
Scaling RAG Systems to 20 Million Documents: Challenges and Solutions
Scaling RAG systems to 20 million documents presents challenges in retrieval speed, storage, and efficiency. This guide explores key obstacles and practical solutions to enhance performance, maintain accuracy, and optimize large-scale AI retrieval.


Scaling Retrieval-Augmented Generation (RAG) systems beyond a few million documents is not just a storage problem—it’s an architectural challenge.
As datasets grow into the tens of millions, retrieval speeds slow, query accuracy declines, and infrastructure complexity escalates.
RAG systems risk becoming unusable at scale without efficient indexing, sharding, and data management strategies.
Therefore, organizations scaling RAG systems must optimize retrieval processes, data locality, and query efficiency to maintain performance.
This article explores the core challenges and best practices for scaling RAG systems to 20 million documents, ensuring speed and accuracy in high-demand environments.
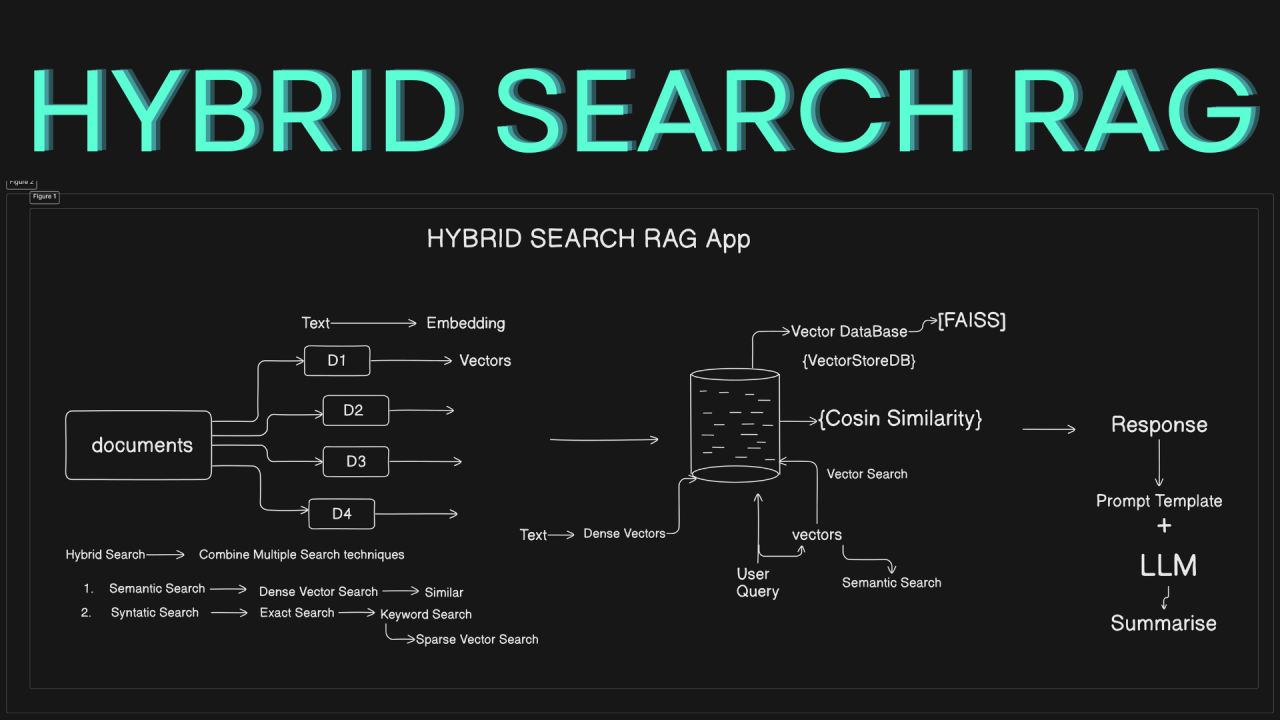
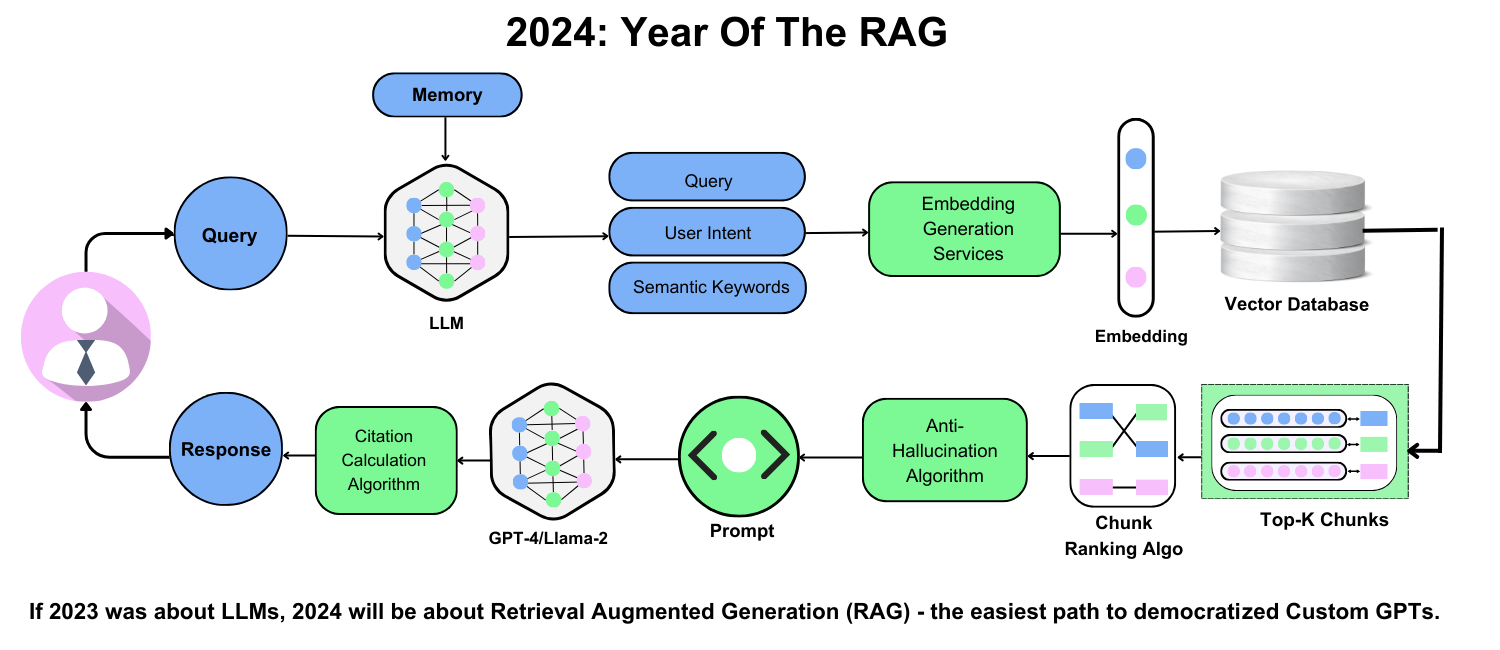
Understanding Retrieval-Augmented Generation
Scaling RAG systems to handle 20 million documents isn’t just a technical challenge—it’s a balancing act.
One overlooked factor is retrieval granularity. Most systems retrieve entire documents, but this approach often floods the generative model with irrelevant data. Instead, passage-level retrieval is emerging as a game-changer.
It works because smaller, context-rich inputs reduce noise, allowing the generative model to craft more coherent outputs.
But there’s a catch—this requires advanced indexing techniques, like dense vector embeddings, to pinpoint the right passages. Without these, retrieval precision can drop up to 30% in noisy datasets.
Now, let’s connect the dots. This isn’t just about better search; it’s about trust. In fields like healthcare, where RAG systems assist in diagnostics, irrelevant data is inefficient and dangerous. Organizations can refine retrieval models in real time by integrating feedback loops and anomaly detection tools.
Infrastructure Scaling for RAG Systems
Scaling infrastructure for RAG systems isn’t just about adding more servers—it’s about building more intelligent systems.
Think of it as upgrading from a single-lane road to a multi-lane highway. Distributed architectures, like those used by Spotify, allow data to flow seamlessly by splitting workloads across multiple nodes. This approach improves speed and ensures the system can handle traffic spikes without sweat.
But here’s the catch: not all distributed systems are created equal. Poorly designed setups can introduce cross-node latency, where queries bounce between nodes, slowing everything down.
Netflix tackled this by implementing query parallelization, reducing retrieval times to under a second, even with millions of documents in play.
Another overlooked factor is data locality. Companies like Google achieve this with advanced caching strategies, ensuring hot data is always within reach.
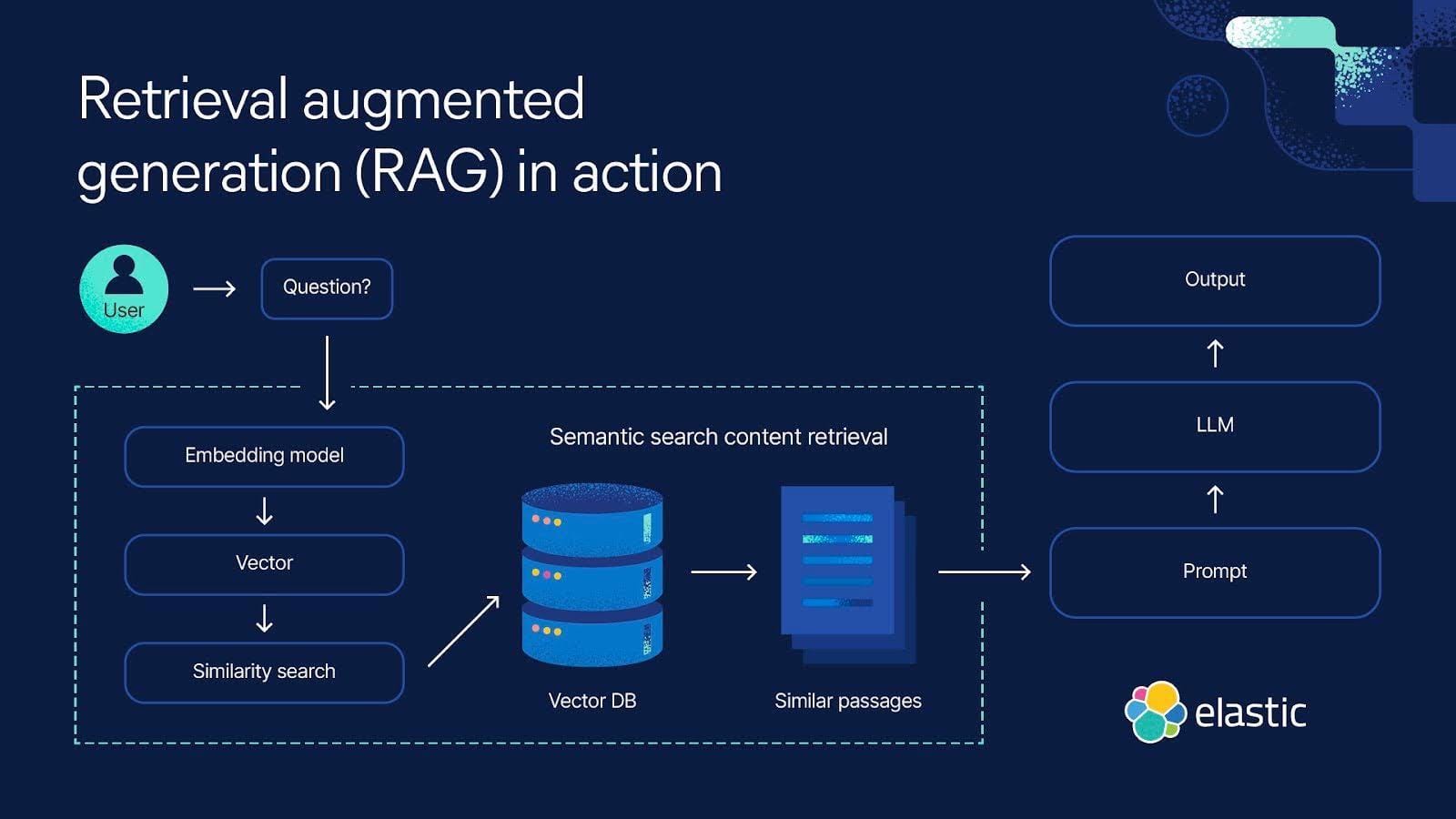
Choosing the Right Vector Database
Picking the proper vector database for RAG systems is like choosing the engine for a race car—it defines your speed, efficiency, and reliability.
For datasets exceeding 10 million documents, Pinecone, Weaviate, and PGVector stand out because they support distributed indexing and querying.
However, not all databases handle scaling equally well.
Take sharding, for example. Sharding is a popular strategy for splitting data across nodes, but poorly implemented sharding can create cross-node latency. Pinecone mitigates this using hierarchical graph indexing, which clusters similar data points and reduces traversal time.
Meanwhile, Weaviate’s hybrid search capabilities combine dense and sparse retrieval, making it ideal for noisy datasets where precision is critical.
Your vector database isn’t just a storage solution—it’s the backbone of your RAG system. Choose one that aligns with your scaling needs and saves you headaches.
Implementing Distributed Systems
Implementing distributed systems in RAG applications involves more than just spreading data across multiple nodes. It requires a structured approach to minimize latency and prevent performance bottlenecks.
One of the biggest challenges is data locality, which determines how efficiently data can be retrieved when needed.
Keeping frequently accessed data close to the processing nodes significantly reduces latency.
However, anonymously distributing data across multiple nodes can backfire. Cross-node queries—where data needs to be fetched from different locations—introduce unnecessary delays.
Distributed systems must also be modular to ensure scalable performance. Technologies like Apache Kafka and Kubernetes help separate different workloads—such as ingestion, indexing, and querying—so that each component can scale independently.
This targeted approach prevents system overload and optimizes resource allocation based on real-time demand.
Ultimately, distributed systems should not just distribute workload—they should do so intelligently. Proper planning in data locality, query execution, and fault tolerance ensures that RAG systems remain efficient and scalable, even when dealing with massive document collections.
Optimizing Retrieval Processes
Let’s face it—retrieval isn’t just about speed; it’s about precision. Flooding a generative model with irrelevant data is like trying to find a needle in a haystack while someone keeps adding more hay.
But here’s the kicker: precision doesn’t come free.
Dense vector embeddings, while powerful, can struggle with noisy datasets.
A hybrid approach—combining dense and sparse retrieval—has proven effective in cutting through the noise. For instance, Weaviate’s hybrid search capabilities excel in balancing relevance and speed, especially in messy datasets.
But host people miss: the point that retrieval isn’t static. Feedback loops can refine results in real-time, turning user interactions into optimization gold. In healthcare, for example, anomaly detection tools ensure irrelevant or dangerous data doesn’t slip through.
Techniques for Efficient Query Optimization
Let’s talk about query transformation.
It’s like rephrasing a tricky question to get a better answer. By rewriting queries to align with how data is stored, systems like Google’s BERT have improved retrieval accuracy by up to 25%.
For example, transforming “What’s the weather in Paris?” into “Paris weather forecast” reduces ambiguity and speeds up retrieval.
But here’s the twist: not all queries need the same treatment.
Enter query routing. Think of it as a traffic cop for your RAG system, directing each query to the most relevant pipeline. Spotify uses this to separate music recommendations from podcast searches, ensuring faster, more accurate results. The key? Training the router on diverse query types to avoid misclassification.
Now, let’s get technical. Dynamic query construction adjusts parameters like keyword weight or semantic focus based on context. This is a game-changer in domains like legal tech, where precision is non-negotiable. Tools like PGVector leverage this to balance broad searches with pinpoint accuracy.
Hybrid Indexing Approaches
Let’s dig into dynamic switching—a lesser-known but powerful feature of hybrid indexing.
This approach toggles between dense and sparse retrieval methods based on query complexity.
For instance, dense embeddings (like those from Sentence-BERT) excel at capturing semantic meaning but struggle with exact matches. Sparse methods, like BM25, fill this gap by precisely handling keyword-specific queries.
But there’s a catch—this setup demands meticulous tuning. Companies like Harvey.ai address this by using machine learning to predict the optimal retrieval method in real-time, based on query intent and historical data.
Data Management Strategies
Managing data for RAG systems at scale isn’t just about storage—it’s about flow.
Think of it like plumbing: a well-designed system ensures data moves efficiently without leaks or clogs. Distributed storage systems, like Amazon S3 or Google Cloud Storage, act as the pipes, ensuring data is accessible across nodes while minimizing latency.
One surprising insight is that data lakes aren’t just trendy—they’re transformative. Companies like Spotify have streamlined retrieval pipelines by consolidating structured and unstructured data into a single repository.
However, without robust governance, data lakes can quickly become “data swamps,” with inconsistencies.
The takeaway? Treat data management as a dynamic process. Regular audits, automated tiering, and intelligent caching aren’t just optimizations—they’re survival tools for scaling to 20 million documents and beyond.
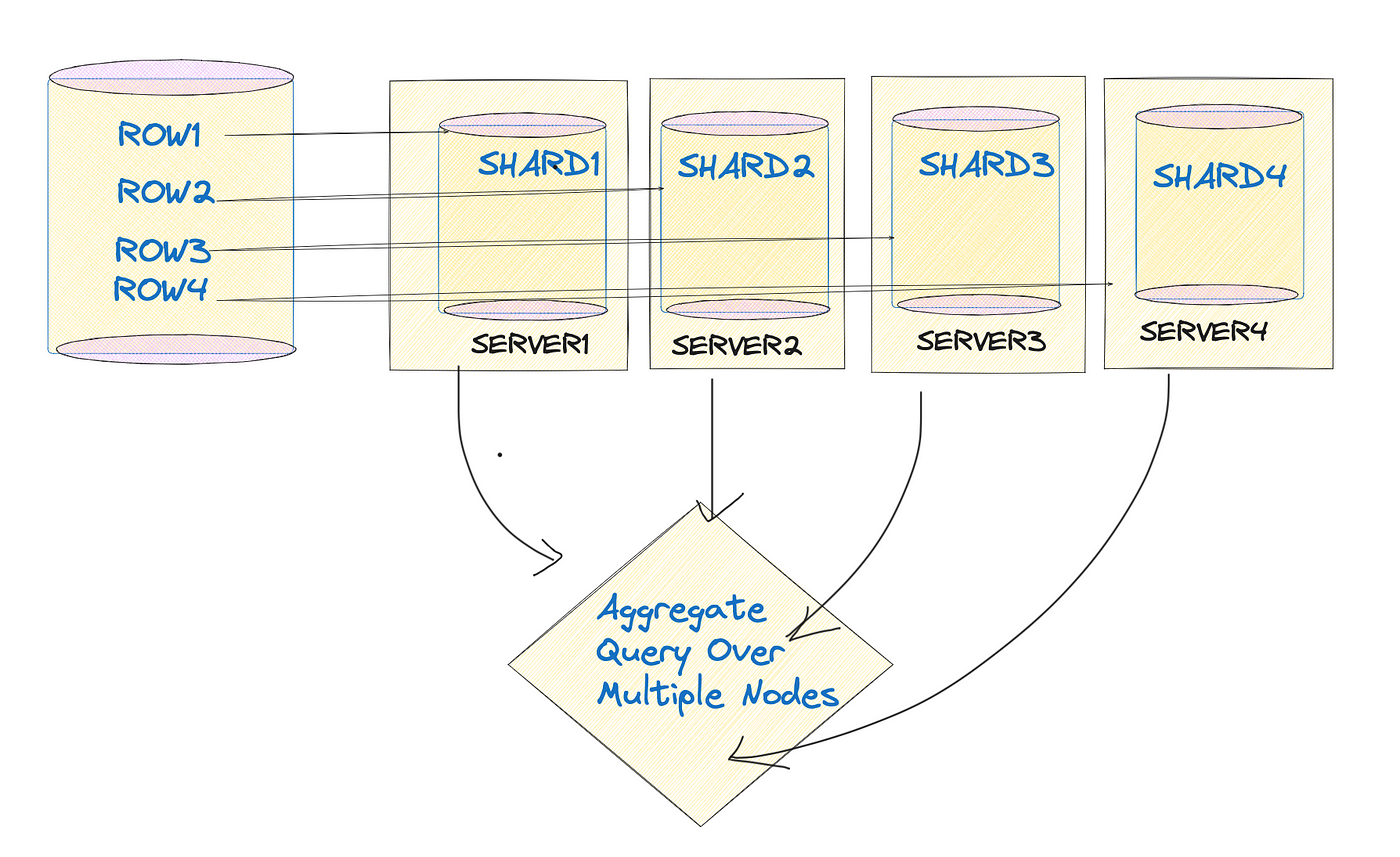
Sharding and Data Distribution
Sharding isn’t just about splitting data—it’s about splitting it smartly. The key is to align shards with query patterns.
For example, e-commerce platforms often shard by geography, ensuring that users in Europe aren’t waiting on data stored in North America. This reduces cross-region latency and keeps retrieval times snappy.
However, poorly designed shards can backfire. Imagine a shard overloaded with “hot” data while others sit idle. This imbalance, known as “hotspotting,” can cripple performance.
Companies like Netflix tackle this by dynamically redistributing shards based on real-time usage patterns, ensuring even load distribution across nodes.
Moreover, smaller shards improve parallelism but increase coordination overhead. Larger shards simplify management but risk bottlenecks.
And don’t forget fault tolerance. Sharding inherently introduces more points of failure. By replicating shards across nodes, systems like Elasticsearch ensure data availability even during outages.
The takeaway? Sharding isn’t a one-size-fits-all solution. It’s a balancing act that requires constant monitoring and adjustment. Done right, it transforms RAG systems into high-performance machines capable of scaling to millions of documents effortlessly.
Building Robust Data Pipelines
Keeping data pipelines in sync with constantly changing sources is a nightmare if you’re not prepared.
Event-driven architectures, like those powered by Apache Kafka, shine here. They capture changes as they happen, ensuring your RAG system always works with the freshest data.
It’s important to remember that streaming every tiny change can overwhelm your pipeline, leading to bottlenecks.
Companies like Spotify solve this by implementing change data capture (CDC) with filtering rules. This way, only meaningful updates—like a new song release—flow through, keeping the system lean and fast.
Emerging Trends and Future Directions
Adaptive multimodal systems are transforming RAG by integrating text, images, and videos to enhance contextual understanding.
This multimodal approach improves accuracy and relevance in industries like healthcare, finance, and customer support by providing richer, more context-aware insights. Research highlights how combining multiple data types enables models to deliver more precise responses tailored to specific use cases.
The quality of datasets is another critical factor in scaling RAG systems. Curated datasets tailored to domain-specific applications improve data usability, findability, and understandability, resulting in higher retrieval accuracy.
In contrast to massive, unfiltered datasets, structured curation reduces errors and ensures more reliable responses. A study emphasizes the impact of high-quality datasets on machine learning performance, reinforcing the need for careful data selection.
The Role of RAGOps Methodologies
Let’s dig into workflow automation—the unsung hero of RAGOps.
Automating repetitive tasks like data ingestion, model training, and inferencing isn’t just about saving time; it’s about consistency.
Remember that automation doesn’t mean “set it and forget it.”
Dynamic pipelines, powered by tools like Apache Airflow, adapt workflows in real-time based on system performance. This flexibility has helped companies like Netflix maintain sub-second retrieval times, even during traffic spikes.
However, poorly designed RAGOps can create bottlenecks, especially when integrating APIs or managing distributed systems.
The actionable takeaway? Treat RAGOps as a living system. Use automation to reduce friction, but pair it with robust monitoring and modular design. The result? A scalable, resilient RAG system that evolves with your data and user demands.
FAQ
What are the biggest challenges in scaling RAG systems to 20 million documents?
Scaling RAG systems to 20 million documents presents retrieval latency, query accuracy, and infrastructure complexity issues: Cross-node latency, inefficient indexing, and data fragmentation slow performance. Hybrid indexing, caching, and sharding help mitigate these, ensuring efficient query resolution while maintaining speed and accuracy.
How do vector databases like Pinecone and Weaviate help scale RAG systems?
Pinecone and Weaviate improve RAG scalability with distributed indexing, sharding, and hybrid search. Pinecone uses hierarchical graph indexing to cut retrieval latency, while Weaviate blends dense and sparse retrieval for better precision. These databases offer real-time indexing and automated load balancing, maintaining performance across large-scale datasets.
Why is hybrid indexing critical for RAG systems handling massive datasets?
Hybrid indexing combines sparse (BM25) and dense (vector embeddings) retrieval, balancing exact keyword matching with semantic understanding. This method reduces irrelevant results, speeds up searches, and adapts to different query types. Dynamic switching between methods improves retrieval precision while keeping response times low, making it ideal for large RAG systems.
How do sharding and data locality improve performance in distributed RAG systems?
Sharding distributes data across multiple nodes to reduce query congestion. It lowers cross-shard latency when aligned with natural data boundaries (e.g., geography). Data locality ensures frequently accessed information is near processing nodes, cutting retrieval times by up to 40%. Together, they enhance speed, reliability, and cost efficiency.
What are best practices for maintaining query accuracy in large RAG systems?
Maintaining query accuracy in large RAG systems requires hybrid indexing, feedback loops, and query routing. Dense vector embeddings enhance contextual understanding, while real-time feedback refines retrieval accuracy. Dynamic query construction and index maintenance help prevent performance degradation, ensuring fast, precise, and consistent results at scale.
Conclusion
Scaling Retrieval-Augmented Generation (RAG) systems to 20 million documents is more than just a storage or computing challenge.
Retrieval latency, query accuracy, and infrastructure complexity must be addressed with distributed architectures, hybrid indexing, and optimized sharding to maintain both speed and relevance.
The key to long-term success lies in building modular, adaptive systems demands. Organizations prioritizing intelligent retrieval, indexing efficiency, and infrastructure scalability will handle the data explosion and turn it into a competitive advantage.