
Effective Source Tracking in RAG Systems
Source tracking is vital for transparency in RAG systems. This guide explores techniques to accurately trace retrieved content, helping ensure reliability, build user trust, and support auditability in AI-generated responses and knowledge workflows.

Imagine asking an AI system for a fact—and having no idea where it came from. That’s the reality many organizations face today.
Retrieval-Augmented Generation (RAG) systems are powerful, but without source tracking, they often produce answers with no clear trail back to the original data.
In high-stakes settings like finance, healthcare, or law, that’s not just a technical problem—it’s a trust issue.
As RAG systems become central to enterprise workflows, source tracking in RAG systems is no longer a nice-to-have. It’s how teams know what information to rely on, which sources to verify, and where the system may have gone off track.
Without it, even accurate responses raise questions. With it, organizations gain transparency, auditability, and confidence.
This article breaks down how effective source tracking works in RAG systems, why it matters, and how to design RAG systems that don’t just retrieve and generate—but also show their work.
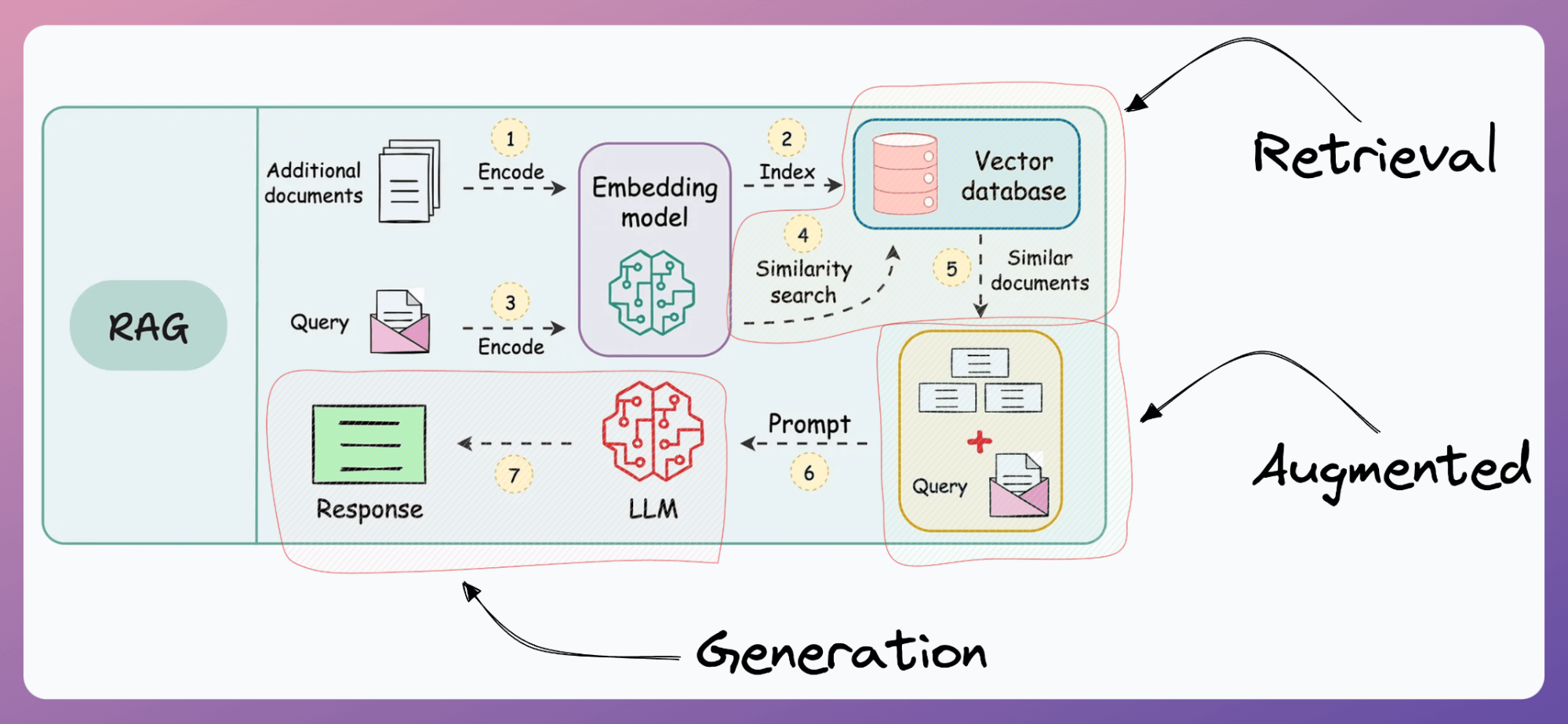
Components of RAG Architecture: The Role of Vector Databases in Retrieval
Vector databases are the unsung heroes of RAG systems. They enable precise and scalable retrieval by embedding data into high-dimensional vector spaces.
This process transforms raw information into mathematical representations that capture semantic meaning, allowing the system to perform similarity searches with unparalleled efficiency.
The significance of this lies in its ability to bridge the gap between unstructured data and actionable insights.
The choice of vector database architecture profoundly impacts retrieval quality. Systems like Pinecone and Weaviate excel in handling dense embeddings, offering optimized indexing and search algorithms tailored for large-scale datasets.
However, these solutions face challenges in balancing retrieval speed with memory efficiency, particularly when dealing with dynamic or frequently updated knowledge bases.
Hybrid approaches, combining dense and sparse retrieval techniques, are emerging as a solution to mitigate these trade-offs.
One notable implementation is OpenAI’s use of vector databases to enhance ChatGPT’s retrieval capabilities.
By integrating real-time updates, they ensure responses remain both relevant and accurate. This highlights the critical role of vector databases in transforming theoretical RAG frameworks into practical, reliable systems.
Importance of Source Tracking
Source tracking in RAG systems is not just a technical necessity but a mechanism that directly influences trust and usability.
One particularly nuanced aspect is the integration of saliency-based attribution techniques, such as those employed in the SALSA framework.
These methods prioritize the most relevant portions of retrieved data, linking them explicitly to generated outputs.
This ensures that users can precisely trace the origin of critical information, even in complex, multi-source environments.
The effectiveness of such techniques hinges on their ability to balance granularity with interpretability. While fine-grained attribution offers detailed insights, it can overwhelm users with excessive data points. Conversely, overly abstracted methods risk omitting key contextual details.
SALSA addresses this by dynamically adjusting attribution levels based on query complexity, a feature proven invaluable in high-stakes domains like legal analysis and medical diagnostics.
A notable implementation of this approach is seen in enterprise journalism, where attribution mechanisms have reduced editorial review times, streamlining fact-checking without compromising accuracy.
This underscores the transformative potential of robust source tracking in real-world applications.
Core Mechanisms of Source Tracking
Effective source tracking hinges on the interplay of precision algorithms and intuitive design, ensuring every retrieved data point is transparently linked to its origin.
This process relies on saliency-based attribution models, which dynamically highlight the most relevant data fragments.
These models, such as the SALSA framework, excel by weighting contextual importance, enabling systems to prioritize critical information without overwhelming users with extraneous details.
A pivotal yet underappreciated mechanism is vector metadata integration. By embedding metadata—such as timestamps, authorship, and data lineage—directly into vector representations, systems can perform multidimensional filtering.
This approach enhances retrieval accuracy and supports compliance with stringent regulations like the EU’s AI Act. For instance, metadata-enriched vectors allow auditors to trace the lifecycle of a data point, addressing concerns about opaque AI decision-making.
Think of source tracking as similar to annotating a complex map: every landmark (data point) must be clearly labeled and contextually situated.
Without this, even the most advanced RAG systems risk becoming navigationally blind, undermining trust and usability.
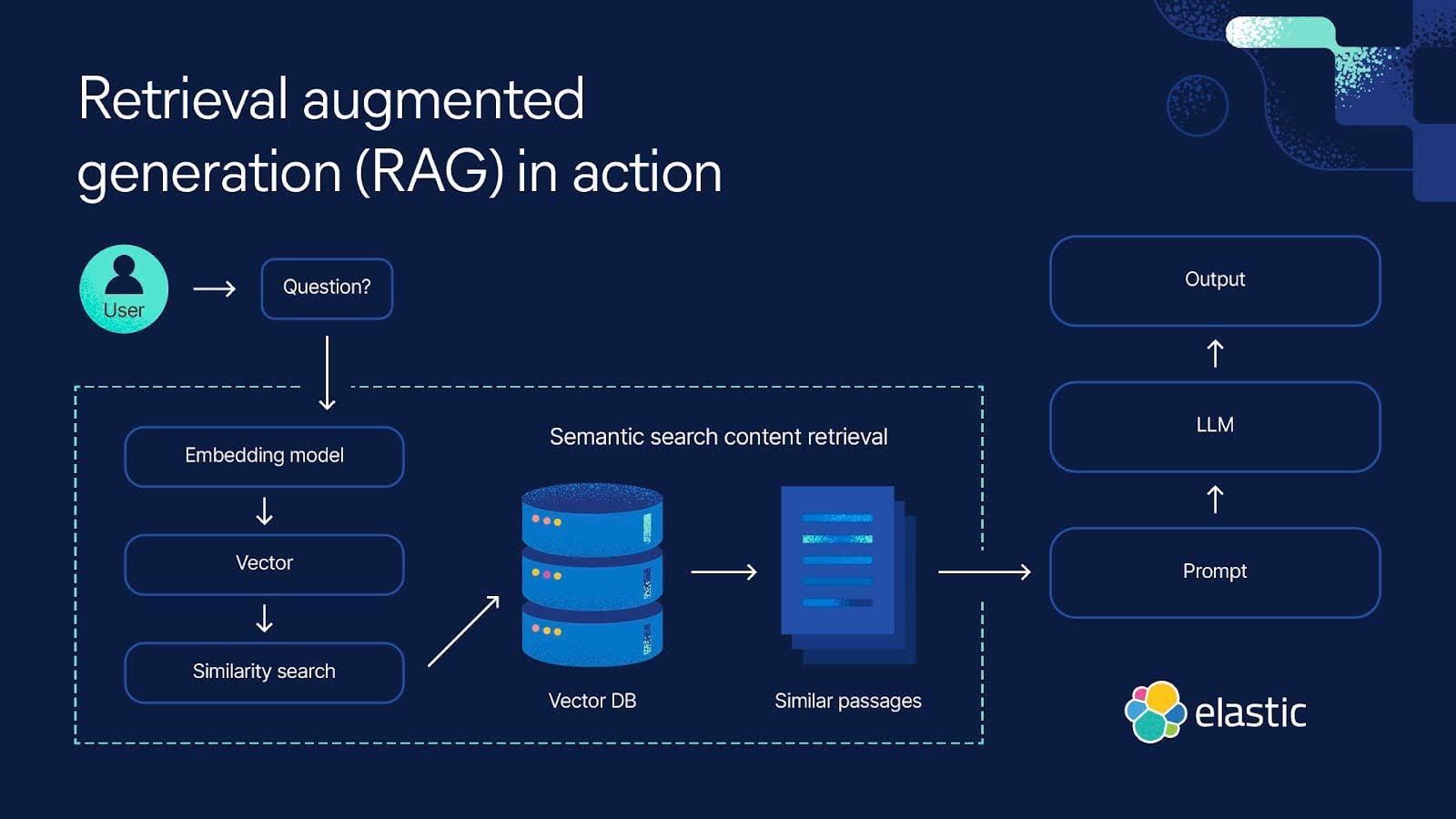
Data Collection and Indexing Techniques
The cornerstone of effective data collection and indexing lies in dynamic indexing frameworks that adapt to the evolving nature of data streams.
Unlike static indexing, which risks obsolescence in high-velocity environments, dynamic systems continuously update and reorganize data to maintain relevance and accuracy.
This approach is particularly critical in domains like healthcare, where outdated information can lead to flawed decision-making.
Dynamic indexing operates on two key principles: incremental updates and context-aware segmentation. Incremental updates ensure that new data is seamlessly integrated without disrupting existing structures.
At the same time, context-aware segmentation organizes data into logical clusters based on metadata such as timestamps, categories, or user preferences.
This dual mechanism enhances retrieval speed and ensures that the most contextually relevant information surfaces first.
A compelling example comes from the genomic research sector, where organizations like Genomics England leverage dynamic indexing to manage vast, complex datasets.
Their RAG systems achieve unparalleled retrieval precision by clustering similar genetic sequences and tagging them with rich metadata, significantly accelerating research timelines.
The challenge, however, lies in balancing computational efficiency with indexing granularity.
Overly granular systems may strain resources, while broader categorizations risk diluting relevance. This trade-off underscores the need for tailored indexing strategies that align with specific use cases.
Embedding Models and Vector Databases
Embedding models and vector databases form the backbone of effective source tracking in RAG systems, but their interplay is far more intricate than it appears.
At the heart of this relationship lies the challenge of maintaining semantic fidelity—ensuring that embeddings accurately capture the evolving nuances of data while remaining computationally efficient for retrieval.
One often-overlooked aspect is the iterative refinement of embeddings. Unlike static models, embeddings must adapt to shifts in domain-specific language, emerging terminologies, and contextual subtleties.
This requires periodic fine-tuning of pre-trained models, often leveraging domain-specific corpora to recalibrate vector representations.
The choice of vector database further complicates this dynamic. Systems like Milvus and Qdrant offer distinct trade-offs: Milvus excels in handling multi-modal data, while Qdrant’s edge lies in real-time updates.
Selecting the right database involves balancing retrieval speed, storage efficiency, and compatibility with embedding models.
Ultimately, the synergy between embedding models and vector databases transforms source tracking from a theoretical construct into a robust, adaptive mechanism.
However, achieving this requires continuous calibration, a nuanced understanding of domain-specific needs, and a commitment to iterative improvement.
Advanced Retrieval and Attribution Methods
Precision in retrieval and attribution is the linchpin of effective RAG systems, yet many overlook the transformative potential of contextual re-ranking algorithms.
These algorithms dynamically adjust retrieved results based on nuanced query intent, leveraging transformer models like BERT to align outputs with user expectations.
A common misconception is that retrieval accuracy solely depends on vector similarity. In reality, hybrid retrieval models—which combine semantic vector search with keyword-based techniques—offer a more robust solution.
By integrating BM25 with dense embeddings, systems can balance precision and recall, particularly in legal research domains where exact phrasing and contextual meaning are equally critical.
Think of attribution as a forensic audit trail. Techniques like metadata-driven filtering ensure every retrieved fragment is traceable, embedding timestamps and data lineage directly into vector representations.
This approach not only satisfies regulatory demands, such as the EU’s AI Act but also enhances user trust by making AI decisions transparent and verifiable.
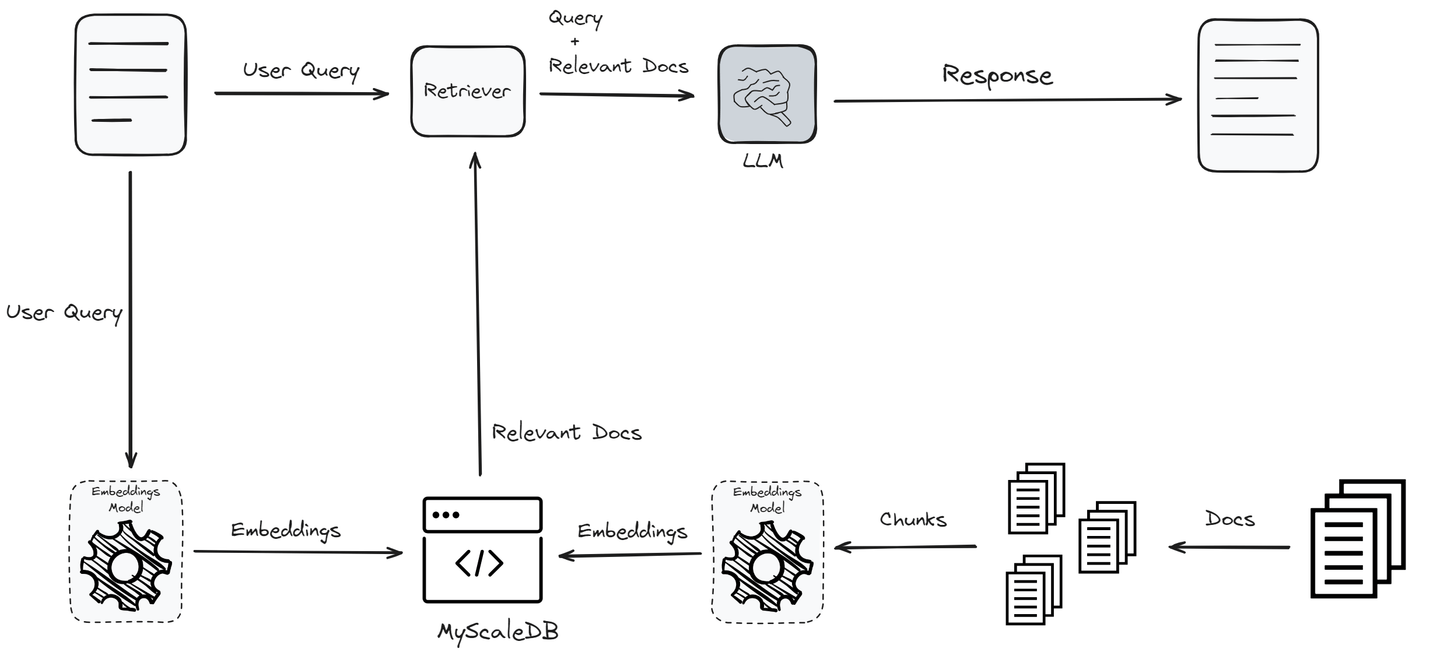
Vector Similarity Search Algorithms
Vector similarity search algorithms are the backbone of modern RAG systems, yet their effectiveness hinges on a delicate balance between computational efficiency and semantic precision.
At their core, these algorithms measure the “distance” between vectors to identify the most contextually relevant matches.
However, the choice of similarity metric—be it cosine similarity, Euclidean distance, or Manhattan distance—can significantly influence retrieval outcomes, especially in domain-specific applications.
One often-overlooked nuance is the impact of dimensionality on search performance. High-dimensional vector spaces, while capturing intricate semantic relationships, can suffer from the “curse of dimensionality,” where distances between vectors become less meaningful.
Techniques like Approximate Nearest Neighbor (ANN) search mitigate this by trading exactness for speed, making them indispensable for large-scale datasets.
Yet, their reliance on heuristic approximations introduces potential trade-offs in precision, particularly in high-stakes environments like medical diagnostics.
A compelling example comes from Spotify, which employs cosine similarity within its recommendation engine.
By fine-tuning embeddings to reflect user preferences, they balance computational efficiency and personalized relevance. This demonstrates how algorithmic choices must align with specific use cases to maximize impact.
Ultimately, the success of vector similarity search depends on iterative refinement. Embeddings must evolve alongside data, and algorithms must adapt to shifting contexts, ensuring that retrieval remains both accurate and explainable.
Integrating Source Attribution with LLM Outputs
Integrating source attribution into LLM outputs requires more than simply appending references; it involves embedding attribution as a dynamic, context-aware process.
This ensures that every generated response not only answers the query but also transparently reflects the origin and reliability of its underlying data.
The challenge lies in balancing attribution granularity with usability—too much detail can overwhelm users, while insufficient detail risks eroding trust.
A key technique is metadata-enriched embeddings, where vectors are augmented with attributes like timestamps, authorship, and data lineage.
This approach allows the system to filter and prioritize sources dynamically, ensuring that the most relevant and credible information is surfaced.
For instance, in legal research, systems like those used by LexisNexis integrate metadata to differentiate between jurisdictional precedents, enhancing both precision and traceability.
Comparatively, static citation methods, while simpler, lack the adaptability required for real-time applications.
On the other hand, dynamic attribution models excel in high-stakes environments but demand rigorous calibration to avoid introducing noise or bias.
The effectiveness of these models often hinges on the quality of the retrieval pipeline and the robustness of the underlying vector database.
Ultimately, the integration of source attribution transforms LLMs into accountable systems, bridging the gap between raw computational power and user trust. This evolution enhances transparency and sets a new standard for ethical AI deployment.
Challenges and Misconceptions in Source Tracking
A common misconception in source tracking is the assumption that retrieval systems inherently ensure accuracy.
In reality, even advanced RAG systems often retrieve outdated or contextually irrelevant data due to poorly maintained knowledge bases.
Another challenge lies in reconciling transparency with usability. While detailed attribution mechanisms enhance trust, they can overwhelm users with excessive metadata.
Think of source tracking as curating a museum exhibit: every artifact (data point) must be both authentic and contextually relevant, or the entire narrative risks losing credibility.
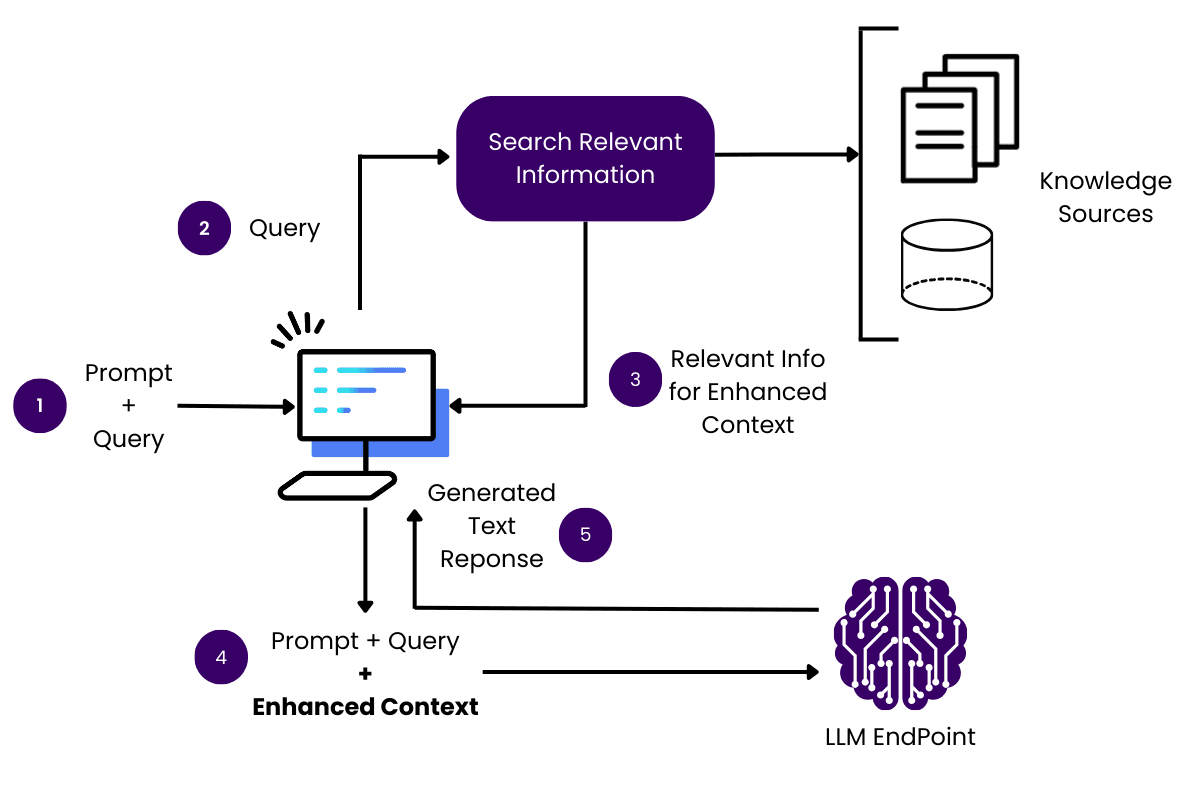
Common Misunderstandings About LLMs and Sources
One critical misunderstanding is the belief that LLMs inherently validate the accuracy of their outputs. In reality, these models depend on retrieval systems that must be meticulously maintained to ensure relevance and reliability.
Even the most advanced systems risk propagating outdated or irrelevant information without regular updates.
The underlying challenge lies in balancing retrieval precision with the dynamic nature of data. Techniques like incremental indexing allow systems to integrate new information without disrupting existing structures, but they require rigorous calibration to avoid introducing inconsistencies.
For example, organizations deploying RAG systems often face trade-offs between retrieval speed and the granularity of source attribution, particularly in high-stakes domains like healthcare or finance.
A nuanced approach involves embedding metadata directly into vector representations, enabling multi-dimensional filtering based on attributes like timestamps or authorship. This not only enhances traceability but also supports compliance with regulatory standards.
However, practitioners must remain vigilant against overloading users with excessive attribution details, which can obscure actionable insights.
Balancing Complexity and Speed in RAG Systems
Achieving the right balance between complexity and speed in RAG systems often hinges on the strategic use of query-dependent retrieval depth.
This technique dynamically adjusts the retrieval process based on the complexity of the query, ensuring that simpler queries are resolved quickly while more intricate ones receive deeper, more thorough processing.
The principle here is to allocate computational resources proportionally, avoiding unnecessary delays for straightforward tasks while maintaining rigor for high-stakes queries.
One critical factor influencing this balance is the design of retrieval pipelines. Systems incorporating progressive retrieval mechanisms—fetching high-confidence results and refining them incrementally—demonstrate superior adaptability.
For instance, this approach allows immediate responses to common inquiries in customer support applications while reserving additional processing for nuanced cases.
However, implementing such pipelines requires careful calibration to prevent bottlenecks during refinement stages.
A notable edge case arises in real-time financial analytics, where even milliseconds of delay can impact decision-making.
Here, hybrid indexing strategies combining dense and sparse retrieval ensure both speed and precision, highlighting the importance of tailoring solutions to specific operational contexts.
FAQ
What are the key components of source tracking in RAG systems?
Key components include metadata-enriched embeddings, salience-based attribution, and entity relationship mapping. These enable traceability, highlight important content, and structure data for reliable outputs across complex, high-stakes use cases.
How does salience analysis improve source attribution in RAG systems?
Salience analysis improves attribution by identifying and emphasizing the most relevant information. It helps remove noise, ensures clarity, and supports accurate linking between retrieved data and the generated response.
What role do entity relationships play in source traceability?
Entity relationships structure data into connected units, making tracking where each retrieved piece comes from easier. This improves transparency and helps the system return relevant and traceable information.
How does co-occurrence optimization improve source tracking in RAG systems?
Co-occurrence optimization finds patterns across data sources, helping the system connect related information. This improves relevance and traceability, especially when working with large or complex datasets.
What are the best practices for using metadata in RAG systems?
Best practices include adding timestamps, authorship, and data lineage to vector representations. This supports regulatory compliance, clarifies attribution, and improves the system’s ability to track sources across updates and use cases.
Conclusion
Effective source tracking in RAG systems ensures that every response is accurate, traceable, and reliable. These systems move beyond basic retrieval to deliver structured, verifiable insights by combining metadata, salience, and entity relationships. As data grows and regulations tighten, strong attribution isn’t optional—it’s essential.