
Efficient Integration of Recent News into RAG Workflows
Integrating recent news into RAG workflows ensures timely, relevant AI responses. This guide explores tools and techniques to fetch, preprocess, and embed up-to-date content, keeping your RAG system informed and contextually aware.


Efficient Integration of Recent News into RAG Workflows isn’t just a technical goal—it’s a growing necessity.
News breaks fast. And when it does, traditional RAG systems often miss the mark. They rely on static datasets, which are not built to process updates that shift by the second.
But here’s the challenge: real-time news is messy. Headlines are vague, facts evolve, and sources contradict each other.
For a RAG system, that means working with incomplete, noisy input and still producing something reliable.
That’s where efficient integration of recent news into RAG workflows comes in.
Done right, it allows systems to keep up with breaking stories, adapt to shifting narratives, and deliver responses that reflect what’s happening now—not what happened last week.
This article explores how modern RAG pipelines are being re-engineered for real-time performance without sacrificing context or coherence.
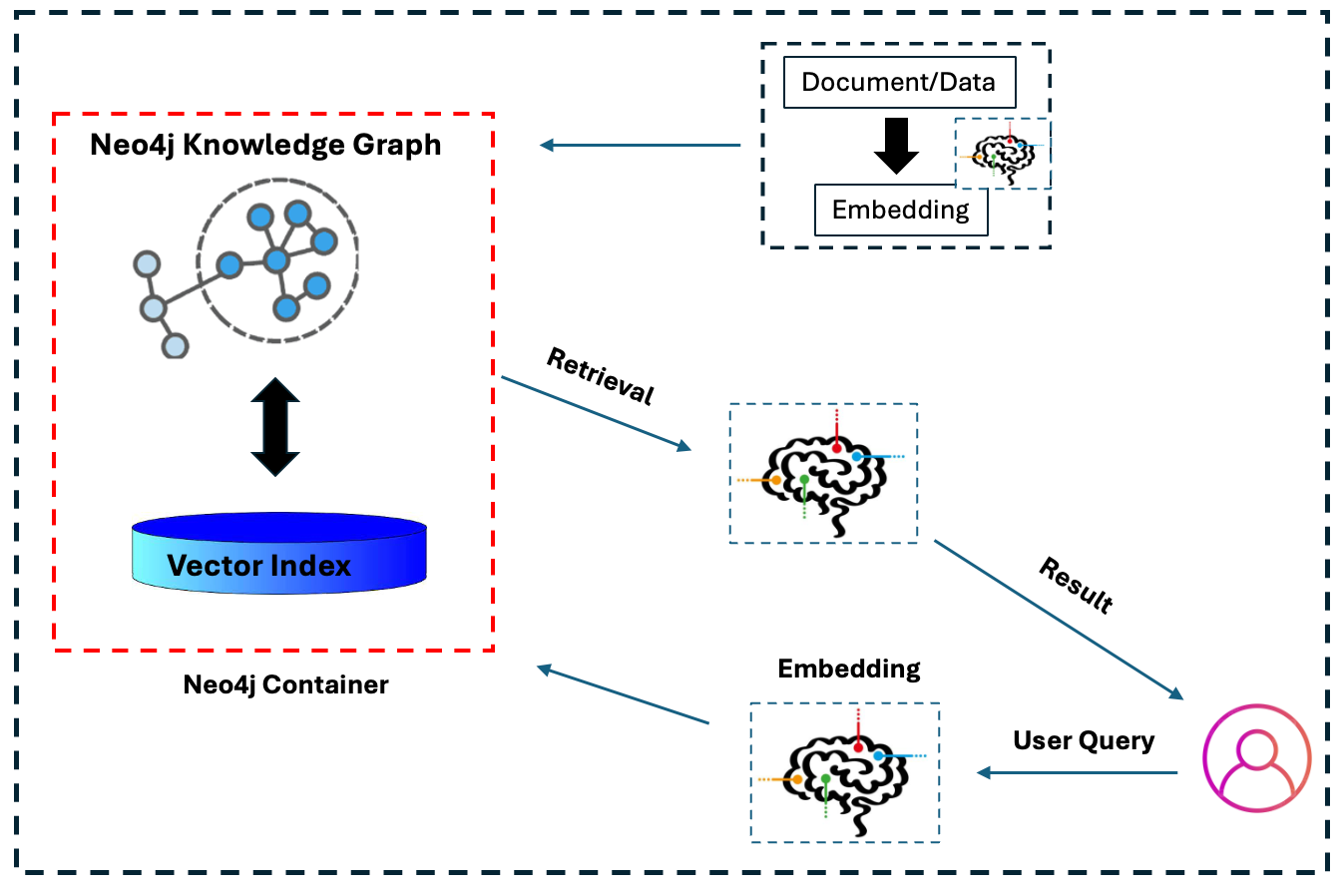
Components of RAG Architecture
Embeddings are a cornerstone of RAG architecture, yet their intricacies often go unnoticed.
These high-dimensional vector representations of text bridge raw data and semantic understanding. Their precision directly impacts the retriever’s ability to identify contextually relevant information, especially in dynamic environments like real-time news integration.
What sets advanced RAG systems apart is their use of hybrid embedding models.
These models combine dense embeddings, which capture semantic nuances, with sparse embeddings that excel in keyword-based retrieval.
This dual approach ensures robustness across diverse query types.
For instance, dense embeddings might interpret “market crash” as a financial event, while sparse embeddings ensure literal matches for specific terms like “NASDAQ.”
However, embedding quality alone isn’t sufficient. The vector database must support rapid indexing and retrieval without compromising accuracy.
Systems like Pinecone and Qdrant optimize this by leveraging approximate nearest neighbor (ANN) algorithms, balancing speed and precision. Yet, edge cases—such as ambiguous queries or incomplete data—highlight the need for continuous fine-tuning.
This synergy between embeddings and vector databases transforms RAG from a static system into a dynamic, context-aware solution, capable of adapting to the complexities of real-world applications.
Role of Embeddings in Semantic Representation
Embeddings act as the semantic backbone of RAG workflows, translating unstructured data into a shared vector space where meaning is preserved and relationships are clarified.
This transformation is not merely a mathematical operation but a nuanced process that captures both explicit and implicit connections within the data.
One critical technique is the use of domain-specific embedding adaptors, which fine-tune general-purpose models like BERT or GPT to align with specialized datasets.
For instance, in financial applications, embeddings trained on market reports and regulatory filings outperform generic models by capturing industry-specific terminology and context.
However, this approach introduces challenges, such as overfitting to niche vocabularies, which can reduce generalizability.
Comparatively, hybrid embedding models balance dense and sparse representations, ensuring both semantic depth and keyword precision.
While dense embeddings excel in capturing abstract relationships, sparse embeddings anchor the system in literal accuracy, particularly for ambiguous queries.
This duality is essential in real-time news.
Ultimately, the effectiveness of embeddings depends on their adaptability. Continuous feedback loops, informed by user interactions, refine these models, ensuring they remain relevant in dynamic environments.
Incorporating Real-Time News Data
Integrating real-time news into RAG workflows demands more than just speed—it requires precision in contextual alignment.
A single processing misstep can cascade into flawed insights, especially in high-stakes domains like finance or public policy.
To address this, advanced systems employ time-sensitive retrieval mechanisms, which prioritize the most recent data while maintaining historical continuity. This ensures that evolving narratives are not only captured but also contextualized within broader trends.
One breakthrough technique is dynamic re-ranking, where retrieved documents are scored and reordered based on their temporal relevance and semantic fit.
For instance, platforms like Bloomberg Terminal utilize such methods to deliver actionable updates to traders within seconds, minimizing decision-making delays.
This approach mirrors the way a newsroom editor prioritizes breaking stories over archival content, ensuring immediacy without sacrificing depth.
A common misconception is that real-time integration sacrifices accuracy for speed.
However, adaptive pipelines—which preprocess data with metadata enrichment and entity recognition—debunk this myth.
By tagging headlines with entities like names, locations, and timestamps, these systems create a structured framework that enhances both retrieval and summarization accuracy.
The result? A seamless blend of immediacy and reliability, empowering users to act on insights as they unfold.
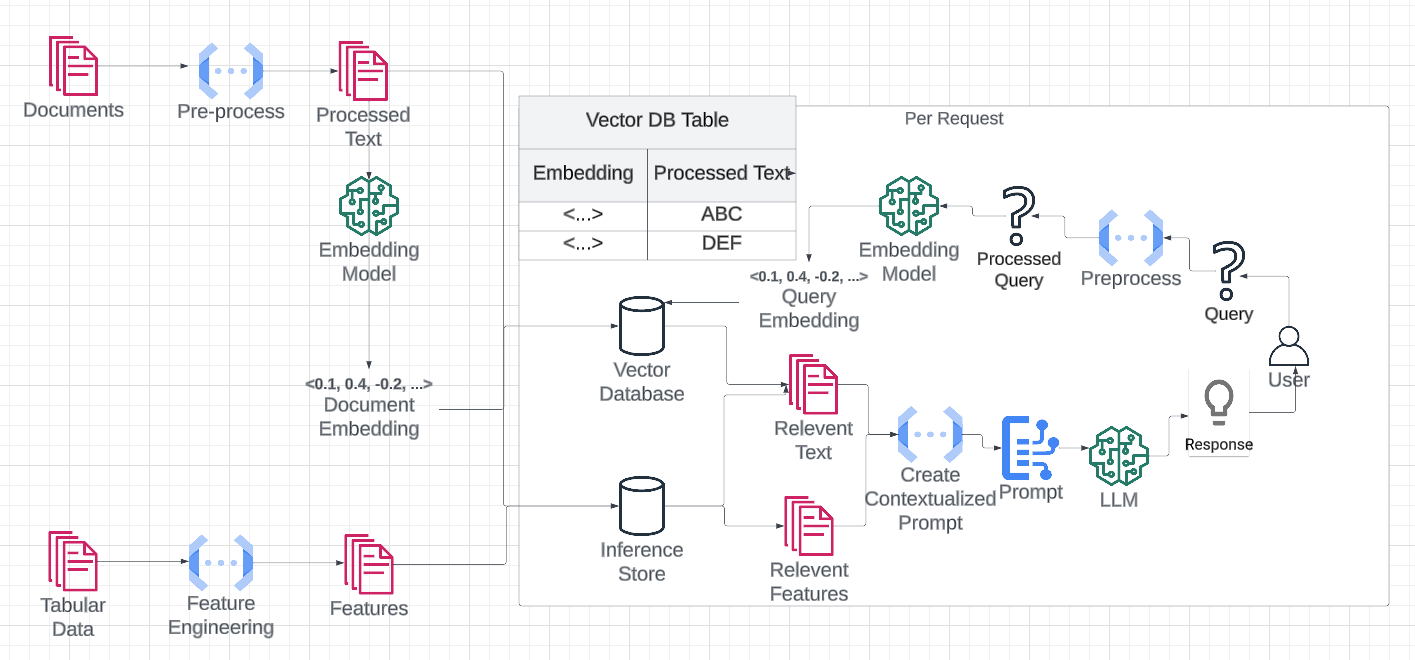
Preprocessing and Metadata Enrichment
Metadata enrichment is the linchpin of transforming raw, unstructured news data into a coherent, actionable format.
By embedding contextual markers like timestamps, geolocations, and named entities, you create a structured framework that enhances both retrieval precision and downstream generation quality.
This process is not merely additive; it fundamentally reshapes how data interacts with the RAG pipeline.
One critical technique is Named Entity Recognition (NER), which identifies and categorizes entities such as people, organizations, and locations within text.
For instance, a financial news system might tag “Federal Reserve” as an organization and “interest rate hike” as an event, enabling the retriever to prioritize relevant updates.
However, the challenge lies in balancing granularity with efficiency—overloading the system with excessive metadata can dilute retrieval accuracy.
Ultimately, metadata enrichment is not just a technical step; it’s a strategic enabler, bridging the gap between chaotic data streams and actionable insights.
Real-Time Indexing Techniques
Real-time indexing thrives on precision and adaptability, not just speed.
The core challenge lies in maintaining a system that can ingest and structure live data without succumbing to latency or noise.
A pivotal technique here is incremental indexing, where only new or updated data is processed, minimizing computational overhead. This ensures that the system remains responsive, even during high-volume news cycles.
Unlike traditional batch indexing, which processes data in bulk, incremental methods rely on event-driven triggers.
For example, when a news API detects a breaking story, the system immediately indexes the content, appending metadata like timestamps and source reliability scores. This modular approach not only accelerates updates but also preserves the integrity of existing indexes.
However, real-time indexing is not without its complexities. One overlooked factor is index fragmentation, where frequent updates can lead to uneven data distribution, reducing retrieval efficiency.
To counter this, organizations like Qatalog employ dynamic rebalancing algorithms, which reorganize indexes periodically to optimize query performance.
Ultimately, the success of real-time indexing hinges on its ability to anticipate and adapt to the unpredictable rhythms of live data, ensuring relevance and reliability in every query.
Advanced Techniques for RAG Optimization
Optimizing Retrieval-Augmented Generation (RAG) systems for real-time news integration requires a shift from static methodologies to dynamic, context-aware strategies.
One transformative approach is contextual embedding refinement, which recalibrates vector representations based on evolving data streams.
For instance, OpenAI’s fine-tuning protocols have improved retrieval accuracy when embeddings are periodically updated with domain-specific news corpora.
This ensures that the system remains aligned with the latest developments, avoiding the pitfalls of outdated context.
Another critical innovation is feedback-driven re-ranking, where user interactions directly influence retrieval priorities. This not only enhances relevance but also reduces retrieval latency, as less pertinent data is deprioritized in real-time.
A common misconception is that these techniques increase computational overhead.
However, by integrating incremental indexing with adaptive pipelines, organizations like Qdrant have achieved scalable solutions that balance speed and precision.
These advancements underscore the importance of continuous optimization, transforming RAG systems into agile, high-performance tools for real-time applications.
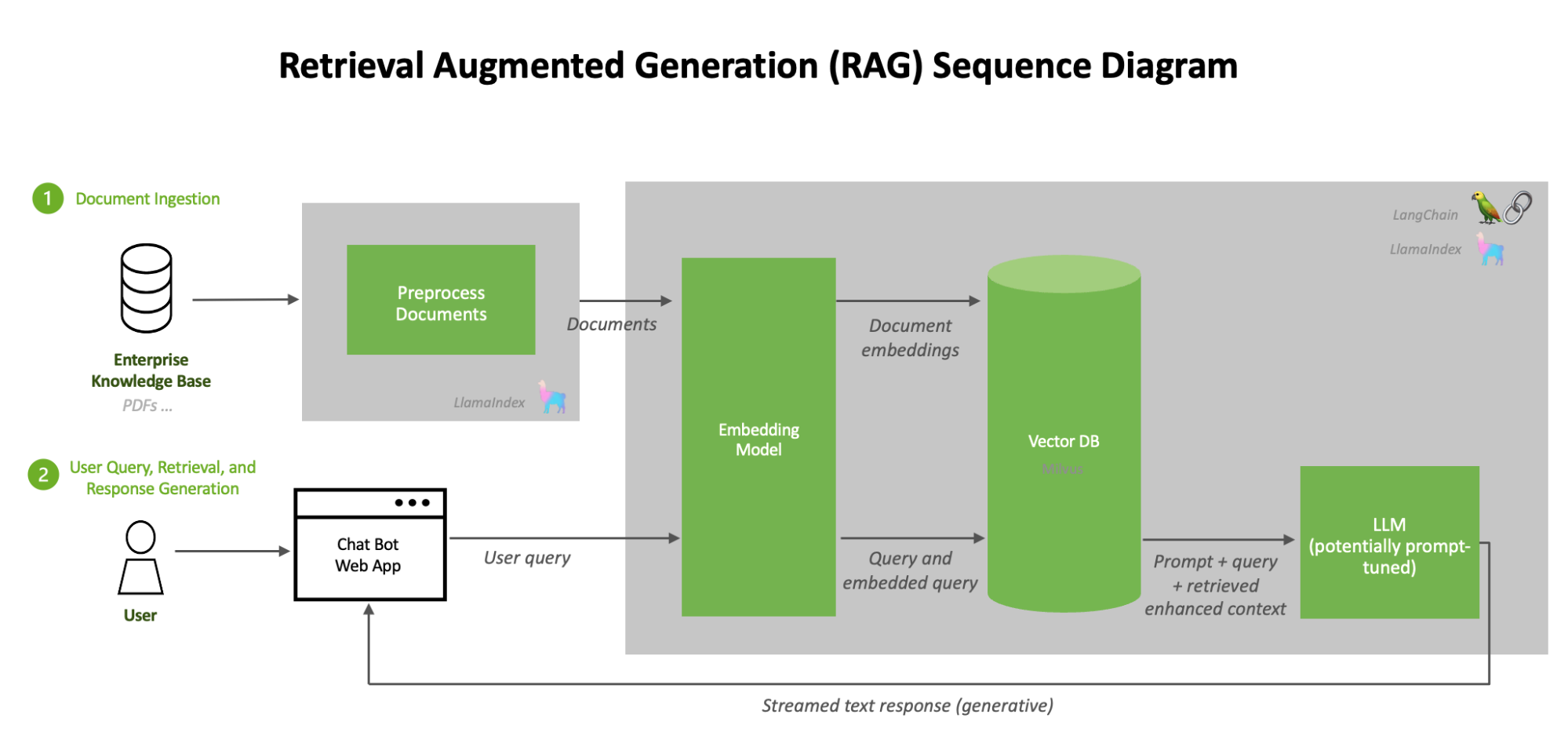
Adaptive Summarization Methods
Adaptive summarization thrives on its ability to adjust outputs as new information emerges dynamically, a necessity in the fast-paced realm of real-time news.
At its core, this method leverages contextual re-ranking algorithms, which continuously evaluate and reorder retrieved data based on evolving narratives.
Unlike static summarization, which risks obsolescence, adaptive systems ensure that summaries remain both current and coherent.
The underlying mechanism involves semantic drift detection, a process that identifies shifts in meaning or focus within a news cycle.
For instance, when a breaking story transitions from speculation to confirmed facts, the summarizer recalibrates to emphasize verified updates. This approach not only preserves accuracy but also aligns with user expectations for clarity and relevance.
A notable implementation comes from Reuters, which employs adaptive pipelines to refine summaries in real time.
By integrating feedback loops—such as user engagement metrics—these systems fine-tune their outputs, mimicking the iterative process of human editors. This ensures that even as stories evolve, the summaries remain contextually rich and actionable.
The challenge lies in balancing speed with depth. Overly aggressive updates can fragment narratives, while slower systems risk irrelevance.
The solution? Modular architectures that prioritize both agility and coherence, setting a new standard for real-time summarization.
Multi-Modal Integration for Contextual Richness
Integrating multiple data modalities into RAG workflows transforms how systems interpret and respond to complex queries.
A critical technique here is joint embedding spaces, where text, images, and videos are encoded into a unified vector space.
This alignment ensures that the system can seamlessly correlate disparate data types, uncovering relationships that would remain hidden in text-only approaches.
The importance of this lies in its ability to capture contextual subtleties.
For instance, a news headline about a “market rally” paired with a graph showing declining stock volumes reveals a contradiction that text alone might miss.
By embedding visual and textual data together, the system gains a richer understanding of such nuances, enabling more accurate and actionable insights.
One notable implementation is the use of models like CLIP, which align text and image embeddings.
These models excel in scenarios where visual cues significantly enhance textual context, such as identifying sentiment shifts in financial news.
However, maintaining balance can be challenging—overemphasis on one modality can skew results, particularly in ambiguous cases.
To optimize this integration, continuous feedback loops refine embeddings, ensuring adaptability to evolving data. This dynamic approach not only enhances precision but also sets a new benchmark for contextual intelligence in RAG systems.
Hybrid Approaches in RAG Systems
Hybrid approaches in Retrieval-Augmented Generation (RAG) systems redefine how we balance contextual depth with retrieval precision.
By integrating Knowledge Graphs (KGs) with vector-based retrieval, these systems achieve a synergy that neither method can accomplish alone.
Think of it as combining a map’s structured routes with a compass’s flexibility—one provides clarity, the other adaptability.
For instance, HybridRAG, developed by researchers at NVIDIA and BlackRock, excels in financial document analysis by merging GraphRAG’s entity relationships with VectorRAG’s semantic breadth.
This dual-layered architecture ensures that even ambiguous queries, such as those involving indirect relationships, yield actionable insights.
A practical example? Tracing the ripple effects of a regulatory change across interconnected industries—a task that purely vector-based systems often oversimplify.
The real breakthrough lies in context fusion, where structured KG data enriches vector embeddings. This process not only enhances retrieval accuracy but also enables multi-hop reasoning, a critical capability for resolving complex, real-time queries.
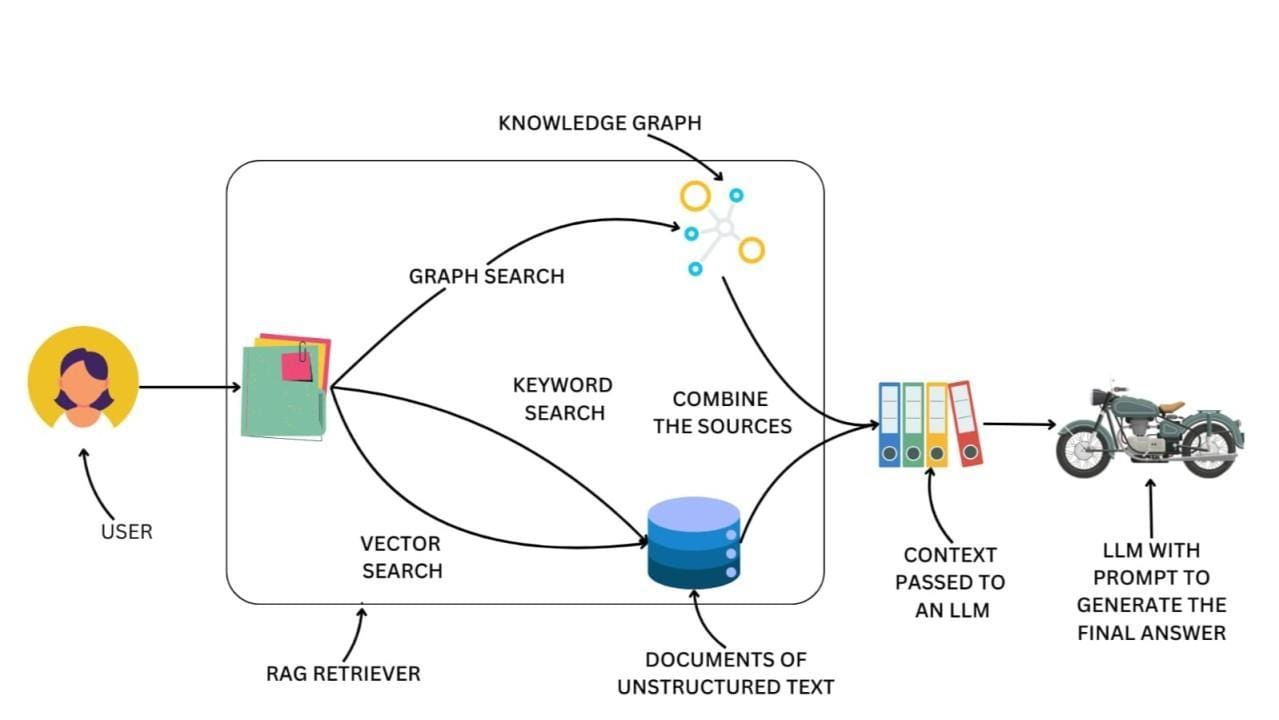
GraphRAG and HybridRAG Explained
GraphRAG and HybridRAG excel at handling complex, context-rich queries, but their true strength lies in managing narrative coherence during real-time news integration.
GraphRAG leverages knowledge graphs to map intricate relationships between entities, ensuring that even fragmented updates are contextualized within a structured framework.
HybridRAG, on the other hand, combines this structured approach with the agility of vector-based retrieval, enabling it to adapt dynamically to evolving narratives.
The key mechanism that sets HybridRAG apart is its context fusion process, where knowledge graph data enriches vector embeddings.
This allows the system to perform multi-hop reasoning, connecting seemingly unrelated data points to uncover deeper insights.
For example, in financial news, HybridRAG can link a regulatory announcement to its potential impact on specific industries by tracing relationships across both structured and unstructured data.
However, this dual-layered approach introduces challenges.
Synchronizing updates between the knowledge graph and vector database can create latency, particularly during high-volume news cycles.
To mitigate this, some implementations, like those by NVIDIA, employ incremental indexing and dynamic rebalancing algorithms, ensuring that retrieval remains both fast and accurate.
Ultimately, these systems' success hinges on their ability to balance precision with adaptability, making them indispensable for high-stakes, real-time applications.
Integrating Knowledge Graphs with Vector Retrieval
Integrating knowledge graphs (KGs) with vector retrieval transforms how systems interpret complex queries by enabling a seamless blend of structured reasoning and semantic flexibility.
At its core, this integration relies on context fusion, where KGs enrich vector embeddings with explicit relationships, creating a unified framework for nuanced understanding.
One critical mechanism is multi-hop reasoning, which allows the system to traverse interconnected entities within the KG while leveraging vector embeddings for semantic depth.
For instance, in financial news, this approach can trace the cascading effects of a regulatory change across industries, uncovering insights that standalone vector models might overlook.
However, achieving this synergy requires precise synchronization between the KG and vector database, a challenge amplified in real-time applications.
A notable implementation is Neo4j’s integration with FAISS, where Cypher queries extract structured insights from the KG, while vector search retrieves semantically relevant documents.
This dual-layered pipeline ensures both accuracy and adaptability, though it demands significant computational resources to maintain low latency during high-volume updates.
Despite its strengths, this hybrid approach faces limitations, such as increased latency from dual retrieval processes and the complexity of maintaining consistent updates.
Addressing these challenges requires dynamic indexing techniques and robust pipelines, ensuring that the integration remains both scalable and efficient.
Ultimately, this synergy redefines how AI systems contextualize and respond to intricate, real-world queries.
FAQ
What are the key challenges in integrating real-time news into Retrieval-Augmented Generation (RAG) workflows?
Key challenges include managing unstructured data, maintaining low latency, and filtering irrelevant updates. Real-time RAG systems must balance speed with context, relying on salience analysis and metadata tagging to keep results accurate.
How can entity relationships and semantic metadata improve the accuracy of news integration in RAG systems?
Entity relationships link related data points, while semantic metadata provides structure. Together, they improve context in real-time retrieval, allowing RAG systems to deliver responses that reflect both recent and relevant updates.
What role does salience analysis play in optimizing the retrieval of recent news for RAG workflows?
Salience analysis highlights important entities and events, allowing RAG systems to focus on what matters. It helps rank updates by relevance and filters noise, improving retrieval quality in time-sensitive situations.
How can co-occurrence optimization enhance the contextual relevance of news data in RAG pipelines?
Co-occurrence optimization strengthens semantic links by identifying patterns of entities that often appear together. This makes the graph more meaningful and helps RAG systems pull contextually accurate responses from evolving news streams.
What are the best practices for maintaining data integrity and reducing noise during real-time news ingestion in RAG systems?
Reduce noise using structured metadata, entity recognition, and filtering rules. Incremental indexing and validation help maintain data quality, ensuring that RAG systems retrieve timely updates without losing context or accuracy.
Conclusion
Efficient integration of recent news into RAG workflows requires careful alignment between speed and context.
These systems can stay current without losing precision by using techniques like metadata tagging, salience analysis, and co-occurrence mapping.
As real-time data becomes central to decision-making, building flexible and context-aware RAG pipelines will be key to navigating high-stakes environments with clarity.