
When and How to Rephrase Queries for Optimal RAG Accuracy
Rephrasing queries is key to optimizing RAG accuracy. This guide explores when and how to adjust queries for better retrieval, improved contextual understanding, and more precise AI-generated responses in knowledge-based applications.


Most RAG systems fail not because of poor models or weak retrieval mechanisms but due to ineffective queries.
A user searching for “best AI practices” might receive general results, while another asking “AI practices for fraud detection in banking” gets precisely what they need. The difference? A well-structured query.
RAG systems depend on clear, context-rich inputs to retrieve the right information. Vague, overly broad, or highly specific queries often lead to irrelevant results. In many cases, improving accuracy isn’t about changing the model—it’s about adjusting the way queries are phrased.
This article breaks down the when and how of query rephrasing—whether before retrieval to set the system on the right track, after an initial search to refine results, or dynamically based on user feedback.
Understanding these strategies can significantly enhance retrieval accuracy and improve AI-driven applications.
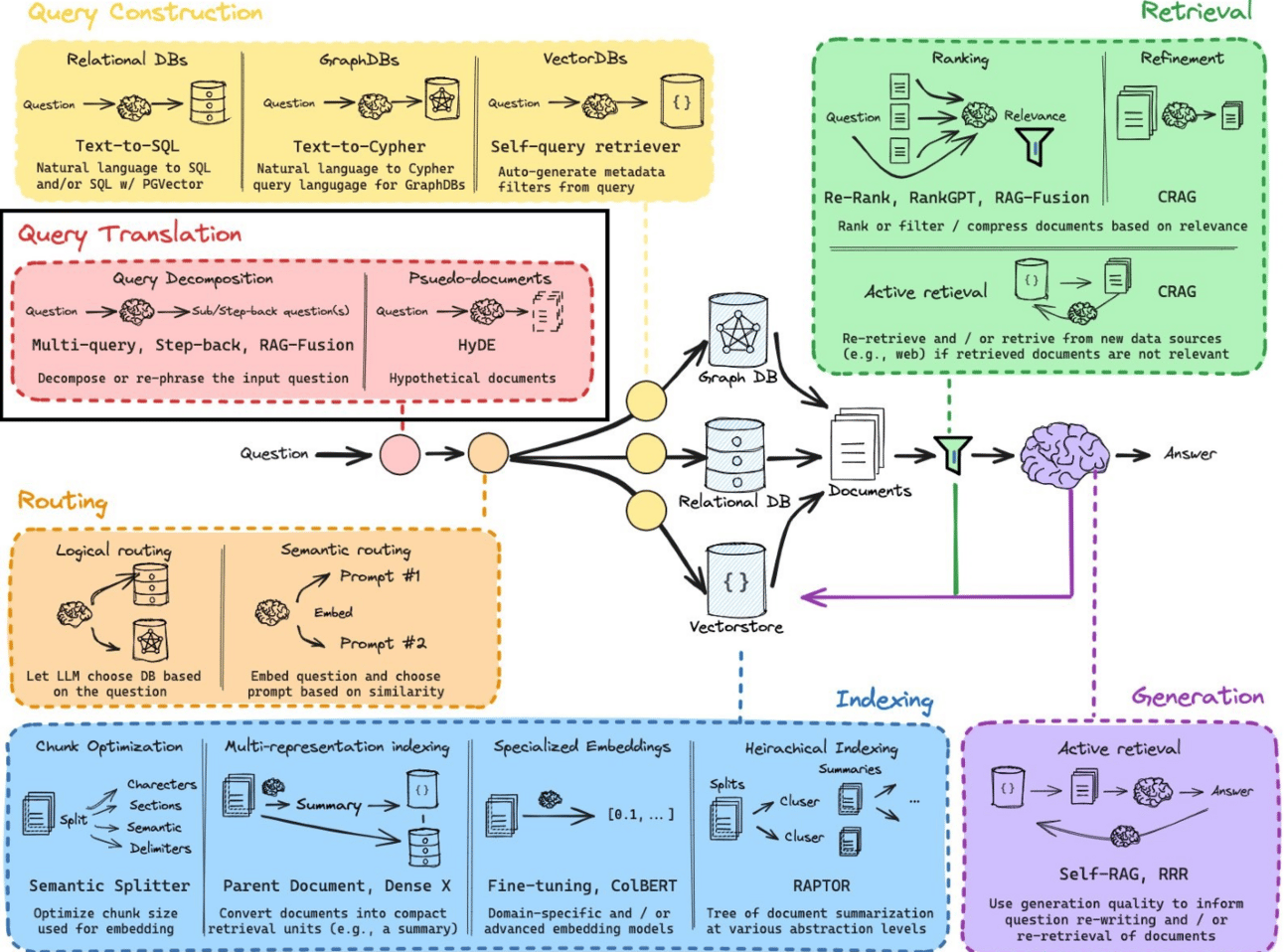
Basic Architecture and Components of RAG
Let’s zoom in on the retrieval mechanism, the unsung hero of RAG systems. This component doesn’t just fetch data—it decides what data matters.
Think of it as the librarian who knows exactly which book (and chapter) you need, even if your request is vague.
Here’s the magic: vector databases. These databases use embeddings to map your query into a multidimensional space, where similar data points cluster together. Why does this work?
Because it’s not about exact keyword matches—it’s about contextual similarity. For example, when Shopify implemented a RAG-powered customer support system, their retrieval engine reduced irrelevant responses and improved ticket resolution times.
But retrieval isn’t perfect. If your query is poorly phrased, even the best vector database can’t save you.
That’s why companies like Google Cloud integrate re-rankers—algorithms that refine results based on relevance scores. This ensures the most contextually aligned data rises to the top.
Role of Query Rephrasing in RAG
Query rephrasing is the secret sauce that transforms a mediocre RAG system into a precision tool.
Why? Because even the most advanced retrieval mechanisms can’t compensate for poorly phrased inputs. Let’s break it down.
Techniques like Named Entity Recognition (NER) and semantic enrichment help identify key terms and expand queries with related concepts.
For instance, a search for “neural correlates of consciousness” might include terms like “fMRI” or “phenomenology,” unlocking interdisciplinary insights. This approach is especially powerful in academic research, where precision is non-negotiable.
Looking ahead, reinforcement learning-based rephrasing could take this further. Imagine a system that learns from every failed query, iteratively refining its rewriting strategies.
The result? A RAG system that not only adapts but anticipates user needs, setting new benchmarks for accuracy and relevance.
Timing of Query Rephrasing
Timing is everything when it comes to query rephrasing in RAG systems. Rephrase too early, and you risk overcomplicating a simple query.
Wait too long, and you might miss the chance to salvage a poorly performing search. So, when’s the sweet spot?
Before the First Retrieval Attempt
Think of this as your pre-game warm-up. If the query is vague or overly complex, rephrasing upfront can save the system from chasing irrelevant data. For example, a query like “best practices in AI” could be refined to “best practices in AI for healthcare applications.” This ensures the system starts on the right foot.
After Initial Results Are Off-Target
If the first retrieval round feels like a wild goose chase, it’s time to rephrase. A legal research tool, for instance, might rewrite “contest a will” into “legal grounds for contesting a will,” aligning with indexed legal terms.
When User Feedback Indicates Gaps
Interactive refinement is key. If users flag missing details, rephrasing can bridge the gap, ensuring the next retrieval hits the mark.
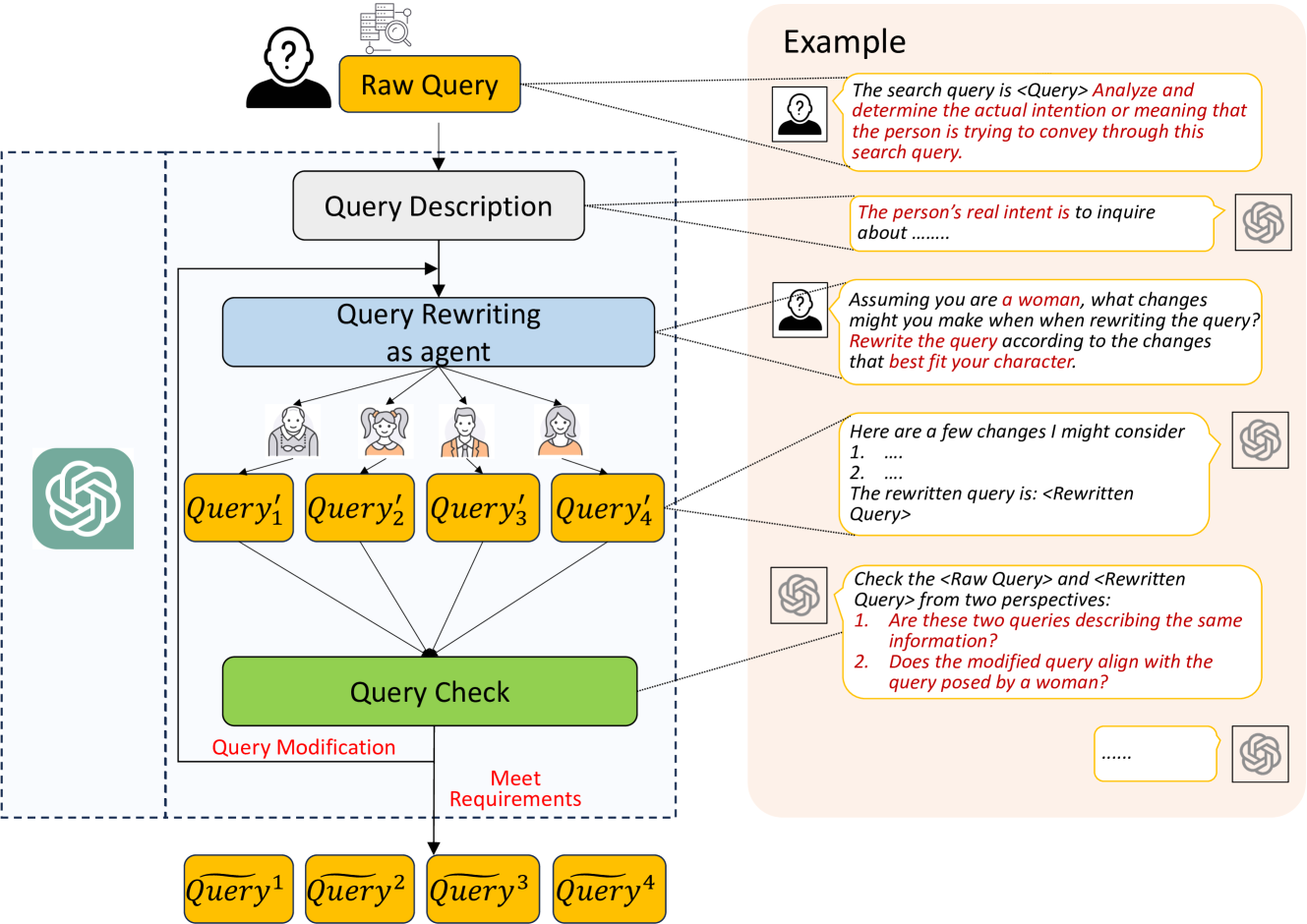
Identifying Optimal Moments for Rephrasing
Pinpointing the right moment to rephrase a query can make or break a RAG system’s performance.
One overlooked factor? The feedback loop.
A well-designed feedback loop helps refine queries dynamically, ensuring the system continuously improves retrieval accuracy.
For example, an e-commerce chatbot struggling with ambiguous customer requests can track common refinements, like reinterpreting “return policy” as “return policy for damaged products,” to improve accuracy. Over time, this loop helps the system anticipate user intent, making retrieval faster and more precise.
Timing also hinges on query complexity. A vague query like “AI trends” might work for a general overview but fails in niche contexts like healthcare.
Here, rephrasing upfront—e.g., “AI trends in medical imaging”—aligns the query with domain-specific data, saving retrieval cycles.
Another critical moment? Post-retrieval refinement.
Google Cloud’s re-rankers, for example, adjust results dynamically based on relevance scores. If the first pass misses the mark, rephrasing terms to match indexed keywords (e.g., “contest a will” to “legal grounds for contesting a will”) ensures the next attempt is laser-focused.
Looking ahead, adaptive systems could predict rephrasing needs before users even notice gaps. By integrating user behavior analytics, RAG systems might soon anticipate and resolve ambiguities autonomously, redefining query optimization.
Impact of Timing on Retrieval and Generation
Timing in query rephrasing isn’t just a technical detail—it’s the linchpin for balancing retrieval precision and generative fluency.
But here’s the twist: delaying rephrasing can sometimes yield better results. Google Cloud’s re-rankers dynamically adjust relevance scores post-retrieval, allowing systems to refine queries only after initial results miss the mark. This approach ensures that rephrasing doesn’t overcomplicate simple queries upfront.
A lesser-known factor? The temporal relevance of data. In fast-evolving fields like healthcare, rephrasing queries to include time-sensitive keywords (e.g., “latest COVID-19 treatments”) ensures retrieval aligns with current knowledge.
Methods of Query Rephrasing
Rephrasing a query is like tuning a radio—small adjustments can turn static into clarity. The key is knowing which method to use and when. Let’s break it down.
Query Expansion
Think of this as adding more ingredients to a recipe. If your query is too narrow, sprinkle in related terms or synonyms. For example, “neural correlates of consciousness” could expand to include “fMRI” or “phenomenology.” This approach helped academic researchers uncover interdisciplinary studies they’d otherwise miss.
Query Simplification
Sometimes less is more. Overly complex queries confuse RAG systems, like asking a chef for “a gastronomic exploration of legumes.” Simplify it to “bean recipes,” and voilà—better results.
Contextual Enrichment
Add a dash of context to vague queries. Instead of “AI trends,” try “AI trends in medical imaging.” Shopify nailed this by refining “order issue” to “refund policy for delayed orders,” cutting irrelevant responses.
Iterative Refinement
Rephrasing isn’t one-and-done. Test, tweak, and repeat. Google Cloud’s re-rankers thrive on this, dynamically refining queries post-retrieval for laser-focused results.
Each method is a tool—use them wisely to unlock your RAG system’s full potential.
Rule-Based vs. Machine Learning Approaches
When it comes to query rephrasing, the choice between rule-based and machine learning (ML) approaches isn’t just about technology—it’s about context, scalability, and precision. Rule-based systems shine in domains with rigid structures, like legal or medical research.
For instance, a legal research tool used by LexisNexis employs predefined rules to map vague queries like “contest a will” into precise legal terms such as “undue influence” or “testamentary capacity.” This approach reduced search times and streamlined case preparation.
Rule-based systems are predictable but lack adaptability, while ML approaches thrive on complexity but demand extensive training data.
A hybrid model could bridge this gap. Imagine combining rule-based precision with ML’s adaptability—like using rules for initial rephrasing and ML for iterative refinement.
Looking ahead, adaptive frameworks blending these methods could redefine query optimization, offering both reliability and responsiveness. The future? Smarter, faster, and more intuitive RAG systems.
Techniques for Semantic Matching and Expansion
Semantic matching and expansion are game-changers for RAG systems, especially when dealing with ambiguous or lexically sparse queries.
Why? Because they focus on intent rather than exact wording. Let’s break it down.
Tools like word2vec use embedding-based techniques to map queries into a multidimensional space, clustering related terms. For instance, a query for “solar energy” might expand to include “renewable energy” or “photovoltaic cells,” ensuring broader yet precise retrieval.
However, over-expansion is a valid issue. Adding too many terms can dilute the query’s focus. Companies like Google Cloud mitigate this with re-rankers, dynamically prioritizing results based on relevance scores.
Looking ahead, adaptive semantic models could refine this further. Imagine systems that learn user intent patterns in real-time, preemptively adjusting queries.
Evaluating Rephrasing Effectiveness
Think of query rephrasing like tuning a guitar. If the strings are too loose or too tight, the melody falls flat.
The same goes for RAG systems—poorly phrased queries lead to irrelevant or incomplete results.
But how do you know if your rephrasing is hitting the right notes?
Start by measuring retrieval relevance. Shopify’s customer support system, for instance, saw a drop in irrelevant responses after refining vague queries like “order issue” into actionable ones like “refund policy for delayed orders.” That’s a clear win.
Next, look at user satisfaction. If users are flagging fewer gaps or asking follow-up questions, your rephrasing is working. Legal research tools, for example, save hours by translating “contest a will” into precise terms like “undue influence.”
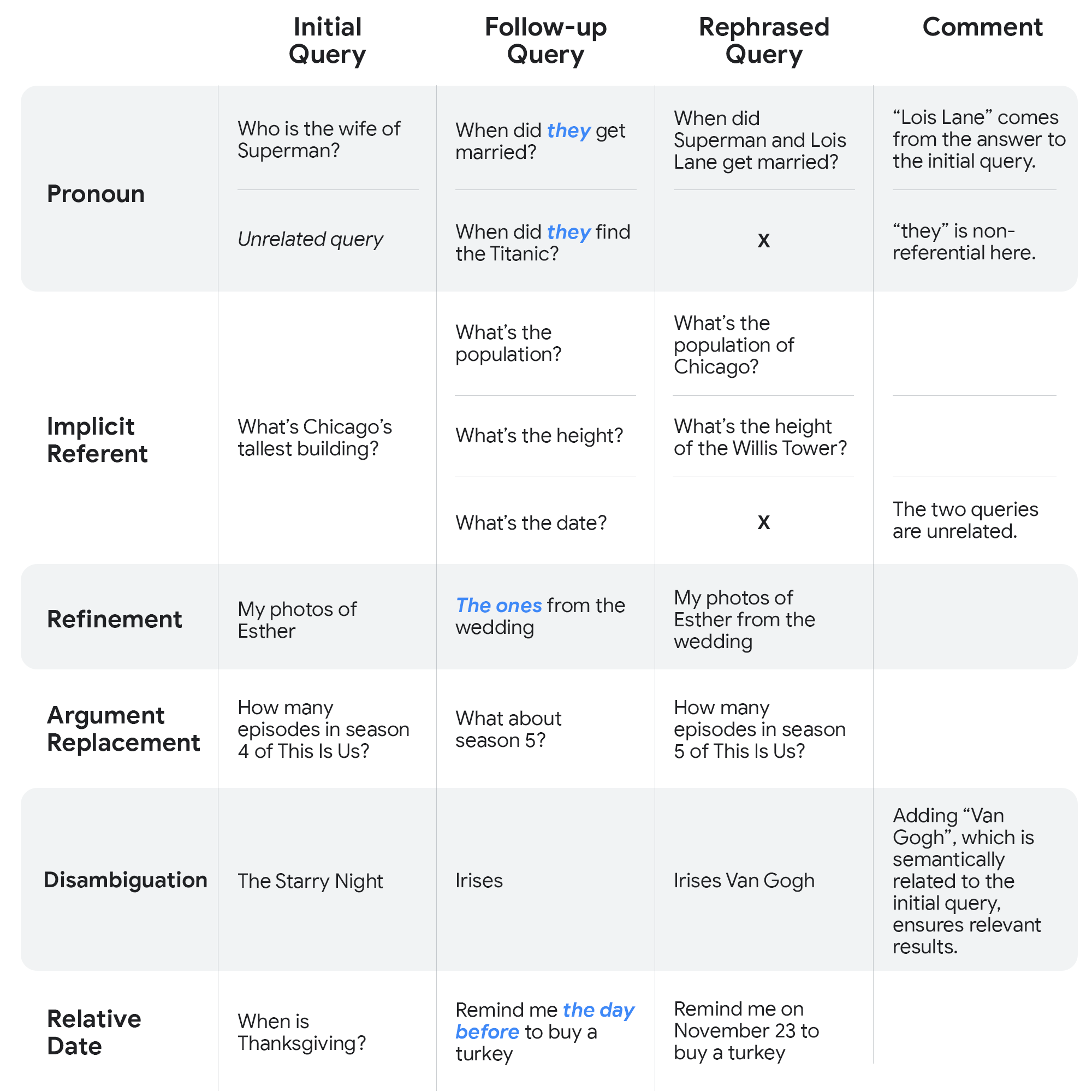
Metrics for Measuring Accuracy and Relevance
Measuring accuracy and relevance in query rephrasing isn’t just about counting hits—it’s about understanding why certain queries succeed.
One standout metric is Mean Reciprocal Rank (MRR), which prioritizes the position of the first relevant result.
But here’s where it gets interesting: semantic precision. This metric evaluates how well a query aligns with the intent behind user input.
By focusing on intent rather than keywords, companies can improve retrieval accuracy in customer support systems by over 20%.
A lesser-known factor? Temporal relevance. In fast-moving fields like healthcare, queries must adapt to time-sensitive data.
For instance, rephrasing “COVID-19 treatments” to “latest COVID-19 treatments” ensures retrieval aligns with current knowledge.
Looking ahead, combining predictive analytics with user feedback could create adaptive metrics that evolve in real-time.
Imagine a system that not only measures relevance but anticipates user needs, setting a new standard for RAG optimization. The takeaway? Metrics should guide systems toward smarter, faster, and more context-aware retrieval.
FAQ
What are the signs that a query needs rephrasing in a RAG system?
Queries that are vague, too broad, or overly specific often produce irrelevant results. If retrieval repeatedly fails to surface useful documents or user feedback highlights missing context, rephrasing is necessary. Effective query modifications improve precision by aligning language with indexed data.
How does query rephrasing improve retrieval accuracy in RAG systems?
Rephrasing optimizes retrieval by refining language, expanding keywords, and clarifying intent. This reduces ambiguity, improves semantic matching, and ensures indexed content aligns with user needs. Structured modifications enhance search efficiency, leading to more relevant results in legal, healthcare, and customer support applications.
Which rephrasing techniques work best for domain-specific RAG applications?
Effective techniques include query expansion (adding synonyms and related terms), contextual enrichment (aligning with domain-specific language), and named entity recognition (NER) to isolate key concepts. Methods like reinforcement learning and knowledge graph integration refine query structure for specialized use cases.
When should query rephrasing occur in a RAG retrieval process?
Rephrasing is most effective before retrieval to prevent ambiguous searches, after initial retrieval if results lack relevance, and during iterative refinement based on user feedback. In real-time systems, adaptive models predict rephrasing needs dynamically to enhance accuracy and retrieval efficiency.
How do entity relationships and semantic context affect query rephrasing?
Entity relationships define how concepts connect within a domain. By mapping these relationships, rephrased queries capture critical links between terms, improving retrieval precision. Semantic context enriches searches by incorporating related keywords, ensuring relevant results in legal, medical, and academic RAG applications.
Conclusion
Query rephrasing is a key factor in improving retrieval-augmented generation (RAG) systems.
Poorly structured queries reduce accuracy, leading to irrelevant or incomplete results. By refining language, expanding key terms, and applying domain-specific techniques, retrieval becomes more precise.
Timing rephrasing correctly—whether before, during, or after retrieval—ensures optimal performance.
As machine learning models evolve, expect adaptive rephrasing strategies that anticipate user intent, further enhancing RAG accuracy across industries like legal research, healthcare, and enterprise search.