically different outputs, introducing inconsistency. For example, asking “Summarize this article” versus “Provide a brief overview” may yield varying levels of detail. This unpredictability can hinder applications requiring high reliability, such as legal document analysis.
To address this, organizations should adopt iterative prompt testing frameworks. By systematically refining prompts and incorporating user feedback, teams can enhance output stability while maintaining cost efficiency. This approach bridges accessibility with precision, unlocking new possibilities.
Comparative Analysis
Each technique—RAG, fine-tuning, and prompt engineering—offers distinct advantages, but their effectiveness hinges on context. Think of them as tools in a craftsman’s kit: RAG is the precision saw, fine-tuning the custom mold, and prompt engineering the versatile wrench. The choice depends on the task at hand.
For instance, RAG thrives in dynamic environments like financial markets, where real-time data retrieval ensures outputs remain current. However, its reliance on external databases introduces latency, a critical drawback in time-sensitive applications. Fine-tuning, by contrast, excels in specialized domains such as legal analysis, where models trained on proprietary datasets deliver unparalleled accuracy. Yet, its high cost and risk of overfitting make it less viable for smaller projects.
Prompt engineering, while cost-effective, struggles with complex workflows. A poorly crafted prompt can derail outcomes, akin to misdirecting a GPS. Combining these methods—e.g., using RAG for retrieval and fine-tuning for precision—often yields the best results.
Performance Across Techniques
When evaluating performance, contextual relevance emerges as a decisive factor. RAG excels in scenarios requiring real-time updates, such as medical diagnostics, where retrieving the latest research ensures accuracy. However, its dependency on retrieval quality can lead to inconsistencies if the external database is poorly maintained or biased.
Fine-tuning, on the other hand, shines in predictable, domain-specific tasks. For example, a fine-tuned legal model can parse contracts with near-human precision. Yet, its Achilles’ heel lies in scalability—training costs and risks of overfitting often outweigh its benefits for rapidly evolving fields.
Prompt engineering offers unmatched agility but struggles with output stability. In creative industries, such as content generation, it enables rapid prototyping. However, subtle prompt variations can yield wildly different results, complicating high-stakes applications.
A hybrid approach—leveraging RAG for dynamic data, fine-tuning for precision, and prompt engineering for flexibility—can mitigate these trade-offs, offering a tailored solution for complex workflows.
Cost and Resource Considerations
While RAG reduces training expenses by leveraging external databases, maintaining these databases—ensuring they are current, unbiased, and comprehensive—requires significant investment. For instance, in financial services, outdated or incomplete datasets can lead to costly errors in market predictions.
Fine-tuning demands upfront computational resources and expertise, but its long-term costs can escalate due to retraining needs in dynamic fields. A healthcare application, for example, may require frequent updates to incorporate new medical guidelines, making fine-tuning less cost-effective over time.
Prompt engineering, though low-cost initially, incurs indirect costs in high-stakes environments. Iterative testing to refine prompts can drain time and human resources, especially in industries like legal services, where precision is paramount.
A cost-efficient framework might combine RAG for dynamic data, fine-tuning for static domains, and prompt engineering for rapid prototyping, balancing short- and long-term resource demands.
Suitability for Different Applications
The granularity of customization is a pivotal factor in determining the suitability of these techniques across applications. Fine-tuning excels in domains requiring highly specialized outputs, such as medical diagnostics or legal document analysis, where precision outweighs flexibility. For example, a fine-tuned model trained on oncology datasets can identify rare cancer markers with unparalleled accuracy.
RAG, on the other hand, thrives in dynamic environments where real-time data is critical. In e-commerce, RAG-powered chatbots can retrieve up-to-date inventory details, ensuring accurate customer interactions. However, its reliance on external data sources introduces risks like latency and retrieval bias, which must be mitigated through robust infrastructure.
Prompt engineering shines in creative and exploratory tasks, such as content generation or brainstorming. Its adaptability makes it ideal for industries like marketing, where rapid prototyping is essential.
A hybrid approach—leveraging RAG for real-time insights, fine-tuning for depth, and prompt engineering for flexibility—can maximize application-specific outcomes.
Future Outlook and Developments
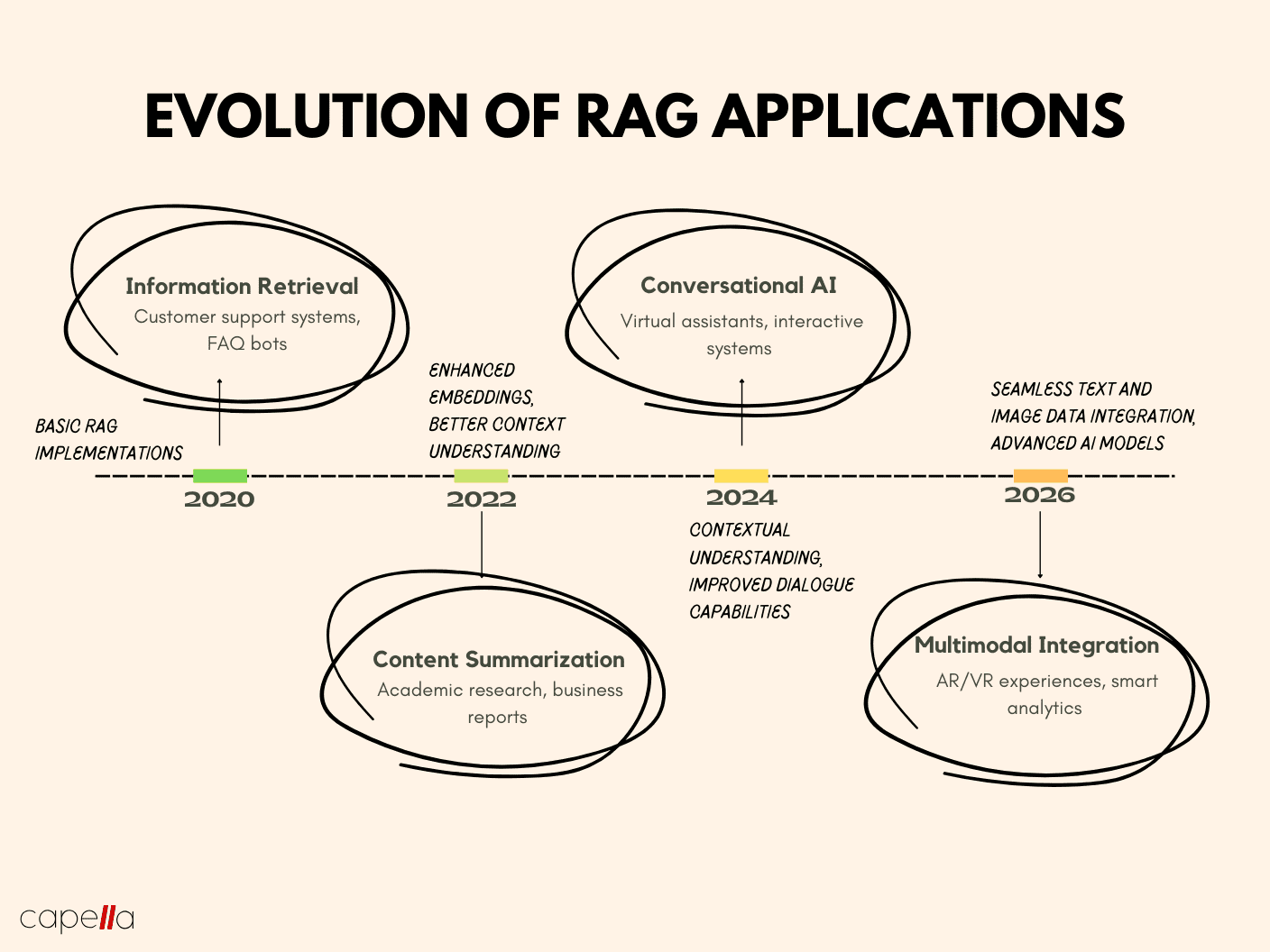
The integration of multimodal capabilities is set to redefine the landscape of RAG, fine-tuning, and prompt engineering. As AI systems increasingly process text, images, and audio simultaneously, RAG could leverage diverse data sources—like combining real-time video feeds with textual databases—to enhance applications in fields like autonomous vehicles or telemedicine. This shift demands advancements in retrieval algorithms to handle multimodal data efficiently.
Fine-tuning may evolve with parameter-efficient techniques like LoRA, enabling domain-specific adaptation without extensive computational overhead. This could democratize access for smaller organizations, particularly in industries like education, where tailored AI models can revolutionize personalized learning.
Prompt engineering, meanwhile, is likely to benefit from automated prompt optimization tools. These tools could reduce human effort in crafting effective prompts, making the technique more scalable for creative industries.
The convergence of these methods, supported by innovations in hardware and software, will likely drive AI toward unprecedented levels of adaptability and precision.
Advanced Applications and Implications
RAG, fine-tuning, and prompt engineering are reshaping industries in ways that often go unnoticed. For instance, in precision agriculture, RAG-powered systems integrate satellite imagery with real-time weather data to guide planting decisions. This dynamic adaptability contrasts sharply with fine-tuned models, which excel in static, high-accuracy tasks like soil nutrient analysis but lack real-time responsiveness.
In healthcare, fine-tuning has enabled breakthroughs in diagnostic AI, such as models trained on rare disease datasets. However, a common misconception is that fine-tuning always outperforms RAG. In reality, RAG’s ability to retrieve the latest medical research during consultations often proves more practical in fast-evolving fields like oncology.
Prompt engineering has found unexpected success in creative industries. For example, marketing teams use chain-of-thought prompting to generate nuanced ad campaigns tailored to diverse audiences.
The interplay of these techniques highlights a critical insight: no single approach dominates; their synergy unlocks transformative potential.
Combining Techniques for Enhanced Performance
The synergy of RAG, fine-tuning, and prompt engineering unlocks capabilities that surpass the sum of their parts. For example, in legal research, RAG retrieves up-to-date case law, while fine-tuned models analyze legal language nuances. Prompt engineering then refines the query to ensure outputs are both precise and actionable, streamlining workflows for attorneys.
Fine-tuning thrives on domain-specific datasets, but integrating RAG ensures these models stay relevant by pulling real-time updates. This combination is particularly effective in industries like finance, where static models often fail to adapt to market volatility.
Conventional wisdom suggests these techniques operate independently, but evidence shows their integration reduces latency and improves accuracy. A practical framework involves using RAG for dynamic inputs, fine-tuning for task-specific expertise, and prompt engineering to bridge gaps in contextual understanding. This layered approach not only enhances performance but also future-proofs AI systems.
Ethical and Legal Considerations
The integration of RAG, fine-tuning, and prompt engineering raises critical concerns about data provenance. For instance, RAG relies on external data sources, but without rigorous vetting, it risks propagating misinformation or violating intellectual property rights. This is particularly problematic in industries like healthcare, where inaccurate data could lead to harmful outcomes.
Fine-tuning on domain-specific datasets can inadvertently amplify biases present in the training data. When combined with prompt engineering, subtle prompt variations may unintentionally reinforce these biases, leading to ethically questionable outputs in sensitive applications like criminal justice.
Conventional wisdom often overlooks the legal accountability of AI outputs. A robust framework should include transparent data sourcing, bias audits, and compliance checks. By embedding these safeguards, organizations can mitigate risks while fostering trust in AI systems.
Emerging Trends in AI Model Adaptation
One emerging trend is the rise of parameter-efficient fine-tuning methods like LoRA (Low-Rank Adaptation). These techniques reduce computational overhead by updating only a subset of model parameters, making fine-tuning accessible for smaller organizations. This shift democratizes AI customization, enabling industries like education to deploy tailored models without prohibitive costs.
Another key development is the integration of multimodal data in RAG workflows. By combining text, images, and even sensor data, RAG systems are evolving to provide richer, context-aware outputs. For example, in supply chain management, multimodal RAG can analyze text-based reports alongside real-time video feeds to optimize logistics.
Conventional approaches often neglect the role of automated prompt optimization. Emerging tools now leverage reinforcement learning to refine prompts dynamically, improving output quality over time. Organizations should explore hybrid frameworks that combine these trends, ensuring adaptability while minimizing resource constraints. This approach positions AI systems for long-term scalability and innovation.
FAQ
1. What are the key differences between RAG, Fine-Tuning, and Prompt Engineering?
RAG, Fine-Tuning, and Prompt Engineering differ in approach, customization, and resource needs.
- RAG integrates external knowledge bases with pre-trained models for real-time, accurate outputs, ideal for dynamic tasks like customer support but requires external infrastructure.
- Fine-Tuning adapts models to specific datasets by modifying internal parameters, offering high precision for tasks like healthcare diagnostics but is resource-intensive.
- Prompt Engineering uses crafted prompts to guide models without altering them, offering cost-effective flexibility for creative tasks but lacks the precision of Fine-Tuning.
Each method suits different goals, resources, and task complexity.
2. How do I decide which technique is best suited for my project requirements?
To choose the best technique for your project, consider these factors:
Nature of the Task: For real-time, dynamic needs like customer support, use RAG. For precision tasks like medical diagnostics, choose Fine-Tuning. For creative or flexible tasks, Prompt Engineering is ideal.
- Resources: Fine-Tuning requires significant computational power and expertise. RAG needs moderate resources for retrieval systems, while Prompt Engineering is the most cost-effective with minimal computational needs.
- Customization: Fine-Tuning offers maximum customization by adapting to specific datasets. RAG allows moderate customization via external knowledge bases, while Prompt Engineering prioritizes adaptability over depth.
- Time: Prompt Engineering is the fastest to implement. RAG and Fine-Tuning take longer due to setup and training.
By weighing these factors against your project’s goals and constraints, you can identify the most suitable technique.
3. What are the resource implications of using RAG compared to Fine-Tuning and Prompt Engineering?
The resource demands of RAG, Fine-Tuning, and Prompt Engineering vary based on their requirements:
- RAG needs moderate resources, relying on external retrieval systems and organized knowledge bases. While less intensive than Fine-Tuning, it requires robust infrastructure for real-time data integration, raising complexity and cost.
- Fine-Tuning is the most resource-intensive, requiring significant computational power, storage, and expertise. Retraining on domain-specific datasets is time-consuming and costly, especially for large-scale applications.
- Prompt Engineering is the least demanding, leveraging pre-trained models without additional training. It is highly cost-effective, though crafting prompts for complex tasks can be time-intensive.
RAG balances resource needs and quality, Fine-Tuning delivers high precision at a high cost, and Prompt Engineering offers a lightweight, budget-friendly option.
4. Can these techniques be combined for enhanced AI model performance?
These techniques can be combined to enhance AI performance by leveraging their strengths:
- RAG + Fine-Tuning: Combines domain-specific precision from Fine-Tuning with RAG’s ability to access real-time information, ensuring accurate and relevant outputs for dynamic tasks.
- RAG + Prompt Engineering: Uses crafted prompts to guide RAG’s retrieval system, improving relevance and agility, ideal for tasks requiring real-time insights.
- Fine-Tuning + Prompt Engineering: Fine-Tuning establishes domain expertise, while Prompt Engineering refines outputs for specific scenarios, balancing precision and adaptability.
- Hybrid Approach: Combining all three techniques maximizes performance—Fine-Tuning for expertise, RAG for real-time relevance, and Prompt Engineering for task-specific optimization—ideal for complex workflows needing accuracy and flexibility.
Strategically blending these methods enhances AI models for diverse applications, addressing both static and dynamic needs effectively.
5. What are the common challenges and limitations associated with each approach?
Each approach has unique challenges and limitations:
- RAG: Retrieval latency can slow response times, especially in real-time applications. It heavily relies on the quality of external knowledge bases, with poor data risking misinformation. Integration with language models adds technical complexity, requiring robust infrastructure and expertise.
- Fine-Tuning: Resource-intensive, it demands significant computational power, time, and expertise. Risks include overfitting, reducing generalization, and catastrophic forgetting, where previous knowledge is lost when fine-tuning for new tasks. Managing data diversity and minimizing biases are critical but challenging.
- Prompt Engineering: A trial-and-error process, it depends on the quality of crafted prompts, which can be time-consuming for complex tasks. It offers limited control over the model’s internal behavior, leading to less precision compared to Fine-Tuning. Prompt drift, where responses deviate from intended outputs over time, affects consistency.
Understanding these challenges helps in selecting and optimizing the right approach.
Conclusion
Choosing between RAG, Fine-Tuning, and Prompt Engineering isn’t about picking a winner—it’s about aligning tools with goals. Think of these techniques as specialized instruments in a toolkit: each excels in specific scenarios but struggles when misapplied.
For instance, RAG shines in dynamic environments like financial analytics, where real-time data retrieval ensures relevance. Yet, its reliance on external databases can introduce latency, a critical drawback in high-speed trading. Fine-Tuning, on the other hand, delivers unmatched precision in niche fields like medical diagnostics, where a 30% accuracy boost can save lives. However, its resource demands make it impractical for startups or budget-conscious projects. Meanwhile, Prompt Engineering democratizes AI, enabling rapid prototyping for creative industries, but its trial-and-error nature can frustrate users seeking consistency.
The real insight? These methods aren’t rivals—they’re collaborators. Combining them, like layering RAG’s real-time insights with Fine-Tuning’s precision, unlocks AI’s full potential.