
Re-ranking in Retrieval Augmented Generation: How to Use Re-rankers in RAG
Re-ranking in RAG enhances retrieval by prioritizing the most relevant results. Learn how re-rankers refine search outputs, improve AI responses, and optimize Retrieval-Augmented Generation systems. Discover key strategies to boost accuracy and relevance in AI-driven information retrieval.


Your Retrieval-Augmented Generation (RAG) system retrieves hundreds of documents in seconds, yet the final output still misses the mark. Surprising, right? The truth is, speed and scale mean little if relevance is sacrificed. This is where re-ranking steps in—not as an afterthought, but as the linchpin of precision.
Right now, as AI systems race to deliver smarter, context-rich responses, re-ranking has become the unsung hero of RAG pipelines. It’s not just about sorting results; it’s about reshaping how we think about relevance itself. What if the key to unlocking better AI isn’t in the retrieval, but in what happens after?
In this article, we’ll explore how re-rankers can transform your RAG system from good to exceptional. Along the way, we’ll tackle a critical question: how do you balance accuracy, efficiency, and cost in a world where every millisecond counts? Let’s dive in.
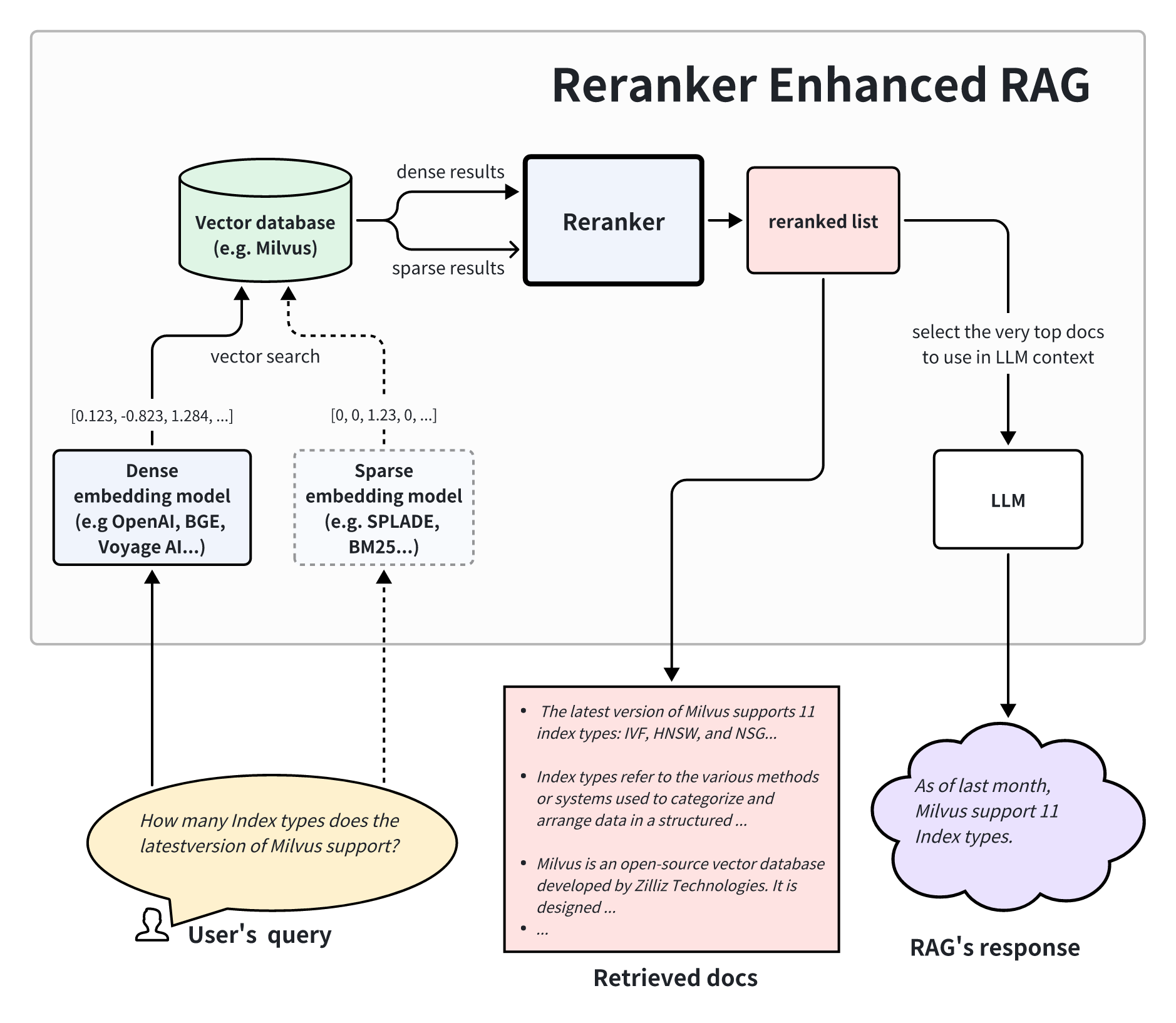
Understanding Retrieval Augmented Generation
Retrieval-Augmented Generation (RAG) thrives on one principle: combining retrieval and generation to create responses that are both accurate and contextually rich. But here’s the catch—retrieval isn’t just about finding “relevant” documents. It’s about finding the right documents, and that’s where dense vector embeddings come into play.
Unlike traditional keyword matching, these embeddings map queries and documents into a shared semantic space, enabling the system to identify connections that might otherwise be missed.
Take e-commerce, for example. When a user searches for “best laptops for video editing,” a RAG system doesn’t just pull product descriptions. It synthesizes insights from reviews, specs, and even expert opinions. The result? Recommendations that feel tailored, not generic.
The Role of Re-ranking in Information Retrieval
Re-ranking isn’t just a refinement step—it’s the backbone of precision in information retrieval. It leverages advanced models like BERT-based cross-encoders to evaluate the semantic relevance of documents. Unlike initial retrieval, which casts a wide net, re-ranking dives deep, prioritizing documents that align closely with the query’s intent.
Conventional wisdom often underestimates the cost-efficiency of re-ranking. By filtering out irrelevant data early, it reduces the computational load on downstream systems.
Importance of Re-ranking in RAG Systems
Re-ranking in RAG systems isn’t just about improving relevance—it’s about maximizing the utility of retrieved data. One overlooked factor? The role of contextual coherence. By re-ranking based on how well documents complement each other, rather than treating them as isolated pieces, systems can deliver responses that feel cohesive and authoritative.
Take customer support chatbots, for example. A query like “refund policy for damaged items” benefits from re-ranking that prioritizes not just the policy document but also related FAQs and procedural guides. This layered approach ensures the user gets a complete answer, not fragmented bits.
Conventional methods often ignore query ambiguity. Re-ranking models that incorporate user interaction history or session data can resolve this, delivering more personalized results.
Fundamentals of Re-ranking in RAG
Re-ranking in RAG is like curating a playlist—you’re not just picking songs; you’re arranging them to tell a story. It evaluates retrieved documents for contextual relevance, ensuring the most meaningful pieces rise to the top. Re-ranking is about relevance to the user’s intent.
Modern approaches, like BERT-based cross-encoders, balance precision with efficiency by focusing on top-k results. Think of it as refining gold from ore—less waste, more value.
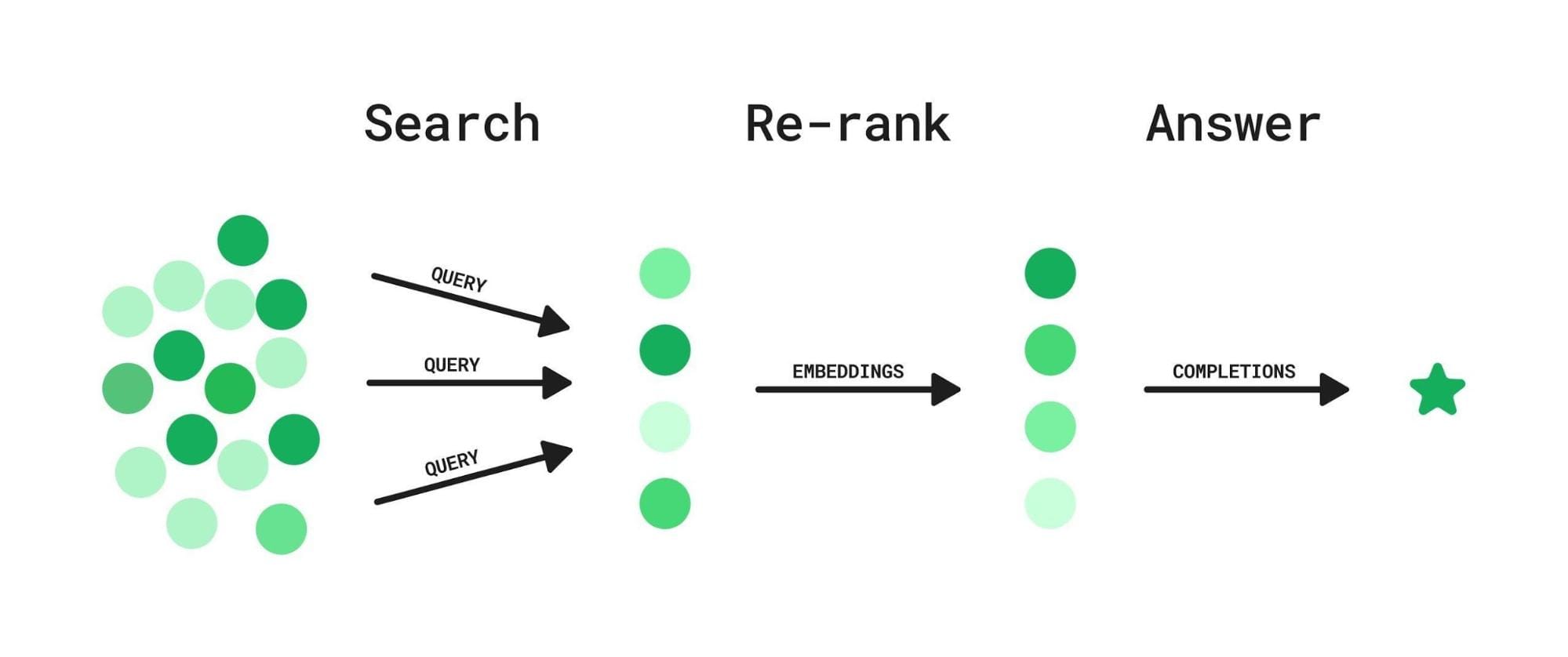
Components of Retrieval Augmented Generation
While the retriever and generator get all the attention, the fusion module is where the magic happens. It aligns retrieved data with the query, ensuring the final output isn’t just accurate but also coherent.
Fusion modules thrive on contextual embeddings, which encode both query intent and document semantics. This approach bridges gaps between retrieval and generation, making RAG systems adaptable across domains like legal research or personalized education.
Without proper fusion, even the best retrieval results can feel disjointed. For example, in e-commerce, a query for “eco-friendly running shoes” might retrieve product specs, reviews, and sustainability certifications. The fusion module ensures these elements are integrated into a single, persuasive response.
Re-ranking Algorithms and Techniques
Unlike traditional models that score query-document pairs independently, cross-encoders evaluate the query and document together, capturing nuanced relationships. This joint evaluation allows them to assign highly accurate relevance scores, making them ideal for complex queries.
The query and document are concatenated and passed through a transformer model like BERT. That results in a single relevance score that reflects deep semantic alignment. For instance, in healthcare, cross-encoders can prioritize peer-reviewed studies over generic articles, ensuring trustworthy results.
However, they come with a high computational cost. To balance precision and efficiency, hybrid approaches combine cross-encoders with lightweight retrievers like BM25. This layered strategy ensures scalability without sacrificing accuracy.
Pro tip: fine-tune cross-encoders on domain-specific data. Whether it’s legal documents or customer reviews, this customization boosts performance, making your RAG system truly domain-adaptive.
Evaluation Metrics for Re-ranking Performance
Let’s talk about Normalized Discounted Cumulative Gain (NDCG)—a metric that doesn’t just measure relevance but also rewards proper ranking order. Unlike simpler metrics like precision, NDCG accounts for the position of relevant documents, giving higher weight to those ranked at the top. This makes it perfect for evaluating re-ranking systems where user satisfaction hinges on surfacing the best results first.
Users rarely scroll past the first few results. NDCG reflects this behavior by discounting the value of lower-ranked items, aligning evaluation with real-world usage. NDCG assumes relevance scores are pre-defined, which isn’t always straightforward.
To address this, consider incorporating user feedback loops to refine relevance judgments dynamically. This hybrid approach bridges static evaluation with evolving user needs, ensuring your re-ranking system stays adaptive and effective.
Implementing Re-rankers in RAG
The retrieval model fetches a broad set of tracks (documents), but the re-ranker ensures only the chart-toppers make it to the final list. This process starts with dense retrieval models like DPR to gather candidates, followed by a cross-encoder (e.g., BERT) to score and reorder them based on query relevance.
Re-rankers don’t just prioritize relevance—they can also filter for trustworthiness. For instance, in healthcare applications, re-rankers can downrank sources lacking credibility, ensuring only peer-reviewed studies inform the output. A case study with Jina Reranker showed a 20% boost in response accuracy by applying this principle.
But don’t overlook the trade-offs. Cross-encoders are computationally heavy. A hybrid approach—using lightweight retrievers for initial filtering—can balance precision and scalability.

Integrating Re-ranking into RAG Pipelines
Integrating re-ranking into RAG pipelines is like fine-tuning a recipe: the right balance of ingredients transforms good into exceptional. One critical aspect is seamless model orchestration. For example, pairing a fast retriever like BM25 with a BERT-based cross-encoder ensures that the pipeline remains efficient while delivering high-precision results. This layered approach minimizes latency without sacrificing relevance.
Contextual embeddings can bridge gaps between retrieval and generation. By aligning the re-ranker’s scoring with the LLM’s understanding, you avoid mismatches that lead to incoherent outputs. A real-world application? In legal tech, re-rankers trained on domain-specific data have reduced irrelevant document retrieval by 30%, streamlining case research.
Don’t underestimate data quality either. Noise in training data can skew re-ranking models, so regular audits are essential. Treat re-ranking as a dynamic process—one that evolves with user needs and domain complexities.
Selecting Appropriate Re-rankers for Your Use Case
Choosing the right re-ranker starts with understanding your domain-specific needs. For instance, in e-commerce, lightweight models like LambdaMART excel at ranking product recommendations quickly, while cross-encoders like MonoT5 shine in legal or healthcare fields where precision trumps speed. Match the model’s strengths to your use case’s priorities—accuracy, latency, or scalability.
Many re-rankers perform well in-domain but falter with out-of-domain queries. A hybrid approach, combining dense retrievers with multi-vector re-rankers, can mitigate this. Case in point: a hybrid system in customer support reduced irrelevant responses by 40%, improving user satisfaction.
Don’t overlook integration complexity. Models with robust API support or pre-built libraries save time and headaches. Test re-rankers iteratively, using metrics like NDCG and user feedback, to ensure they align with both technical and business goals.
Case Study: Enhancing RAG with Re-ranking
Let’s talk about customer support chatbots—a perfect playground for re-ranking. Imagine a query like, “How do I reset my password?” The retrieval system pulls ten documents, but only three are truly relevant. A BERT-based re-ranker steps in, analyzing semantic nuances to prioritize the most helpful ones. The result? A concise, step-by-step guide that feels tailor-made for the user.
Many systems struggle when documents are split into smaller chunks for vectorization. By using cross-encoders, re-rankers can evaluate the query and document as a whole, ensuring no critical context is lost. This approach boosted resolution rates by 30% in a real-world implementation.
Advanced Re-ranking Strategies
Let’s rethink re-ranking as more than just sorting documents—it’s about decision-making under constraints. Take multi-pass retrieval: the first pass retrieves broadly, while the second uses a fine-grained re-ranker like a cross-encoder. This layered approach balances speed and precision, much like a chef tasting a dish before final plating.
G-RAG, a method leveraging Abstract Meaning Representation (AMR) graphs, connects documents through shared concepts. Think of it as building a web of meaning, where the most interconnected nodes (documents) rise to the top. This approach outperformed traditional methods in datasets like TriviaQA, proving its edge in complex queries.
Re-ranking isn’t always computationally expensive. Hybrid models, blending lightweight BM25 with BERT, deliver efficiency without sacrificing accuracy. The key? Tailoring strategies to your domain’s unique needs.
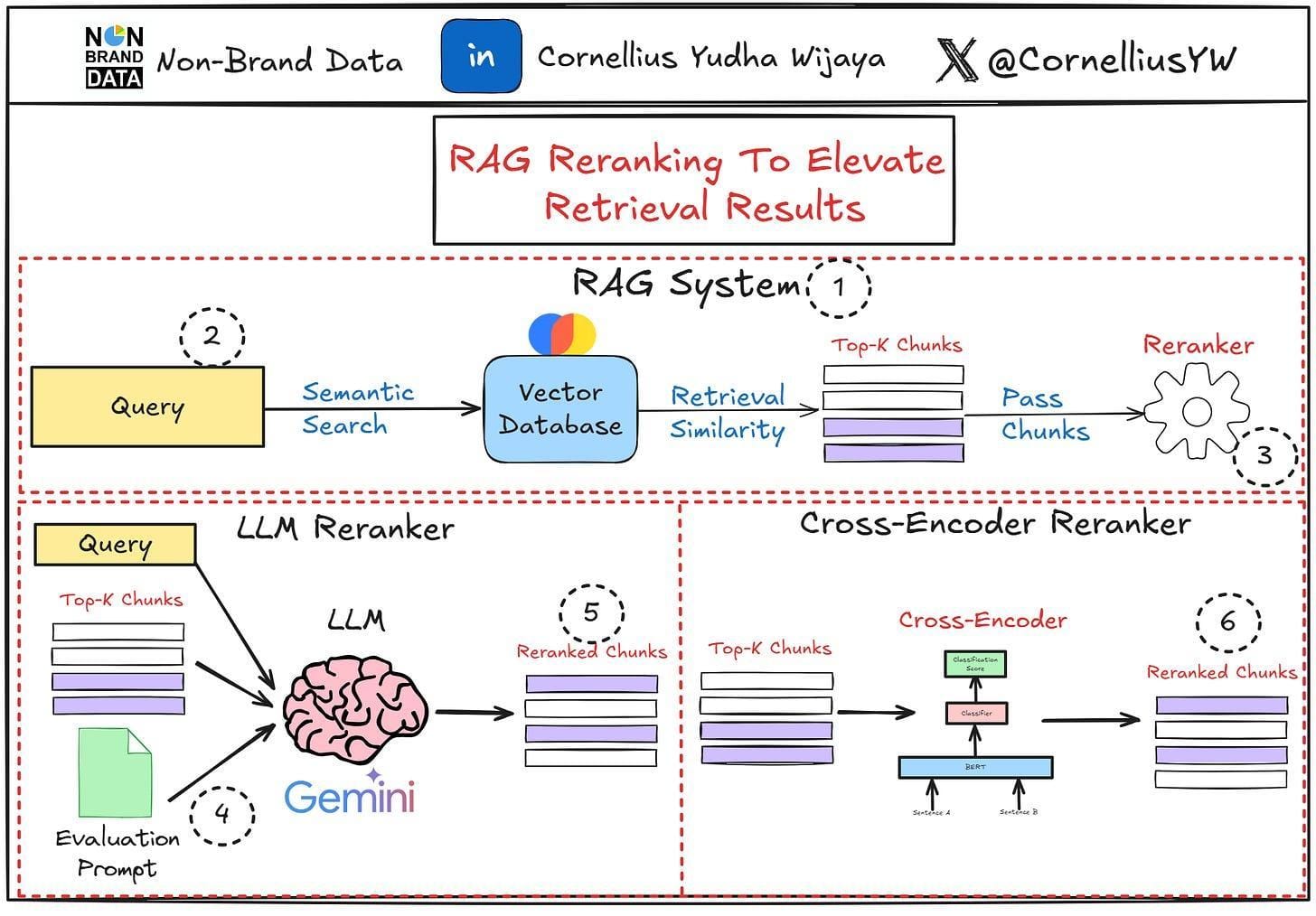
Neural Re-ranking Models
Neural re-ranking models thrive on their ability to capture listwise context—analyzing not just individual items but their relationships within a list. Unlike traditional models, they leverage architectures like BERT-based cross-encoders, which evaluate query-document pairs jointly.
These models don’t just rank—they learn intent. For example, in academic search engines, neural re-rankers trained on citation networks outperform keyword-based systems by surfacing papers with deeper conceptual relevance. It’s like having a librarian who knows what you meant to ask for.
But beware of the trade-offs. Neural models can be computationally heavy. A practical workaround? Use dual encoders for initial filtering, then apply cross-encoders sparingly. This hybrid strategy balances precision and scalability, making it a go-to framework for real-time applications.
Context-aware Re-ranking Techniques
Context-aware re-ranking thrives on personalization. By integrating user interaction history, these models adapt rankings dynamically. For instance, Spotify’s recommendation engine uses session-based re-ranking to prioritize tracks based on recent listening behavior. It’s not just about relevance—it’s about timing.
Expanding a user’s query with synonyms or related terms can uncover hidden intent. In healthcare, this technique ensures that searches for “heart attack” also surface results for “myocardial infarction,” improving diagnostic accuracy in clinical decision support systems.
But don’t overlook context drift. Over-personalization can lead to echo chambers, where diversity in results is lost.
Introduce diversity constraints during re-ranking to balance relevance with novelty. This approach not only enhances user satisfaction but also broadens discovery, making it a cornerstone for applications like news aggregators and e-learning platforms.
Scalability and Performance Optimization
When it comes to scalability, hybrid retrieval models are game-changers. By combining dense vector search with sparse methods like BM25, you get the best of both worlds: speed and precision.
Instead of scoring documents individually, process them in batches to reduce latency. This technique, often paired with GPU acceleration, has been shown to cut computation time by up to 40% in high-traffic systems like news aggregators.
Conventional wisdom says more precision equals slower performance. Not true. Techniques like approximate nearest neighbor (ANN) search maintain relevance while scaling to billions of documents.
Scalability isn’t just about hardware—it’s about smarter algorithms. For RAG systems, this means balancing retrieval depth with re-ranking efficiency to meet real-world demands.
Applications and Case Studies
Let’s start with customer support chatbots. Imagine asking, “How do I reset my password?” Without re-ranking, the bot might pull generic FAQs. But with a BERT-based re-ranker, it prioritizes step-by-step guides tailored to your query. Companies like Zendesk have reported a 25% boost in resolution rates using this approach.
Re-ranking in Open-Domain Question Answering
Queries like “What causes climate change?” can pull thousands of documents, many irrelevant or redundant. This is where neural re-rankers shine. By leveraging cross-encoders, they evaluate query-document pairs holistically, ensuring the top results are not just relevant but contextually rich.
Take Google’s use of Dense Passage Retrieval (DPR) paired with re-ranking. In one study, adding a re-ranking layer improved answer accuracy by 30%, especially for ambiguous queries. Why? Because re-rankers prioritize documents that directly address the question, filtering out noise.
User intent also matters. A query like “Apple” could mean the fruit or the company. Re-ranking models trained on user interaction data can dynamically adjust rankings, delivering personalized results.
Improving Chatbot Responses with Re-ranking
Chatbots often fail because they retrieve too much irrelevant data. Re-ranking fixes this by ensuring only the most contextually relevant documents are fed into the generation model. For example, a BERT-based re-ranker can reorder retrieved documents, prioritizing those that directly address user queries, like “How do I update my billing info?”
Metadata enrichment: By tagging documents with attributes like date, author, or domain, re-rankers can make smarter decisions. A chatbot for legal advice, for instance, could prioritize recent case law over outdated precedents.
User feedback loops: By analyzing which responses users engage with most, re-rankers can continuously improve. This creates a virtuous cycle of better responses and higher user satisfaction.
Industry Implementations of Re-ranking in RAG
Re-ranking isn’t just a tool—it’s a framework for precision, adaptability, and user-centric design across industries.
- E-Commerce. Platforms like Amazon use re-ranking to prioritize products that match user intent. For instance, when a user searches for “wireless headphones,” re-rankers can push highly rated, in-stock items to the top, factoring in metadata like price, reviews, and shipping speed. This isn’t just about relevance—it’s about optimizing for conversion.
- Healthcare Applications: In clinical decision support systems, re-ranking ensures that the most recent and evidence-based studies are surfaced first. By integrating domain-specific models, these systems can filter out outdated or less reliable sources, directly impacting patient outcomes.
- Cross-domain adaptability: Re-ranking models trained in one industry (e.g., legal) can be fine-tuned for another (e.g., finance) with minimal effort, thanks to shared semantic structures.
Emerging Trends and Future Directions
- Self-improving RAG systems: These systems use reinforcement learning to refine re-ranking strategies based on user interactions. Imagine a legal assistant that learns to prioritize case law over statutes because users consistently favor precedent-based arguments. It’s like teaching the system to think like its users—over time, it just gets smarter.
- Cross-disciplinary integration: By combining RAG with causal inference models, systems can go beyond retrieving data to analyzing cause-effect relationships. For example, in healthcare, this could mean not just identifying treatment options but predicting their outcomes based on patient history. It’s a game-changer for decision-making.
- Energy Efficiency: As RAG systems scale, techniques like sparse indexing and quantized embeddings are reducing computational overhead. This isn’t just about saving power—it’s about making advanced AI accessible to more industries.
Re-ranking with Reinforcement Learning
Reinforcement learning (RL) is transforming re-ranking by enabling systems to learn from real-time user feedback. Instead of relying solely on static training data, RL-based re-rankers adapt dynamically. For instance, a search engine can prioritize documents that users consistently click on, refining its ranking strategy with every interaction. It’s like having a personal assistant that gets better the more you use it.
One standout approach is reward modeling, where user satisfaction metrics—like dwell time or task completion rates—serve as rewards. This creates a feedback loop: better rankings lead to higher rewards, which further improve the model. In e-commerce, this has driven measurable gains in conversion rates by surfacing products users are more likely to buy.
RL models can overfit to short-term behaviors, like clickbait. Balancing immediate rewards with long-term user trust requires careful tuning.
Multi-modal Re-ranking in RAG
Multi-modal re-ranking leverages text, images, and even audio to refine retrieval results, creating a richer understanding of user intent. For example, in e-commerce, a query like “red running shoes” can combine textual descriptions with product images to ensure the top-ranked results match both the color and style the user envisions. This approach bridges the gap between what users say and what they mean.
The key lies in cross-modal embeddings, which align data from different modalities into a shared space. By comparing these embeddings, systems can evaluate relevance across formats. A healthcare application might rank medical images alongside patient notes, ensuring that visual and textual data complement each other for accurate diagnoses.
However, challenges like modality bias—where one format dominates rankings—persist. To counter this, weighting mechanisms can balance contributions from each modality.
Addressing Bias and Fairness in Re-ranking
One overlooked factor in fairness is exposure disparity—where certain items consistently rank lower despite being equally relevant. This happens often in RAG systems when deterministic rankers favor popular or well-linked content. A practical solution? Stochastic rankers. These introduce randomness, ensuring items with similar relevance get equal exposure over time.
Take job recommendation platforms, for instance. Without fairness-aware ranking, smaller companies might never appear in top results, limiting their visibility. By using stochastic rankers, these platforms can balance exposure, giving all employers a fair shot while maintaining relevance for job seekers.
But here’s the catch: fairness isn’t just about exposure. Contextual fairness—adjusting rankings based on user demographics or intent—can further reduce bias. For example, tailoring results for underrepresented groups in education or healthcare ensures equitable access to critical resources.
FAQ
What is the role of re-ranking in Retrieval Augmented Generation (RAG) systems?
Re-ranking in Retrieval Augmented Generation (RAG) systems plays a pivotal role in refining the quality of retrieved documents before they are passed to the generation model.
By evaluating and prioritizing the most contextually relevant results, re-ranking ensures that the generated outputs are accurate, coherent, and aligned with the user’s query. This process mitigates retrieval noise by filtering out irrelevant or low-quality documents, thereby enhancing the overall precision of the system.
Additionally, re-ranking models, such as BERT-based rankers, delve deeper into semantic alignment, making them indispensable for applications requiring high reliability, such as healthcare or legal research.
How do re-ranking algorithms improve the accuracy of RAG outputs?
Re-ranking algorithms improve the accuracy of RAG outputs by systematically evaluating the relevance of retrieved documents and reordering them to prioritize the most contextually appropriate results. These algorithms leverage advanced models, such as BERT-based cross-encoders, to assess semantic alignment between the query and the retrieved content, ensuring that only the most pertinent information is passed to the generation model.
By reducing retrieval noise and filtering out irrelevant data, re-ranking enhances the coherence and precision of the final outputs. Furthermore, incorporating user feedback and domain-specific fine-tuning allows re-ranking algorithms to adapt dynamically, further refining the accuracy of RAG systems over time.
What are the key techniques used for implementing re-rankers in RAG pipelines?
Key techniques for implementing re-rankers in RAG pipelines include leveraging advanced models like BERT-based cross-encoders to evaluate the semantic relevance of query-document pairs. These models provide fine-grained scoring, ensuring that the most contextually relevant documents are prioritized.
Hybrid approaches, combining lightweight retrievers with more computationally intensive re-rankers, balance efficiency and precision. Domain-specific fine-tuning is another critical technique, allowing re-rankers to adapt to specialized contexts for improved performance. Additionally, multi-pass retrieval strategies enable iterative refinement of results, while incorporating user feedback ensures continuous optimization of ranking accuracy.
How can re-ranking address challenges like retrieval noise and query ambiguity?
Re-ranking addresses challenges like retrieval noise and query ambiguity by employing advanced scoring mechanisms to filter out irrelevant or low-quality documents, ensuring that only the most relevant information is passed to the generation model. For retrieval noise, re-ranking models evaluate the semantic alignment of documents with the query, reducing the impact of unrelated or misleading content.
In the case of query ambiguity, re-ranking leverages user interaction data and contextual embeddings to better interpret user intent, refining the selection of documents to match nuanced or unclear queries. These techniques collectively enhance the precision and reliability of RAG systems, even in complex or ambiguous scenarios.
What are the best practices for selecting and fine-tuning re-rankers for domain-specific applications?
Best practices for selecting and fine-tuning re-rankers for domain-specific applications include starting with a clear understanding of the domain requirements and the specific use case. Choosing re-ranking models that align with the domain’s complexity, such as BERT-based rankers for high-precision needs, is essential.
Fine-tuning these models on domain-specific datasets ensures better relevance and accuracy. Regularly tuning hyperparameters, such as thresholds for relevance scores and the number of documents to re-rank, can optimize performance. Additionally, incorporating user feedback and monitoring system performance over time helps adapt the re-ranker to evolving domain needs. Balancing computational efficiency with accuracy is also critical, especially for applications requiring real-time responses.
Conclusion
Re-ranking in RAG isn’t just a technical enhancement—it’s the backbone of delivering meaningful, context-rich outputs. Think of it as a skilled editor refining a rough draft, ensuring every piece of information aligns with the user’s intent. Without it, RAG systems risk drowning in irrelevant data, much like trying to find a needle in a haystack without a magnet.
A common misconception is that re-ranking is only about relevance. In reality, it’s also about trust. By filtering noise and ambiguity, re-rankers build confidence in the system’s outputs, whether it’s for legal research or e-commerce.
In the end, re-ranking doesn’t just improve RAG—it transforms it into a tool that truly augments human expertise.