
Retrieval Augmented Generation (RAG) vs Semantic Search: Understanding the Differences
Learn the differences between RAG and Semantic Search. Understand how RAG enhances AI by retrieving data for context-aware generation, while Semantic Search improves search accuracy by understanding intent. Discover their use cases, strengths, and best applications.


Imagine two powerful AI-driven methods transforming how we find and use information: Retrieval-Augmented Generation (RAG) and Semantic Search.
On the surface, they might look similar—both involve retrieving relevant data and using natural language processing—but they differ substantially in how they interpret queries and generate results.
Picking the right one for your project can save resources, keep users engaged, and uncover new opportunities. Below, we’ll explore how each approach works, where they excel, and how you can combine them to create next-generation solutions.
Background on Information Retrieval and Natural Language Processing
Information retrieval (IR) focuses on finding the right snippet from a massive pool of data—like searching for that one relevant page in a stack of documents. Early IR systems heavily relied on keyword matching; if you searched for “best laptops,” they’d look for pages stuffed with those exact words. This worked fine until you used slightly different terms or typed a question that didn’t match those exact keywords.
That’s where Natural Language Processing (NLP) comes in. By interpreting language more like a human, NLP-based systems can recognize the intent behind words and phrases. For instance, if you type, “Which laptop works well for graphic design on a budget?” the system can understand synonyms like “best” or “good value,” factor in context like “graphic design,” and parse what “budget” means. This capability largely comes from methods such as word embeddings, where words and concepts are mapped to mathematical vectors that capture semantic relationships (like synonyms or related contexts).
This fusion of IR and NLP—particularly in methods like semantic search—has pushed boundaries in personalization, voice assistants, and analytics tools. Now, as data becomes more complex and diverse, the tension lies in striking the balance between high accuracy and scalability. That’s what sets the stage for Retrieval-Augmented Generation (RAG) and Semantic Search to shine.
The Evolution of Search Technologies
Early search engines resembled strict librarians: to find something, you had to provide the exact “call number”—the right keyword or phrase—or risk missing your target entirely. Semantic search changed that game by interpreting why you’re searching, not just the words you use. It does this through embeddings and vector models that capture deeper connections between concepts.
Recently, a hybrid approach, Retrieval-Augmented Generation (RAG), has emerged, blending this advanced retrieval with generative capabilities. If you type, “What are the most effective marketing strategies in 2025?” a RAG-powered system retrieves the latest articles, statistics, and expert opinions, then creates a synthesized answer. It’s not just about surfacing documents—it’s about weaving them together into a coherent response.
The success of these newer systems depends heavily on high-quality data. If your foundational data is scattered, inconsistent, or unstructured, even the best algorithms can produce misleading or irrelevant results. Moving forward, refining data pipelines and integrating user feedback loops will be paramount to building intelligent, adaptive search systems.
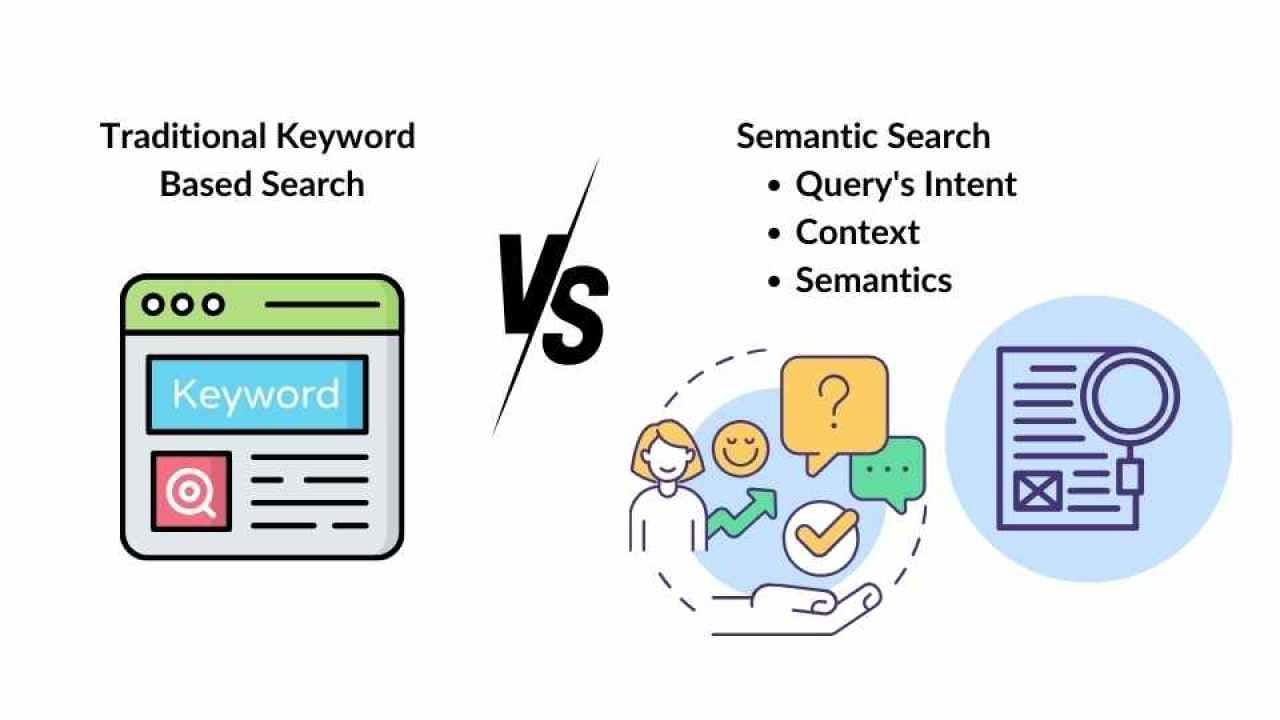
Understanding Semantic Search
Semantic search is all about deciphering meaning instead of merely matching keywords. If you search for “best laptops for coding,” a semantic search engine interprets that you need a device with high RAM, a solid processor, and perhaps long battery life—factors implied by “coding.”
This understanding largely hinges on vector embeddings, which place words and phrases into a multi-dimensional space. Words with similar meanings cluster together, allowing the search engine to detect relationships that go beyond literal keyword matches. For example, “cheap flights” might also return results mentioning “budget airlines,” “low-cost travel,” or “discount airfare.”
While semantic search is highly effective, it can struggle with very ambiguous queries if there’s no additional context (like user location or prior search history). For businesses, that means structure and context are crucial. You might employ knowledge graphs or domain-specific embeddings to ensure the system knows, for example, that “Apple” can be either a technology company or a fruit—two vastly different concepts.
How Semantic Search Works
The strength of semantic search lies in contextual comprehension. It uses NLP to identify the main intent of a query, then searches for documents that align with that intent. If you ask, “How do I fix a leaking faucet?” semantic search pinpoints “leaking faucet” as the core problem, rather than just matching pages that mention “faucet” and “fix” separately.
This process is powered by vector embeddings. Both queries and documents are represented as vectors, and the system calculates how “close” they are in semantic space. If you typed “budget-friendly travel to Europe,” the system might connect the dots to “cheap flights” or “hostel accommodations.” It’s not merely guessing; it’s drawing on statistical patterns learned from large text corpora.
For specialized fields—like law or medicine—semantic search often requires domain-specific tuning. A general embedding model might get confused by legal jargon, returning irrelevant results for specific case law queries. Fine-tuned embeddings help the system grasp technical language, ensuring consistent accuracy.
Real-World Applications of Semantic Search
One of the most visible applications is e-commerce. When a shopper types “comfortable running shoes for flat feet,” semantic search identifies key attributes like “arch support,” “stability,” and “comfort.” By pairing this knowledge with user data—previous purchases, brand preferences—it can surface the perfect pair of shoes. This tailored approach directly impacts customer satisfaction and, in turn, sales conversions.
Semantic search also powers content discovery on streaming platforms and news aggregators. If you enjoy certain shows or topics, the system can recommend similar content based on shared themes rather than simple tags. Personalization is often taken further by analyzing real-time user interactions, which guide the engine toward more accurate suggestions over time.
Understanding Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation is a technique where a generative model (like GPT) taps into an external retrieval mechanism before composing its answer. Picture a chatbot that’s asked a technical support question. Instead of relying only on what it was trained on months (or years) ago, the bot retrieves relevant documents—like FAQs, product manuals, or recent forum posts—then generates a synthesized, up-to-date response.
This approach is invaluable for contexts where freshness and accuracy matter. For instance, in healthcare, a RAG-powered system can retrieve the latest medical guidelines or studies to provide advice that reflects cutting-edge research. The generative component is “grounded” in the retrieved data, reducing the risk of AI hallucinations—those odd, made-up answers that purely generative models sometimes produce when they don’t have current information.
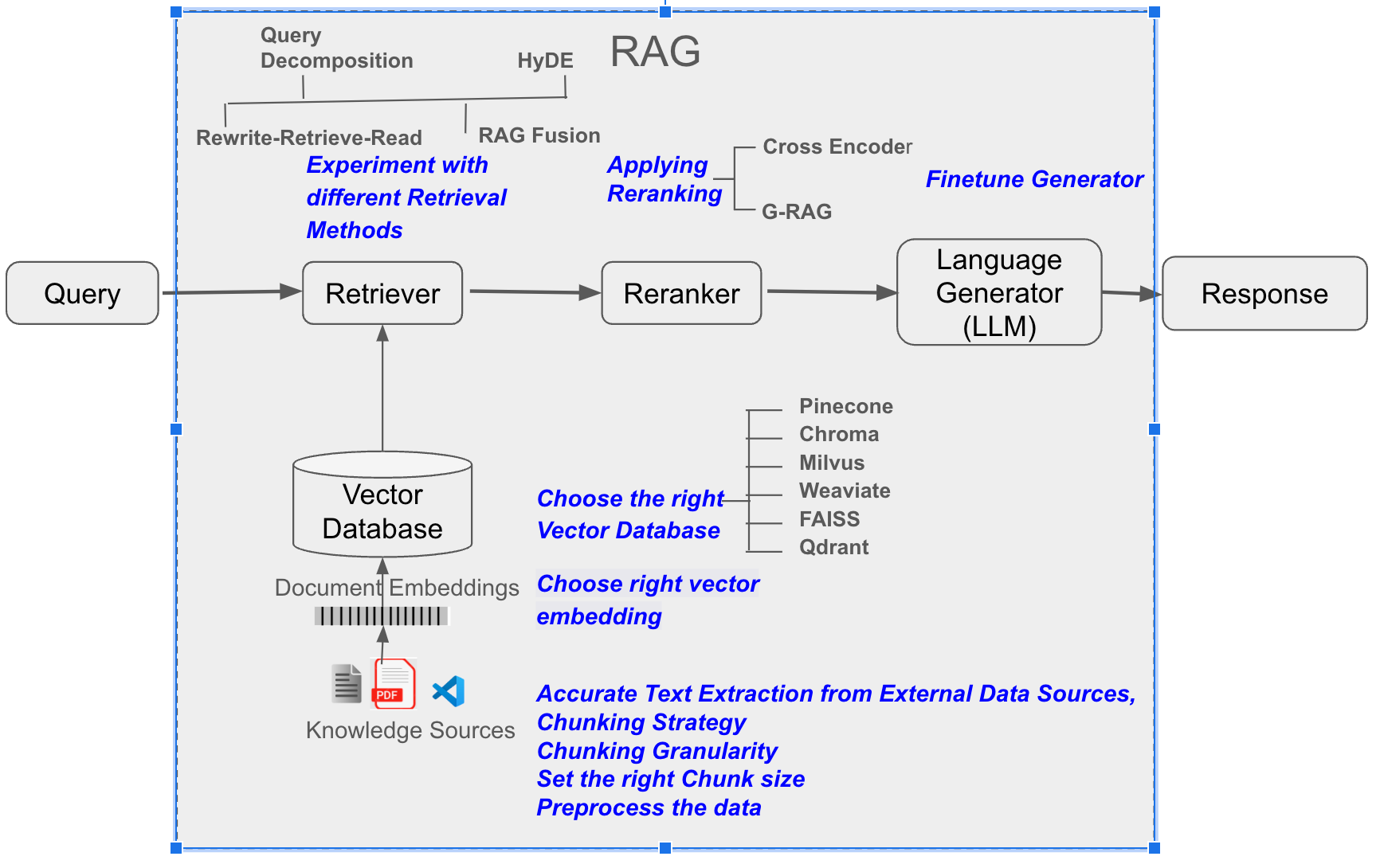
Mechanisms of RAG Models
A RAG model typically involves two main parts:
- Retrieval Model: This component indexes and searches through an external dataset. It often uses vector embeddings to match a user’s query with the most semantically relevant text snippets or documents.
- Generative Model: After retrieving relevant data, the system feeds it into a text-generation model. The generation process is guided by prompts designed to incorporate the retrieved information accurately.
For example, consider a legal research chatbot. When a user asks about precedent cases for a specific statute, the retrieval model fetches passages from relevant legal databases. The generative model then reads those passages, synthesizes them, and produces a succinct summary or recommendation. The key is the dynamic interplay between retrieval and generation—one finds the data, the other creates a coherent response.
Precision in retrieval is crucial. If the retrieval model brings back irrelevant documents, the generative model might produce extraneous or incorrect content. That’s why fine-tuning the retrieval model on domain-specific corpora can dramatically improve performance, particularly in fields like finance, healthcare, or law, where jargon and specialized knowledge are the norm.
Real-World Applications of RAG
A prime example is customer support automation. Instead of generic, pre-scripted responses, a RAG-based chatbot can query internal knowledge bases—like troubleshooting guides, user forums, or even live CRM data—to provide tailored solutions. If you ask, “Why hasn’t my order shipped yet?” the system can pull your order details and shipping logs before generating a precise update.
RAG also excels in knowledge-intensive fields such as academia or research. A science-focused RAG chatbot could retrieve the latest peer-reviewed articles, identify relevant findings, and craft a summary or recommendation. This real-time grounding in external data helps maintain accuracy and relevance, especially in fast-moving disciplines.
Feedback loops are another critical aspect. Each user interaction can refine how the system retrieves and synthesizes information. If customers frequently correct a certain answer, the retrieval layer can adjust its indexing or weighting so that future queries yield improved results.
Comparative Analysis of RAG and Semantic Search
Think of Semantic Search as an expert at pinpointing the exact information you want, like a librarian who can instantly locate the right shelf, even if your request is a bit vague. RAG, in contrast, is more like a personal researcher who gathers materials and then composes a custom write-up or explanation.
- Semantic Search is designed to quickly retrieve existing items (documents, products, etc.) by understanding your intent. It’s especially powerful in well-structured environments—like e-commerce or content libraries—where user queries can be mapped to a pre-indexed dataset.
- RAG adds a generative layer on top of retrieval. Instead of simply listing documents, it crafts an answer that draws on the most relevant parts of those documents, blending information into a single, cohesive response.
These technologies aren’t mutually exclusive. In many sophisticated applications, combining them leads to a system that both pinpoints relevant data and weaves it into user-friendly responses.
Differences in Methodologies
- Query Interpretation: Semantic Search maps the query to semantically similar documents, relying on embeddings and context. RAG also interprets the query semantically but takes an extra step—feeding the retrieved data into a generative model that produces new text.
- Data Utilization: Semantic Search returns what already exists. RAG uses existing data as a “scaffold” to generate new but grounded content.
- Scalability and Speed: Precomputed embeddings in Semantic Search allow thousands of quick lookups. RAG has an additional generative step that can introduce latency, but it also provides richer, context-aware responses.
Use Case Comparisons
- E-commerce: Semantic Search is exceptional for product discovery and recommendations. A user searching for “Bluetooth headphones” might be shown wireless earbuds, noise-canceling headphones, or related accessories based on understanding synonyms and user behavior.
- Customer Support: RAG excels here because it retrieves specific knowledge (like your order status or product manual) and generates a tailored reply. It’s less about listing results and more about offering a direct, personalized explanation.
Some businesses choose hybrid architectures. An e-commerce platform might use Semantic Search to guide product discovery and RAG to provide deeper explanations or handle post-purchase queries. This approach merges the precision of Semantic Search with the dynamic, context-rich nature of RAG.
Below is a simple comparison table listing the strengths and limitations of both RAG and Semantic Search:
Implementation Strategies
Whether you implement Semantic Search, RAG, or a mix of both depends on your data, your user needs, and how critical freshness or personalization is to your application.
Implementing Semantic Search Solutions
- Domain-Specific Tuning: While large models like BERT or GPT are good starting points, you’ll likely need to fine-tune them on your specific domain’s data to handle jargon or unique terminologies.
- Vector Embeddings: Tools like FAISS, Pinecone, or Weaviate can store and query embeddings at scale. This is how your system measures semantic similarity between user queries and documents.
- Knowledge Graphs: If your domain has complex relationships—like medical terms or legal statutes—knowledge graphs can help the system navigate these connections. Embeddings handle the semantic element, while knowledge graphs provide a structured map.
- User Feedback: Analyzing search logs, clicks, or user corrections helps refine your search engine’s accuracy. Over time, these insights lead to better embeddings and improved relevance.
Implementing RAG Models
- Prioritize Retrieval Precision: The first half of RAG is all about fetching the right data. If your retrieval system isn’t accurate, your generated output won’t be either. Vector databases are crucial, and domain-specific corpora will help the model return contextually meaningful snippets.
- Focus on Prompt Engineering: A well-crafted prompt ensures the generative model uses the retrieved data effectively. For instance, a support chatbot might be guided to reference FAQ data first, then escalate to deeper knowledge bases if needed.
- Domain-Specific Fine-Tuning: Just like with Semantic Search, you’ll want to train your retrieval and generative components on data relevant to your industry. This step is especially important in sectors with strict regulations, like finance or healthcare.
- Feedback Loops: Encourage user feedback—like rating or correcting an answer—to train both retrieval and generation layers. Over time, these systems “learn” from each query, boosting their overall precision.
Integration Challenges and Best Practices
- Data Harmonization: When pulling from structured databases, unstructured text, and various APIs, consistency can be a nightmare. Consider building a modular pipeline that preprocesses and standardizes each data source.
- Embedding Maintenance: Content changes, and embeddings can become outdated. Implement a schedule to re-index or update embeddings, especially in domains where information evolves quickly.
- Latency vs. Accuracy: Real-time responses might demand pre-batching or caching strategies. In a high-traffic scenario, you may have to trade off some real-time accuracy for speed, or vice versa.
- Scalable Infrastructure: Cloud services like AWS or GCP let you dynamically adjust resources to handle spikes in queries. Investing in auto-scaling prevents slowdowns when your system grows.
Advanced Applications and Emerging Trends
Multimodal RAG Systems
Multimodal RAG systems integrate text with images or videos, opening new possibilities in fields like medical imaging. A system might retrieve patient text records alongside X-ray images, then generate a diagnostic report that draws on both. This kind of approach isn’t just academically interesting—it has the potential to vastly improve diagnostic accuracy.
Domain-Specific RAG Fine-Tuning
Companies like Amazon personalize shopping experiences by fine-tuning RAG models on user behavior data and domain-specific product information. The result is a chatbot or recommendation engine that feels intuitive and hyper-relevant, because it pulls exactly the details you need and crafts an explanation or suggestion on the fly.
Hybrid Architectures
RAG and Semantic Search often work best together. Think of it this way:
- Semantic Search ensures you retrieve the most relevant documents quickly.
- RAG uses those documents to generate answers that address the user’s specific question.
This synergy is particularly valuable in legal tech, where a system might retrieve case law and then generate a succinct argument or summary, all in real-time.
Cross-Industry Impacts and Future Directions
Personalized Education
Adaptive learning platforms are increasingly using RAG-like approaches to generate customized lesson plans. By pulling from textbooks, academic journals, and educational videos, they can assemble unique course material for each student. Over time, the system learns a student’s weaknesses and strengths, refining both retrieval and generation to offer the most effective study tools.
Supply Chain Management
In logistics, a RAG chatbot can combine real-time sensor data with warehouse inventory reports. Instead of simply listing “Item 123 is out of stock,” it can generate a more nuanced response: “Item 123 is currently in transit and will arrive at the warehouse tomorrow. Here’s how you can update orders.” That’s dynamic, context-rich advice that goes well beyond simple retrieval.
The Challenge of Cross-Domain Embeddings
If your business spans multiple areas—say, retail and finance—your systems need embeddings that handle both product catalogs and market reports. This level of cross-domain versatility is an active area of research, as it demands embeddings that can pivot smoothly between very different types of content.
FAQ
1. What is the main difference between RAG and Semantic Search?
- RAG: Retrieves relevant data and generates a new, context-rich answer.
- Semantic Search: Focuses on finding the most relevant existing documents based on query intent.
2. How does RAG improve accuracy?
RAG uses up-to-date data during retrieval, reducing outdated information. Generating answers grounded in current sources also helps minimize AI “hallucinations.”
3. In which scenarios is Semantic Search more effective compared to Retrieval Augmented Generation (RAG)?
Semantic Search is best when you want fast, precise retrieval of existing documents (e.g., product listings or knowledge-base articles) without needing newly generated text.
4. What are the main technical challenges for RAG and Semantic Search?
- RAG: Requires high-quality data and good prompt engineering to avoid misinformation and reduce computational overhead.
- Semantic Search: Needs well-structured or annotated data to ensure relevant results, and it can struggle with vague queries.
5. How do businesses choose between RAG, Semantic Search, or both?
- RAG suits cases needing dynamic, personalized, or synthesized responses.
- Semantic Search excels at quick, large-scale lookups for existing documents.
- A hybrid approach may be best if you need both comprehensive retrieval and context-rich answers.
Conclusion
Choosing between RAG, Semantic Search, or a hybrid approach isn’t just a technical decision—it’s a strategic one. Think of RAG as a chef crafting a custom dish, blending fresh ingredients (retrieved data) with creativity (generation). Semantic Search, on the other hand, is like a librarian, quickly finding the exact book you need. Both are powerful, but their effectiveness depends on the context.
For example, an e-commerce platform might thrive with Semantic Search, delivering precise product matches. Meanwhile, a legal chatbot benefits from RAG, pulling case law snippets to craft tailored advice. But here’s the twist: a hybrid model can combine these strengths, like pairing a librarian with a chef to create a curated, personalized experience.
The misconception? That one is inherently better. The truth? It’s about alignment—matching the tool to the task. By understanding these nuances, businesses can unlock smarter, more impactful AI solutions.