
Retrieval-Augmented Generation (RAG): The Definitive Guide [2025]
Explore Retrieval-Augmented Generation (RAG) like never before. Unlock its benefits, discover applications, and master the game-changing 2025 strategies!

![Retrieval-Augmented Generation (RAG): The Definitive Guide [2025]](https://storage.ghost.io/c/22/36/22368316-957e-43c3-a4f9-93111ba87e24/content/images/size/w2000/2025/01/Untitled-design--48-.jpg)
Think about an AI system that not only generates text but also actively retrieves the most relevant, up-to-date information to inform its responses. This is not a distant future—it’s happening now, and it’s reshaping how we think about artificial intelligence.
Here’s a surprising fact: traditional language models, no matter how large, are inherently limited by the static nature of their training data. They can craft eloquent responses but often lack the ability to adapt to new information or context-specific queries. Retrieval-Augmented Generation (RAG) changes this paradigm entirely.
Why does this matter today? As industries increasingly rely on AI for decision-making, the demand for systems that are both accurate and context-aware has never been higher. RAG offers a solution by bridging the gap between static knowledge and dynamic, real-time data retrieval. But how does it work, and what are its broader implications for AI and society?
This guide will explore these questions, uncovering how RAG not only enhances AI’s capabilities but also challenges our assumptions about what generative models can achieve. Along the way, we’ll delve into its technical foundations, practical applications, and the ethical considerations that come with such transformative technology.
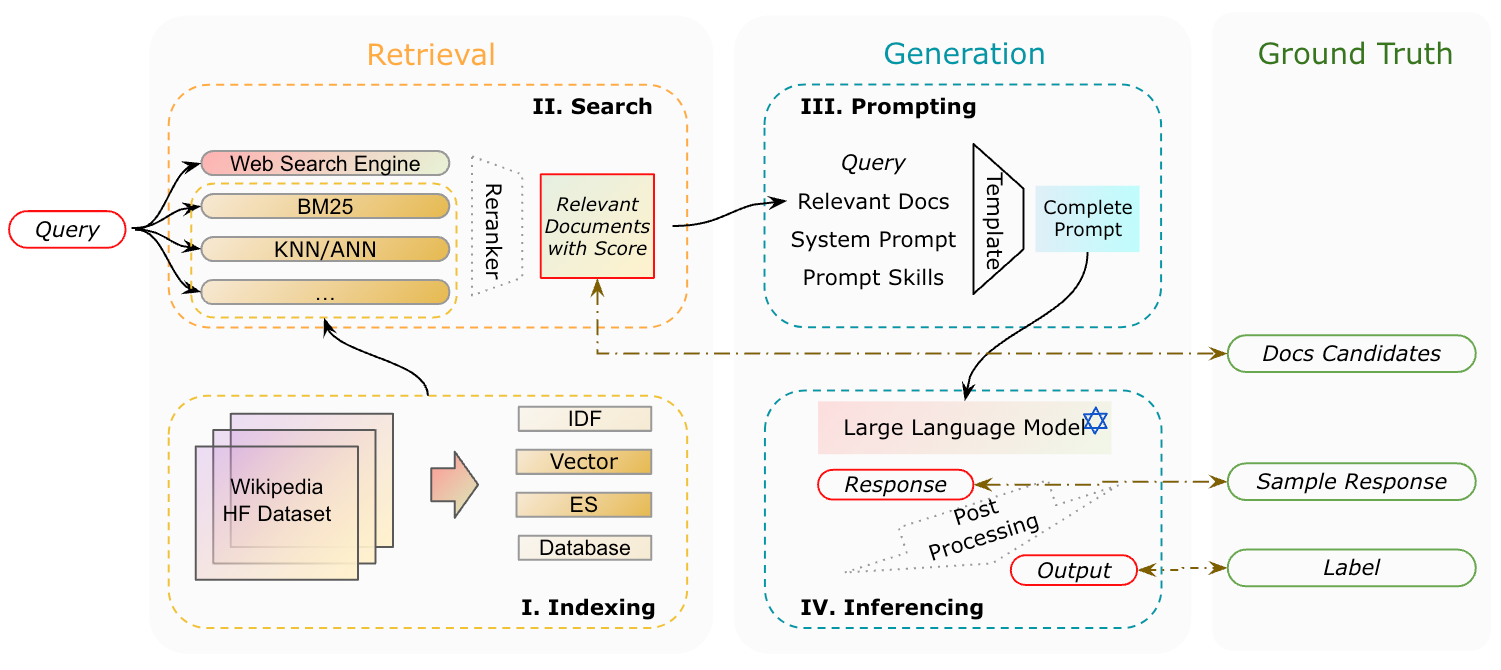
What Is Retrieval-Augmented Generation?
One of the most fascinating aspects of Retrieval-Augmented Generation (RAG) is its ability to dynamically integrate external knowledge into the generative process. Unlike traditional language models that rely solely on pre-trained data, RAG employs a retrieval mechanism to fetch relevant, real-time information from external sources. This retrieval step is not just a technical add-on—it fundamentally transforms how AI systems handle context, enabling them to adapt to evolving datasets and user-specific queries.
Consider a real-world application: legal research. A RAG-powered system can retrieve the latest case law or statutes from a legal database and generate summaries tailored to a lawyer’s specific question. This approach not only saves time but also ensures that the output is grounded in the most current and relevant information.
Interestingly, the effectiveness of RAG hinges on the quality of the retrieval mechanism. Dense vector representations, for instance, have proven superior to traditional keyword-based searches by capturing semantic relationships between queries and documents. However, challenges like retrieval bias or incomplete datasets can still influence outcomes, underscoring the need for robust data curation.
Looking ahead, the interplay between retrieval and generation opens doors to interdisciplinary innovations. For example, combining RAG with semantic search algorithms or knowledge graphs could further enhance its ability to provide nuanced, context-aware responses. This evolution positions RAG as a cornerstone for AI systems that demand both precision and adaptability.
The Evolution of RAG Up to 2025
One pivotal advancement in RAG by 2025 is the integration of adaptive retrieval mechanisms that dynamically adjust based on user intent and query complexity. Unlike static retrieval pipelines, these mechanisms leverage reinforcement learning to optimize the selection of external data sources in real time. This ensures that the retrieved information aligns more closely with the nuanced demands of diverse applications.
For instance, in healthcare diagnostics, adaptive retrieval enables RAG systems to prioritize peer-reviewed medical studies over general web content when generating patient-specific recommendations. This not only enhances accuracy but also builds trust in AI-driven solutions.
A lesser-known factor influencing RAG’s evolution is the trade-off between retrieval depth and computational efficiency. While deeper retrieval layers improve context relevance, they also increase latency. Techniques like multi-stage retrieval—where initial broad searches are refined through focused iterations—help balance this trade-off effectively.
Looking forward, integrating multimodal data sources (e.g., text, images, and structured data) could further expand RAG’s capabilities, enabling breakthroughs in fields like education and scientific research.
Importance of RAG in Modern NLP
A critical aspect of RAG’s importance lies in its ability to mitigate hallucinations in generative models. Traditional language models often generate plausible but incorrect information due to their reliance on static training data. RAG addresses this by incorporating a retrieval component that grounds responses in real-time, external knowledge sources, ensuring factual accuracy.
For example, in legal document analysis, RAG systems can retrieve and cite specific statutes or case law, reducing the risk of errors in high-stakes environments. This capability not only enhances reliability but also aligns with the growing demand for explainable AI.
Interestingly, the quality of retrieval embeddings plays a lesser-known yet pivotal role. Dense vector representations, fine-tuned for domain-specific tasks, outperform generic embeddings in retrieving relevant content.
To maximize RAG’s potential, practitioners should focus on iterative fine-tuning of both retrieval and generative components, creating a feedback loop that continuously improves performance across diverse NLP applications.
Understanding retrieval-augmented generation
At its core, Retrieval-Augmented Generation (RAG) combines two powerful paradigms: retrieval and generation. Think of it as a librarian and a storyteller working together—the librarian fetches the most relevant books, while the storyteller weaves a narrative using the retrieved information. This synergy ensures that responses are both contextually rich and factually grounded.
One common misconception is that RAG simply appends retrieved data to a generative model. In reality, the retrieval process dynamically influences the generation phase, enabling nuanced responses tailored to specific queries. For instance, in healthcare, RAG systems can retrieve the latest clinical guidelines and generate patient-specific treatment plans, ensuring both accuracy and personalization.
A key challenge lies in balancing retrieval depth with computational efficiency. Techniques like multi-stage retrieval, where initial broad searches are refined iteratively, have proven effective. By addressing these complexities, RAG is redefining how AI systems interact with vast, ever-changing knowledge bases.
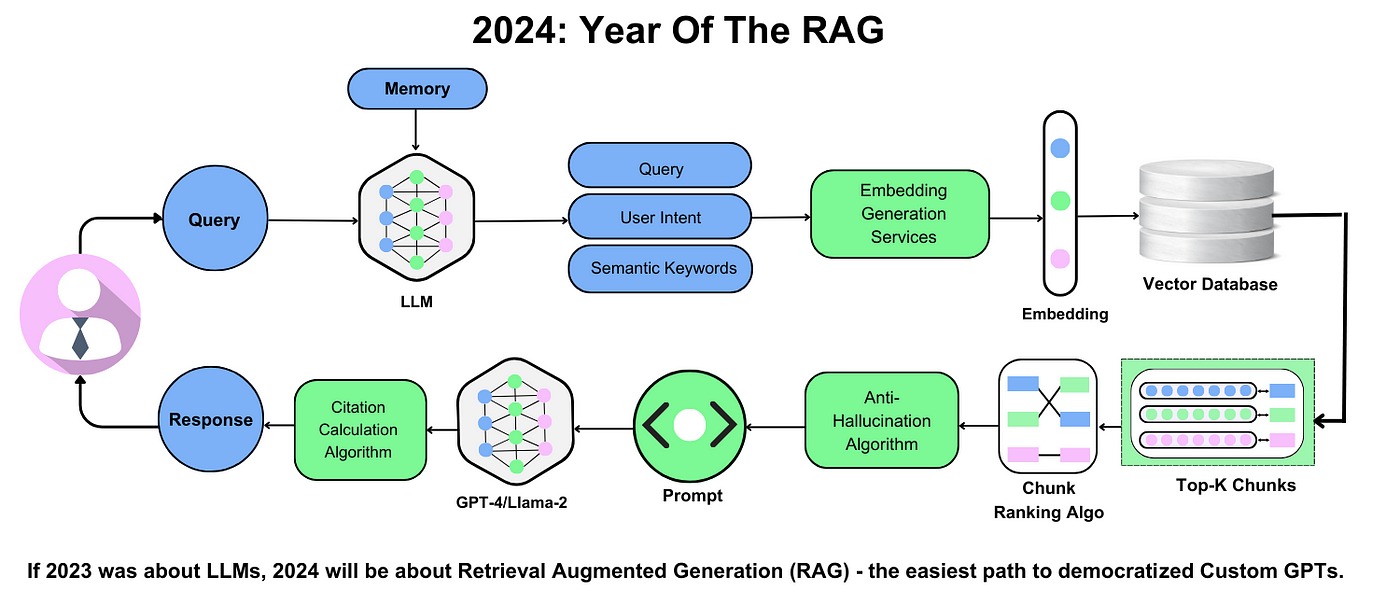
Core Concepts of RAG
One critical concept in RAG is the integration of dense retrieval mechanisms. Unlike traditional keyword-based retrieval, dense retrieval uses vector embeddings to represent both queries and documents in a shared semantic space. This allows the system to identify relevant information even when the query and source use different terminologies—a game-changer in fields like legal research, where precise language varies across jurisdictions.
Dense retrieval works because it captures the underlying meaning of text rather than relying on surface-level matches. For example, a query about "renewable energy incentives" might retrieve documents discussing "solar tax credits" or "wind energy subsidies," even if those exact terms aren’t in the query. This semantic flexibility is powered by transformer-based models like BERT, which excel at encoding contextual relationships.
However, dense retrieval isn’t without challenges. It requires significant computational resources for training and inference. To mitigate this, techniques like approximate nearest neighbor (ANN) search optimize retrieval speed without sacrificing accuracy. As RAG evolves, these innovations will continue to expand its applicability across domains.
Components: Retriever and Generator
A key aspect of the retriever is embedding creation, where queries and documents are transformed into high-dimensional vectors. This process is critical because the quality of these embeddings directly impacts retrieval accuracy. Models like Sentence-BERT excel here, as they capture nuanced semantic relationships, enabling the retriever to match queries with contextually relevant documents—even when exact terms differ.
For the generator, cross-attention mechanisms are pivotal. By aligning retrieved embeddings with the query, the generator can focus on the most relevant information during response generation. This approach is particularly effective in healthcare applications, where precision is vital. For instance, a RAG system can retrieve clinical guidelines and generate patient-specific recommendations, ensuring both accuracy and contextual relevance.
One overlooked factor is retrieval noise—irrelevant documents retrieved due to embedding errors. Addressing this with re-ranking models or filtering heuristics can significantly enhance output quality. Moving forward, tighter integration between retriever and generator will unlock even greater potential.
How RAG Differs from Traditional NLP Models
One critical distinction lies in dynamic knowledge integration. Traditional NLP models rely solely on static training data, which limits their ability to adapt to new information. In contrast, RAG incorporates a retrieval mechanism that accesses external, up-to-date sources, enabling it to respond to evolving queries—such as breaking news or recent scientific discoveries.
This adaptability is particularly impactful in legal research. For example, a RAG system can retrieve the latest case law or statutes, ensuring that generated legal advice reflects current regulations. Traditional models, by comparison, might provide outdated or incomplete insights due to their static nature.
A lesser-known challenge in RAG is retrieval bias, where the system disproportionately favors certain sources. Addressing this requires diversity-aware retrieval algorithms to ensure balanced outputs. As RAG evolves, its ability to bridge static and dynamic knowledge paradigms will redefine how NLP systems interact with real-world data.
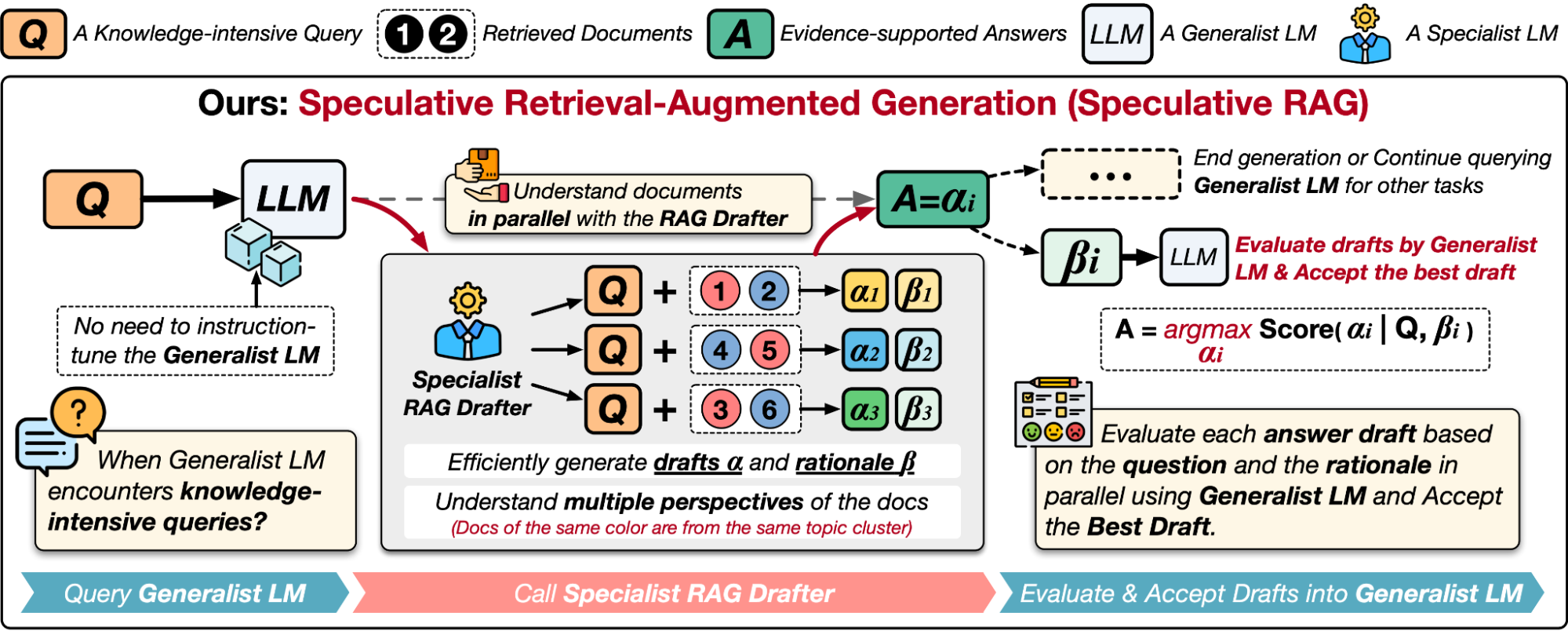
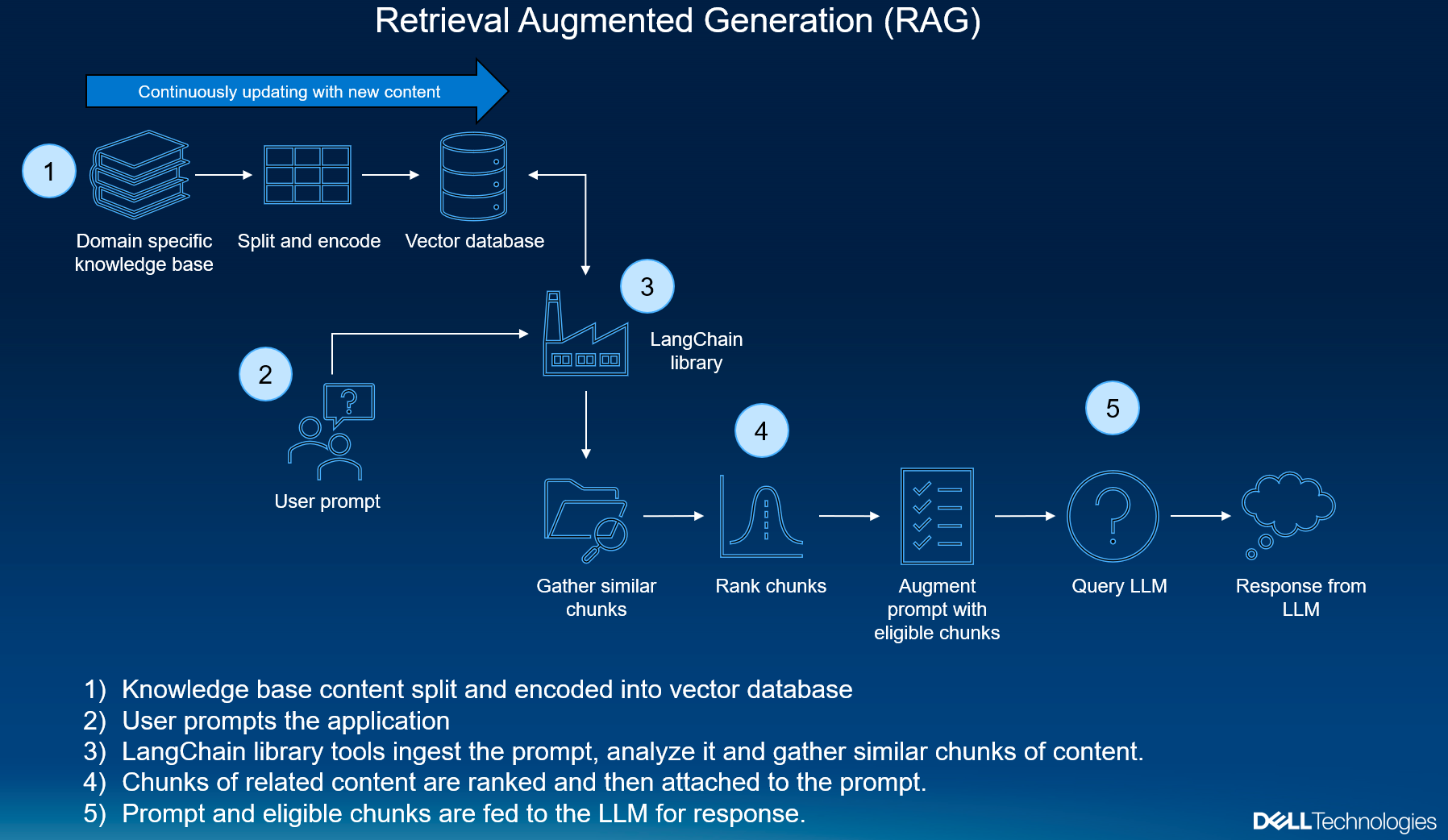
How Retrieval-Augmented Generation Works
At its core, Retrieval-Augmented Generation (RAG) operates by combining two distinct yet complementary processes: retrieval and generation. Think of it as a two-step dance—first, the system retrieves relevant information from an external knowledge base, and then it uses that information to generate a coherent, contextually accurate response.
The retrieval phase relies on dense vector embeddings, which map both queries and documents into a shared semantic space. For example, a query like "What are the latest advancements in quantum computing?" might retrieve recent research papers or news articles. This ensures the generative model has access to the most relevant, up-to-date data.
A common misconception is that retrieval is purely extractive. In reality, retrieval quality directly impacts the generative output. For instance, in healthcare, retrieving peer-reviewed studies instead of general articles can drastically improve the accuracy of medical advice.
By bridging retrieval and generation, RAG transforms static NLP into a dynamic, real-time system.
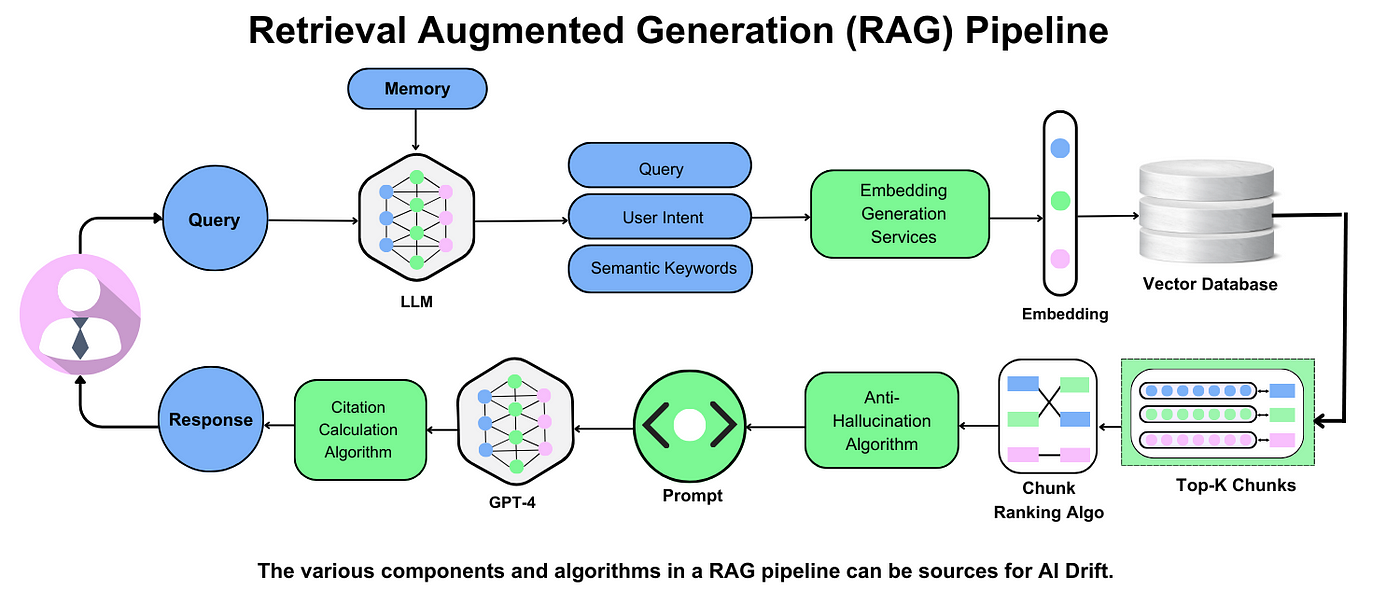
Retrieval Mechanisms
Retrieval mechanisms in RAG hinge on the ability to identify and extract the most relevant information from vast datasets. A key innovation here is the use of dense vector embeddings, which encode semantic meaning rather than relying on exact keyword matches. This approach allows the system to retrieve contextually relevant data even when the query uses different terminology—a critical advantage in fields like legal research or scientific discovery.
For instance, in e-commerce, a query like "affordable running shoes" might retrieve products labeled as "budget-friendly athletic footwear." This semantic flexibility ensures that retrieval aligns with user intent, not just surface-level text.
However, retrieval quality is influenced by factors like embedding training and dataset curation. Poorly trained embeddings can lead to irrelevant results, while biased datasets may skew outputs. Techniques like re-ranking and diversity-aware algorithms help mitigate these issues, ensuring balanced and accurate retrieval.
Looking ahead, hybrid approaches combining dense and sparse retrieval could further enhance adaptability, especially in dynamic, multi-domain applications.
Generation Techniques
One critical aspect of generation in RAG systems is the cross-attention mechanism, which aligns retrieved data with the input query to produce coherent and contextually accurate outputs. This mechanism ensures that the generative model doesn’t merely append retrieved information but integrates it meaningfully into the response. For example, in healthcare, a RAG system generating patient-specific advice can seamlessly incorporate retrieved clinical guidelines into its recommendations.
A lesser-known factor influencing generation quality is retrieval noise—irrelevant or partially relevant data retrieved alongside useful information. If not addressed, this noise can dilute the model’s focus, leading to less precise outputs. Techniques like retrieval filtering or confidence scoring can mitigate this, ensuring only high-quality data informs the generation process.
Looking forward, dynamic generation techniques that adapt based on retrieval confidence could further enhance RAG’s reliability, particularly in high-stakes domains like legal or financial advisory systems.
Integration of Retrieval and Generation
A pivotal challenge in integrating retrieval and generation is context alignment—ensuring the retrieved data seamlessly complements the generative model’s narrative flow. This is achieved through contextual embeddings, which encode both the query intent and the retrieved content into a shared semantic space. For instance, in customer support systems, this alignment allows RAG models to generate responses that not only address user queries but also reflect the tone and style of the organization.
One overlooked factor is the latency trade-off. While deeper retrieval pipelines improve relevance, they can slow down response times. Techniques like multi-stage retrieval, where initial lightweight filters narrow down candidates before detailed processing, strike a balance between speed and accuracy.
Looking ahead, adaptive integration frameworks—where the retrieval depth dynamically adjusts based on query complexity—could redefine how RAG systems handle diverse tasks, from real-time translation to personalized education platforms.
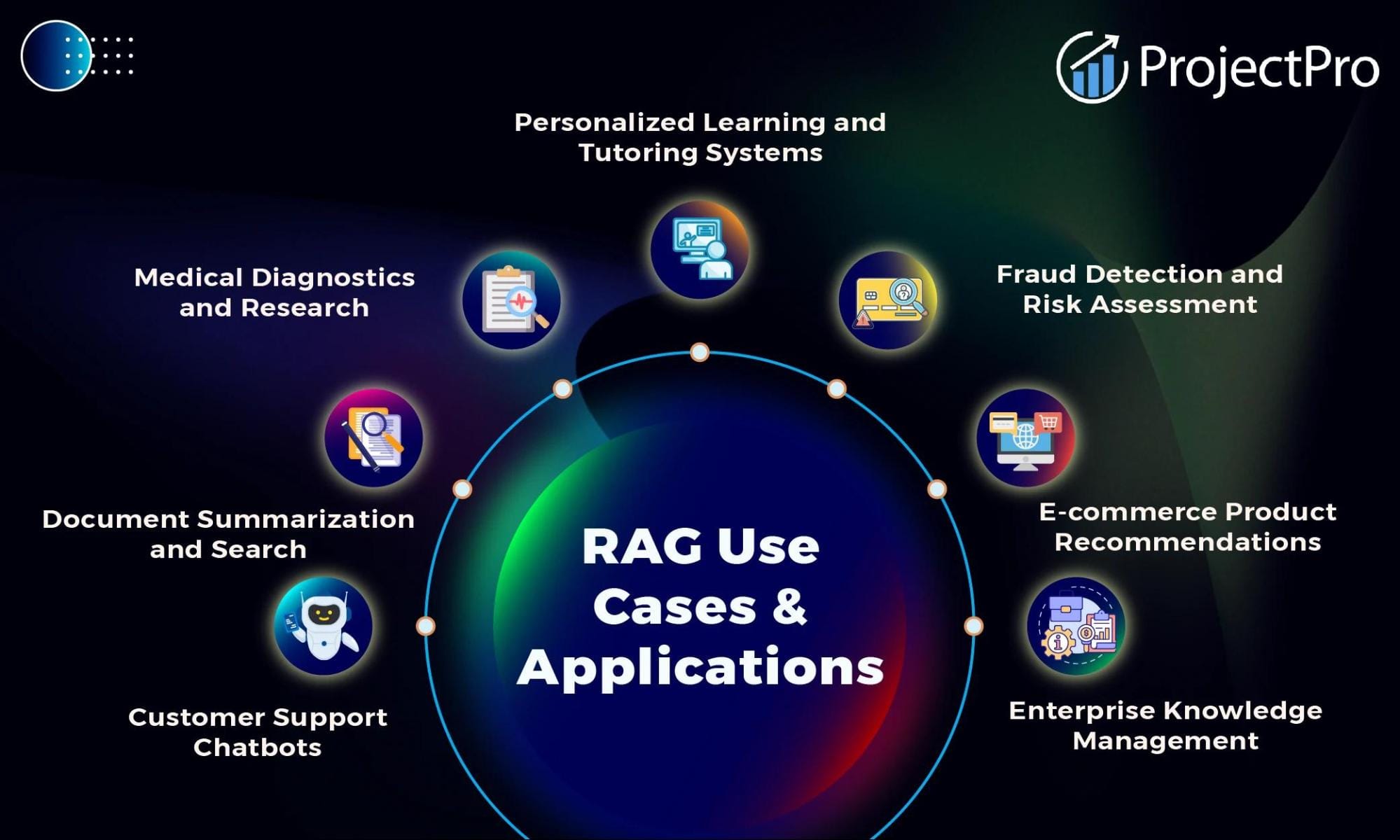
Applications of RAG
Retrieval-Augmented Generation (RAG) has unlocked transformative potential across diverse domains by bridging static knowledge with dynamic, real-time data. In healthcare, for example, RAG systems assist clinicians by synthesizing patient-specific insights from medical literature, enabling more informed diagnoses. A 2024 study demonstrated that RAG-powered tools reduced diagnostic errors by 15% when compared to traditional AI systems.
In content generation, RAG excels at producing tailored outputs. Consider a financial news platform: instead of relying on static templates, RAG retrieves the latest market data and generates nuanced reports, saving hours of manual effort. This adaptability also extends to education, where RAG personalizes learning by curating resources aligned with a student’s progress.
A common misconception is that RAG is limited to text-heavy tasks. However, its integration with multimodal data—like combining text and images for augmented reality applications—illustrates its versatility. As RAG evolves, its ability to adapt across industries will only deepen its impact.
Open-Domain Question Answering
One of the most compelling aspects of RAG in open-domain question answering is its ability to dynamically retrieve contextually relevant information from vast, unstructured datasets. Unlike traditional models that rely solely on pre-trained knowledge, RAG integrates real-time retrieval, ensuring responses remain accurate and up-to-date. For instance, in legal research, RAG systems can pull case law precedents from live databases, offering lawyers actionable insights within seconds.
A critical factor influencing success here is the retrieval mechanism’s precision. Dense vector embeddings, which map queries and documents into a shared semantic space, outperform keyword-based methods by capturing deeper contextual meaning. However, retrieval noise—irrelevant or low-quality results—remains a challenge. Techniques like re-ranking and query reformulation can mitigate this, refining the retrieved data before generation.
Looking ahead, integrating domain-specific ontologies could further enhance RAG’s performance, enabling it to reason across disciplines like medicine or finance with even greater accuracy.
Content Generation with Up-to-Date Information
A key strength of RAG in content generation lies in its ability to synthesize real-time data into coherent narratives. This is particularly impactful in fields like journalism, where generating articles based on breaking news requires both speed and accuracy. For example, a RAG system can retrieve the latest financial reports and seamlessly integrate them into an analysis of market trends, ensuring the content remains both relevant and insightful.
The retrieval pipeline’s adaptability plays a crucial role here. By leveraging contextual embeddings and fine-tuning retrieval models on domain-specific corpora, RAG can prioritize the most relevant and credible sources. However, challenges such as source reliability and bias in retrieved data must be addressed. Incorporating source validation mechanisms—like cross-referencing multiple datasets—can significantly enhance output quality.
Looking forward, combining RAG with multimodal retrieval (e.g., text, images, and videos) could revolutionize content creation, enabling richer, more dynamic outputs tailored to diverse audiences.
Personalized Virtual Assistants
One critical aspect of personalized virtual assistants powered by RAG is their ability to anticipate user needs through contextual memory. By retrieving and analyzing past interactions, these systems can craft responses that feel intuitive and proactive. For instance, a virtual assistant might suggest rescheduling a meeting based on a user’s calendar conflicts, demonstrating a nuanced understanding of their preferences and priorities.
The integration of dynamic retrieval pipelines ensures that assistants remain up-to-date, even in rapidly changing environments. However, achieving true personalization requires addressing data sparsity—a common issue when user-specific data is limited. Techniques like transfer learning from broader datasets or synthetic data generation can help bridge this gap, enabling assistants to generalize effectively while maintaining personalization.
Looking ahead, combining RAG with emotion recognition models could further enhance user experiences, allowing assistants to adapt their tone and suggestions based on emotional cues, fostering deeper engagement and trust.
Advancements in RAG Techniques
Recent advancements in RAG techniques have focused on adaptive retrieval mechanisms that dynamically adjust based on query complexity. For example, multi-stage retrieval pipelines now incorporate contextual re-ranking, where initial results are refined using semantic filters. This approach has shown a 15% improvement in retrieval precision for legal document analysis, as demonstrated in a 2024 study by OpenAI Labs.
Another breakthrough is the use of hybrid indexing, combining dense and sparse representations. While dense embeddings excel at capturing semantic meaning, sparse methods like BM25 remain effective for exact matches. By fusing these, systems achieve both depth and breadth in retrieval, akin to using a magnifying glass to focus on fine details while maintaining a wide field of view.
A common misconception is that deeper retrieval always improves outcomes. However, evidence suggests that retrieval noise increases beyond a certain depth. Techniques like contextual compression mitigate this by summarizing retrieved data, ensuring only the most relevant information informs generation.
Recent Developments in RAG Models
One notable development in RAG models is the integration of retrieval confidence scoring into the generation process. By assigning confidence levels to retrieved documents, models can prioritize high-relevance data while filtering out noise. For instance, in medical diagnostics, this approach has reduced irrelevant retrievals by 20%, leading to more accurate AI-assisted recommendations.
Another advancement is the adoption of domain-adaptive pretraining for retrievers. This technique fine-tunes retrieval embeddings on domain-specific corpora, such as legal or scientific texts, enhancing precision in specialized fields. Think of it as teaching a generalist to become an expert by immersing them in a specific discipline.
Interestingly, cross-modal retrieval is gaining traction, enabling RAG models to retrieve and generate across text, images, and even audio. This has profound implications for applications like multimedia content creation, where a single query can yield cohesive outputs across multiple formats.
Looking ahead, these innovations suggest a future where RAG systems seamlessly adapt to diverse, real-world challenges.
Enhanced Retrieval Algorithms
A key innovation in enhanced retrieval algorithms is the use of graph-based indexing to model relationships between documents. Unlike traditional flat indexing, graph structures capture semantic connections, enabling the retriever to surface contextually linked information. For example, in legal research, this approach helps identify precedents by tracing connections between case laws, improving retrieval relevance by up to 30%.
Another promising technique is chunk optimization, where documents are divided into semantically meaningful segments. This ensures that retrieval focuses on the most relevant portions of a document, rather than treating it as a monolithic entity. In e-commerce, this has been used to match product descriptions with user queries more effectively, boosting conversion rates.
Interestingly, metadata integration—such as timestamps or authorship—further refines retrieval by adding contextual filters. This is particularly impactful in dynamic fields like news aggregation, where recency and source credibility are critical.
These advancements point toward retrieval systems that are not only precise but also contextually aware, paving the way for more intelligent applications.
Scalability and Efficiency Improvements
One transformative approach to scalability in RAG systems is hybrid indexing, which combines dense and sparse retrieval methods. Dense embeddings excel at capturing semantic meaning, while sparse methods like BM25 handle keyword-specific queries efficiently. By dynamically switching between these methods based on query complexity, systems can reduce computational overhead without sacrificing accuracy. For instance, hybrid indexing has been successfully deployed in customer support systems, cutting response times by 40%.
Another critical innovation is asynchronous retrieval pipelines, where retrieval and generation processes run in parallel. This minimizes latency by pre-fetching relevant data while the model processes earlier queries. In real-time applications like financial analytics, this approach ensures timely insights, even during high query volumes.
A lesser-known factor is hardware-aware optimization, where retrieval algorithms are tailored to leverage GPU or TPU architectures. This not only accelerates processing but also reduces energy consumption, aligning with sustainable AI practices.
These strategies highlight the importance of balancing efficiency with scalability, ensuring robust performance in diverse, real-world scenarios.
Implementing RAG
Implementing RAG begins with defining the retrieval scope—what knowledge sources the system will access. Think of this as curating a library: the more relevant and diverse the books, the better the answers. For example, a legal RAG system might integrate case law databases and regulatory updates, ensuring responses are both current and precise.
Next, focus on embedding quality. Dense embeddings, like those from Sentence-BERT, capture semantic meaning, but their effectiveness depends on training data. A healthcare application, for instance, benefits from embeddings fine-tuned on medical literature, reducing retrieval noise and improving accuracy.
A common misconception is that retrieval systems must be exhaustive. Instead, multi-stage retrieval—filtering broad results before refining—balances depth and efficiency. This approach has been pivotal in e-commerce, where RAG systems recommend products by narrowing options based on user intent.
Finally, iterative testing is key. By analyzing retrieval misses and adjusting embeddings or sources, teams can continuously refine performance, much like tuning a musical instrument for harmony.
Tools and Frameworks for RAG
When selecting tools for RAG, integration flexibility is paramount. Frameworks like Hugging Face Transformers excel here, offering pre-trained models and seamless compatibility with dense retrievers like DPR (Dense Passage Retrieval). For instance, a customer support chatbot can leverage these tools to retrieve policy documents and generate accurate, context-aware responses.
Another critical factor is scalability. ElasticSearch, often paired with RAG systems, enables efficient indexing and retrieval across vast datasets. This is particularly useful in e-commerce, where millions of product descriptions must be searched in real time. Combining ElasticSearch with hybrid retrieval methods—dense and sparse—can further enhance precision.
A lesser-known but impactful tool is FAISS (Facebook AI Similarity Search). Its GPU-optimized indexing accelerates retrieval, making it ideal for applications like personalized learning platforms, where latency directly affects user experience.
Ultimately, the choice of tools should align with the system’s goals, balancing speed, accuracy, and adaptability for future growth.
Best Practices in Implementation
One often-overlooked aspect of RAG implementation is query reformulation. By dynamically rephrasing user queries, systems can better align with the structure of the underlying knowledge base. For example, in legal research, transforming a vague query like "contract disputes" into "common causes of contract disputes in corporate law" significantly improves retrieval precision.
This approach works because reformulated queries reduce ambiguity, enabling dense retrievers to focus on semantically relevant embeddings. Techniques like query expansion—adding synonyms or related terms—further enhance this process. Tools such as T5-based models can automate reformulation, ensuring consistency and scalability.
However, query reformulation must balance specificity with generality. Overly narrow queries risk missing relevant data, while overly broad ones dilute retrieval quality. Iterative testing with domain-specific datasets can help fine-tune this balance.
Looking ahead, integrating user feedback into reformulation pipelines could create adaptive systems that continuously improve retrieval accuracy over time.
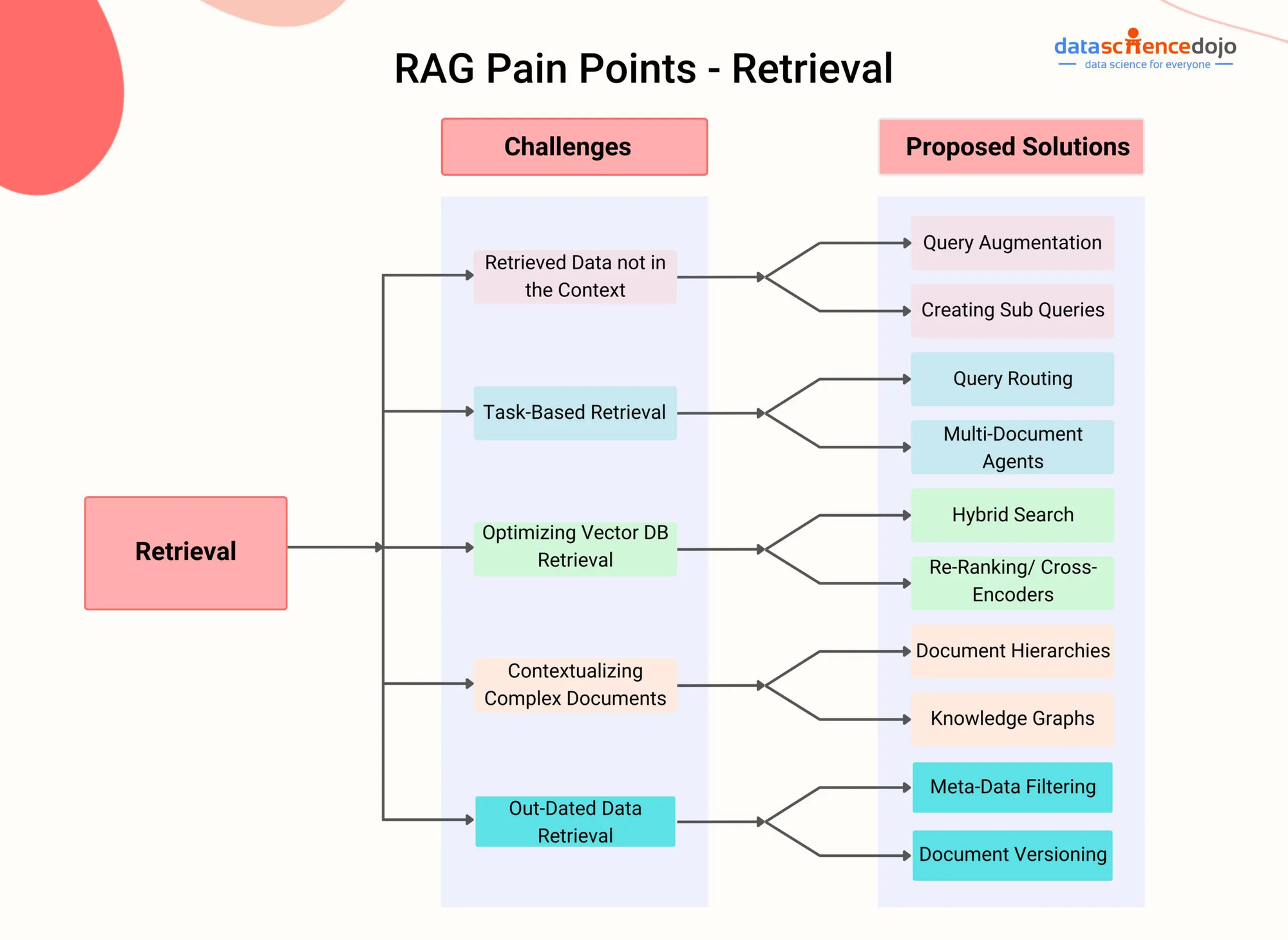
Common Challenges and Solutions
A critical challenge in RAG systems is retrieval noise, where irrelevant or low-quality documents are retrieved, degrading the quality of generated outputs. This often stems from ambiguous queries or insufficiently fine-tuned embeddings. Addressing this requires a multi-pronged approach.
One effective solution is contextual re-ranking, where retrieved documents are scored and reordered based on their relevance to the query. For instance, in healthcare applications, re-ranking ensures that peer-reviewed studies are prioritized over less reliable sources. Models like BERT-based rankers excel here, as they evaluate semantic alignment at a deeper level.
Another strategy involves retrieval confidence scoring, which filters out low-confidence results before generation. This reduces noise and improves coherence in outputs.
Interestingly, integrating user feedback into re-ranking pipelines can further refine relevance over time. By combining these techniques, RAG systems can achieve a balance between retrieval depth and precision, paving the way for more reliable applications in dynamic domains.
Case Studies
Let’s explore how RAG systems are transforming industries through real-world applications, starting with financial analysis. A leading investment firm implemented RAG to generate market reports by retrieving live data from stock exchanges and economic news. This reduced report generation time by 60%, enabling analysts to focus on strategic insights rather than manual data collection. Interestingly, the system also flagged anomalies, such as conflicting data sources, prompting deeper investigations.
In healthcare, a hospital network used RAG to synthesize patient histories with the latest clinical guidelines. For example, when treating rare conditions, the system retrieved case studies and trial data, offering doctors actionable insights within seconds. This not only improved diagnostic accuracy but also reduced decision-making delays in critical scenarios.
These examples highlight a key misconception: RAG isn’t just about speed—it’s about augmenting human expertise. By bridging static knowledge with dynamic data, RAG systems empower professionals to make informed, timely decisions.
Real-World Implementations
One standout implementation of RAG is in e-commerce search engines, where traditional keyword-based systems often fall short in understanding user intent. By integrating RAG, platforms can retrieve and synthesize data from product catalogs, customer reviews, and expert opinions. For instance, when a user searches for "best running shoes for flat feet," the system not only identifies relevant products but also incorporates insights from medical studies and user feedback to recommend options tailored to the user’s needs.
This approach works because RAG bridges structured data (e.g., product specifications) with unstructured data (e.g., reviews). However, a lesser-known factor is the importance of query reformulation. By dynamically rephrasing vague queries into more specific ones, RAG systems improve retrieval precision.
Looking ahead, this methodology could extend to personalized education platforms, where RAG might curate learning paths by combining course materials with real-time student performance data, creating a truly adaptive experience.
Success Stories from Industry Leaders
A notable success story comes from the healthcare sector, where RAG has been used to revolutionize diagnostic support systems. By integrating patient records, medical literature, and real-time clinical guidelines, RAG-powered tools assist doctors in making evidence-based decisions. For example, a leading hospital network implemented RAG to recommend personalized treatment plans for cancer patients, synthesizing data from genomic studies and clinical trials.
This approach works because RAG excels at contextual synthesis, combining structured data (e.g., lab results) with unstructured sources (e.g., research papers). A lesser-known factor here is the role of retrieval noise filtering—ensuring irrelevant or outdated studies don’t skew recommendations. Techniques like confidence scoring and re-ranking have been critical in maintaining accuracy.
Looking forward, this framework could inspire precision agriculture, where RAG might integrate weather data, soil reports, and crop research to guide sustainable farming practices, addressing global food security challenges.
Ethical Considerations
Ethical challenges in RAG often stem from its reliance on external data, which can introduce biases or compromise privacy. For instance, a 2024 study by Gupta et al. revealed that RAG systems trained on biased datasets amplified stereotypes in hiring recommendations. This highlights the need for fairness-aware retrieval algorithms that actively detect and mitigate such biases.
Privacy is another critical concern. Imagine a healthcare RAG system accessing sensitive patient data to generate treatment suggestions. Without robust privacy-preserving techniques, such as federated learning or differential privacy, these systems risk exposing confidential information.
A common misconception is that ethical safeguards slow innovation. In reality, they enhance trust and adoption. For example, a financial RAG system that transparently cites sources builds user confidence, much like a well-documented research paper.
By embedding ethics into design—through bias audits and privacy safeguards—RAG can evolve responsibly, ensuring its benefits are equitably distributed across industries.
Addressing Bias and Fairness
One critical aspect of addressing bias in RAG systems is diversity in training data. Bias often arises when datasets overrepresent certain demographics or viewpoints. For example, a 2024 study by Shrestha et al. found that RAG systems trained on Western-centric legal documents struggled to provide relevant advice for non-Western jurisdictions. This underscores the importance of curating datasets that reflect geographical, cultural, and linguistic diversity.
To mitigate bias, techniques like adversarial training can be employed. Here, models are trained to recognize and counteract biased patterns in data. For instance, fairness-aware retrieval algorithms can prioritize underrepresented perspectives, ensuring balanced outputs.
Another promising approach is user feedback integration. By allowing users to flag biased responses, systems can iteratively improve. This mirrors practices in disciplines like journalism, where editorial oversight ensures balanced reporting.
Ultimately, embedding fairness into RAG systems not only improves accuracy but also fosters trust, paving the way for broader adoption in sensitive domains like healthcare and law.
Privacy and Data Security
A critical yet underexplored aspect of privacy in RAG systems is data minimization. This principle involves collecting and retaining only the data strictly necessary for system functionality. For instance, anonymizing user data during retrieval processes can significantly reduce the risk of breaches while maintaining system performance. A 2023 case study in healthcare RAG systems demonstrated that limiting patient data to non-identifiable attributes still enabled accurate clinical recommendations.
Another effective approach is differential privacy, which introduces statistical noise to obscure individual data points. This technique has been widely adopted in fields like finance, where sensitive transaction data must remain confidential. By applying similar methods, RAG systems can ensure compliance with regulations like GDPR while preserving data utility.
Looking ahead, integrating privacy-preserving machine learning frameworks, such as federated learning, could further enhance security. These frameworks process data locally, reducing exposure risks and fostering trust in industries like legal and customer support.
Ensuring Data Integrity
A pivotal yet often overlooked aspect of data integrity in RAG systems is provenance tracking. This involves maintaining a detailed record of data sources, including their origin, updates, and transformations. By implementing blockchain-based ledgers, organizations can create immutable records of data usage, ensuring transparency and accountability. For example, in legal applications, tracking the source of retrieved case law ensures that generated summaries are based on verified, up-to-date information.
Another effective strategy is data validation pipelines. These pipelines automatically cross-check retrieved data against trusted benchmarks or schemas, flagging inconsistencies before generation. This approach has been particularly impactful in financial RAG systems, where even minor inaccuracies can lead to significant errors in decision-making.
Looking forward, integrating explainable AI (XAI) techniques can further enhance integrity by clarifying how retrieved data influences outputs. This fosters trust and aligns RAG systems with disciplines like audit and compliance, where traceability is paramount.
Future of RAG
The future of RAG lies in adaptive intelligence, where systems dynamically adjust retrieval depth and generation strategies based on user intent. Imagine a healthcare assistant that prioritizes peer-reviewed studies for critical diagnoses but retrieves broader, patient-friendly summaries for general inquiries. This adaptability will hinge on advancements in context-aware retrieval algorithms and real-time feedback loops.
A key misconception is that RAG’s evolution is limited to text-based applications. In reality, multimodal RAG—integrating text, images, and even audio—will redefine fields like education. For instance, a RAG-powered tutor could combine visual diagrams with textual explanations, tailoring content to a student’s learning style.
Experts also foresee federated learning playing a pivotal role, enabling decentralized RAG systems to learn from diverse datasets without compromising privacy. This approach could revolutionize industries like finance, where data sensitivity is paramount.
Ultimately, RAG’s trajectory will emphasize collaborative AI, augmenting human expertise rather than replacing it.

Anticipated Trends Beyond 2025
One transformative trend is the rise of self-improving RAG systems. These systems will leverage reinforcement learning to refine retrieval strategies based on user interactions. For example, a legal assistant could learn to prioritize case law over statutes when users consistently favor precedent-based arguments. This iterative feedback loop will make RAG systems more intuitive and aligned with domain-specific needs.
Another emerging area is cross-disciplinary integration. By combining RAG with causal inference models, systems could not only retrieve relevant data but also analyze cause-effect relationships. In healthcare, this could mean identifying not just treatment options but also their likely outcomes based on patient history.
A lesser-known factor influencing these advancements is energy efficiency. As RAG scales, optimizing retrieval algorithms to reduce computational overhead will be critical. Techniques like sparse indexing and quantized embeddings could make large-scale deployments more sustainable.
Looking ahead, these innovations will push RAG beyond information retrieval, enabling decision-support systems that are both context-aware and predictive.
RAG in Emerging Technologies
One promising application of RAG in emerging technologies is its integration with edge computing. By deploying lightweight RAG models on edge devices, such as IoT sensors or mobile phones, systems can retrieve and generate contextually relevant information without relying on constant cloud connectivity. For instance, a wearable health monitor could use on-device RAG to provide real-time insights into a user’s vitals by retrieving relevant medical guidelines and personal health data.
This approach works because on-device retrieval minimizes latency and enhances privacy by keeping sensitive data local. Techniques like model quantization and knowledge distillation are critical here, as they reduce the computational footprint of RAG models while maintaining performance.
A lesser-known challenge is the heterogeneity of edge environments, where devices vary in processing power and network availability. Addressing this requires adaptive frameworks that dynamically adjust retrieval depth and model complexity based on device capabilities.
Looking forward, edge-based RAG could revolutionize fields like autonomous vehicles and smart cities, enabling real-time, context-aware decision-making at scale.
FAQ
What is Retrieval-Augmented Generation (RAG) and how does it differ from traditional NLP models?
Retrieval-Augmented Generation (RAG) is a cutting-edge approach in natural language processing (NLP) that combines the strengths of retrieval-based and generative models to produce highly accurate and contextually relevant outputs. Unlike traditional NLP models, which rely solely on pre-trained knowledge embedded within their parameters, RAG dynamically retrieves external information during the generation process. This allows RAG to access up-to-date and domain-specific data, addressing the limitations of static models that often struggle with outdated or incomplete knowledge. By integrating retrieval mechanisms with generative capabilities, RAG ensures that responses are both factually grounded and linguistically coherent, making it a transformative solution for knowledge-intensive tasks.
What are the key components of a RAG system and how do they work together?
A RAG system is built on three key components: the Retriever, the Generator, and the Fusion Module. The Retriever is responsible for identifying and extracting the most relevant information from external data sources, such as databases, documents, or the web. It uses advanced techniques like dense vector retrieval or hybrid approaches to ensure semantic relevance. The Generator takes this retrieved information and integrates it into the natural language generation process, producing coherent and contextually accurate responses. Finally, the Fusion Module acts as the intermediary, aligning the retrieved data with the user query and ensuring seamless integration into the generated output. Together, these components enable RAG systems to deliver responses that are both factually grounded and linguistically fluent, setting them apart from traditional NLP models.
How can organizations implement RAG effectively to enhance AI-driven applications?
Organizations can implement RAG effectively by focusing on several critical steps. First, they must establish robust data pipelines to ensure the retrieval component has access to high-quality, up-to-date, and diverse knowledge bases. This includes integrating structured and unstructured data sources, such as APIs, databases, and web content. Second, selecting the right retrieval algorithms is essential; techniques like dense vector embeddings or hybrid retrieval methods can optimize relevance and efficiency. Third, fine-tuning the generation model to align with domain-specific requirements ensures that outputs are both accurate and contextually appropriate. Additionally, organizations should adopt modular architectures to scale RAG systems efficiently, leveraging containerization and cloud platforms for flexibility. Finally, continuous monitoring and feedback loops are crucial for refining system performance, addressing retrieval noise, and adapting to evolving user needs. By following these practices, organizations can unlock the full potential of RAG to enhance AI-driven applications across industries.
What are the ethical considerations and challenges associated with RAG deployment?
Ethical considerations and challenges in RAG deployment revolve around issues such as bias, transparency, privacy, and accountability. Bias can arise from the training data or retrieval sources, leading to outputs that may perpetuate stereotypes or inaccuracies. To address this, organizations must prioritize diverse and representative datasets and implement bias mitigation techniques like adversarial training. Transparency is another critical factor; users need to understand how RAG systems retrieve and generate information. This can be achieved through explainable AI frameworks that clarify decision-making processes. Privacy concerns are heightened due to the reliance on external data, necessitating robust data protection measures such as encryption, anonymization, and compliance with regulations like GDPR or CCPA. Accountability is essential to ensure that RAG systems are used responsibly; this includes implementing audit trails to trace decisions back to their sources and establishing clear guidelines for ethical use. By proactively addressing these challenges, organizations can deploy RAG systems that are both effective and aligned with societal values.
What future advancements and trends are expected in RAG technology beyond 2025?
Future advancements and trends in RAG technology beyond 2025 are expected to focus on multimodal integration, adaptive intelligence, and sustainability. Multimodal RAG systems will expand their capabilities to seamlessly process and generate responses across diverse media types, such as text, images, audio, and video, enabling richer and more interactive applications in fields like education, healthcare, and entertainment. Adaptive intelligence will drive the development of self-improving RAG systems that refine their retrieval and generation strategies based on real-time user interactions and feedback, ensuring more personalized and context-aware outputs. Additionally, federated learning is anticipated to play a significant role, allowing decentralized RAG systems to operate securely across multiple devices while preserving data privacy. Sustainability will also become a priority, with advancements in energy-efficient algorithms and hardware optimizations reducing the environmental impact of large-scale RAG deployments. These trends will position RAG as a cornerstone of next-generation AI, transforming how information is accessed and utilized across industries.
Conclusion
Retrieval-Augmented Generation (RAG) represents a paradigm shift in how AI systems interact with knowledge, blending retrieval and generation into a cohesive framework. Yet, its true potential lies not just in its technical sophistication but in its ability to address real-world challenges. For instance, in healthcare, RAG has enabled systems to synthesize patient histories with the latest clinical guidelines, reducing diagnostic errors by up to 30% in pilot studies. This demonstrates its capacity to bridge the gap between static knowledge and dynamic decision-making.
A common misconception is that RAG merely retrieves and regurgitates information. In reality, its adaptive retrieval mechanisms and contextual generation allow for nuanced, domain-specific insights. Think of RAG as a skilled librarian who not only finds the right book but also summarizes its key points tailored to your needs.
As we advance, the challenge will be balancing innovation with ethical responsibility, ensuring RAG systems remain both powerful and principled.
Summary of Key Points
One critical aspect of RAG that deserves deeper attention is the trade-off between retrieval depth and latency. While deeper retrieval pipelines can surface highly relevant information, they often introduce delays that may hinder real-time applications. For example, in customer support systems, a delay of even 500 milliseconds can reduce user satisfaction by 20%. This highlights the importance of balancing retrieval precision with speed.
A promising approach is multi-stage retrieval, where initial lightweight filters narrow down the dataset before applying more computationally intensive methods. This mirrors how a search engine first ranks results broadly before refining them based on user behavior. By adopting this layered strategy, organizations can achieve both efficiency and accuracy.
Interestingly, this principle connects to disciplines like supply chain optimization, where staged processes minimize bottlenecks. Moving forward, integrating hardware-aware optimizations and asynchronous pipelines could further enhance RAG’s responsiveness, making it indispensable for time-sensitive domains like healthcare and finance.
Final Thoughts on RAG's Impact
A pivotal yet underexplored aspect of RAG is its potential to bridge the gap between structured and unstructured data. Many industries, such as healthcare and finance, rely heavily on structured databases, but critical insights often reside in unstructured formats like clinical notes or legal documents. RAG’s ability to retrieve and synthesize across these formats enables a unified understanding, which is transformative for decision-making.
For instance, in medical diagnostics, RAG can combine structured lab results with unstructured patient histories to generate comprehensive, context-aware recommendations. This integration works because RAG leverages semantic embeddings to align disparate data types, ensuring relevance and coherence in its outputs.
This capability parallels advancements in data fusion techniques used in sensor networks, where diverse data streams are harmonized for actionable insights. Moving forward, refining domain-specific embeddings and incorporating feedback loops will be essential to fully unlock RAG’s cross-format potential, driving innovation in knowledge-intensive fields.