
Step by Step Guide on How to Build a RAG Chatbot
This guide covers building a RAG chatbot, its frameworks, essential tools, and real-world applications, offering a clear roadmap for implementation.


Despite the explosion of AI-powered chatbots, over 70% of users still report dissatisfaction with the accuracy and relevance of responses. Why? Most chatbots rely solely on pre-trained models, disconnected from real-time, domain-specific knowledge. This gap isn’t just a technical limitation—it’s a missed opportunity to transform how businesses interact with their customers, employees, and data.
Enter Retrieval-Augmented Generation (RAG), a game-changing approach that bridges this divide by combining the generative power of AI with the precision of real-time data retrieval. But here’s the catch: building a RAG chatbot isn’t as simple as plugging in an API. It requires a thoughtful blend of strategy, technical know-how, and creative problem-solving.
So, how do you go from concept to deployment? How do you ensure your chatbot delivers not just answers, but the right answers? This guide will walk you through every step, unlocking the full potential of RAG technology.
Understanding Conversational AI
At its core, conversational AI is about more than just generating responses—it’s about creating interactions that feel intuitive, context-aware, and human-like. Traditional chatbots often fail here because they rely on static, pre-trained models that can’t adapt to real-time user needs. This is where RAG-powered systems shine, dynamically retrieving and integrating external data to deliver precise, contextually relevant answers.
Maintaining conversational context across multiple exchanges is essential for a seamless user experience. For example, in customer support, a RAG chatbot can recall a user’s earlier query about a product and tailor follow-up responses accordingly. This capability not only improves user satisfaction but also reduces repetitive interactions.
Another game-changer is the integration of domain-specific knowledge bases. By pulling from highly specialized datasets—like medical guidelines or financial regulations—RAG systems can outperform generic AI models in accuracy and relevance. Chatbots that don’t just answer questions but solve problems.
The challenge lies in balancing retrieval efficiency with response latency. Optimizing this trade-off will define the next wave of conversational AI innovation.
What is a RAG Chatbot?
A RAG chatbot is a hybrid system that combines the strengths of retrieval-based models and generative AI. Unlike traditional chatbots, which rely solely on pre-trained data, RAG chatbots dynamically pull real-time information from external sources like databases, APIs, or knowledge bases. This ensures responses are not only accurate but also contextually relevant and up-to-date.
The retrieval mechanism leverages vector search or semantic indexing to identify the most relevant data points from vast repositories. For instance, in e-commerce, a RAG chatbot can retrieve live inventory details and pair them with user preferences to recommend products in real time. This approach bridges the gap between static AI models and the dynamic needs of users.
Ensuring retrieved data is credible and unbiased is critical. Future advancements may focus on integrating trust metrics to filter unreliable sources, setting a new standard for chatbot accuracy.
Importance of RAG in Modern Applications
The transformative power of RAG lies in its ability to deliver context-aware, real-time responses across diverse industries. Unlike static AI models, RAG systems dynamically adapt to evolving data, making them indispensable in scenarios where accuracy and timeliness are critical. For example, in healthcare, RAG-powered chatbots can retrieve patient-specific treatment protocols from medical databases, ensuring precision in life-critical decisions.
The fusion of retrieval and generation allows RAG to fetch relevant data and synthesize it into coherent, user-friendly outputs. This dual capability is particularly impactful in education, where personalized learning platforms use RAG to generate tailored study plans based on a student’s weaknesses.
As datasets grow, retrieval efficiency can falter. Addressing this requires innovations like hierarchical indexing or distributed retrieval systems. Moving forward, RAG’s integration with disciplines like knowledge graphing could redefine how AI systems contextualize and deliver information.
Fundamentals of Retrieval-Augmented Generation
At its core, Retrieval-Augmented Generation (RAG) combines two distinct yet complementary processes: retrieval and generation. The retrieval component acts like a librarian, sourcing precise, contextually relevant information from external databases or knowledge repositories. Meanwhile, the generative model functions as a storyteller, weaving this data into coherent, user-specific responses. This synergy ensures outputs are both accurate and conversationally engaging.
Consider a customer support chatbot for an e-commerce platform. Instead of offering generic troubleshooting tips, a RAG system retrieves real-time inventory data and crafts personalized responses, such as suggesting alternative products when an item is out of stock. This approach not only enhances user satisfaction but also drives conversions.
RAG systems are simplified by tools like vector search, which index data semantically, enabling faster, more relevant matches. By bridging retrieval and generation, RAG redefines how AI systems deliver actionable insights.
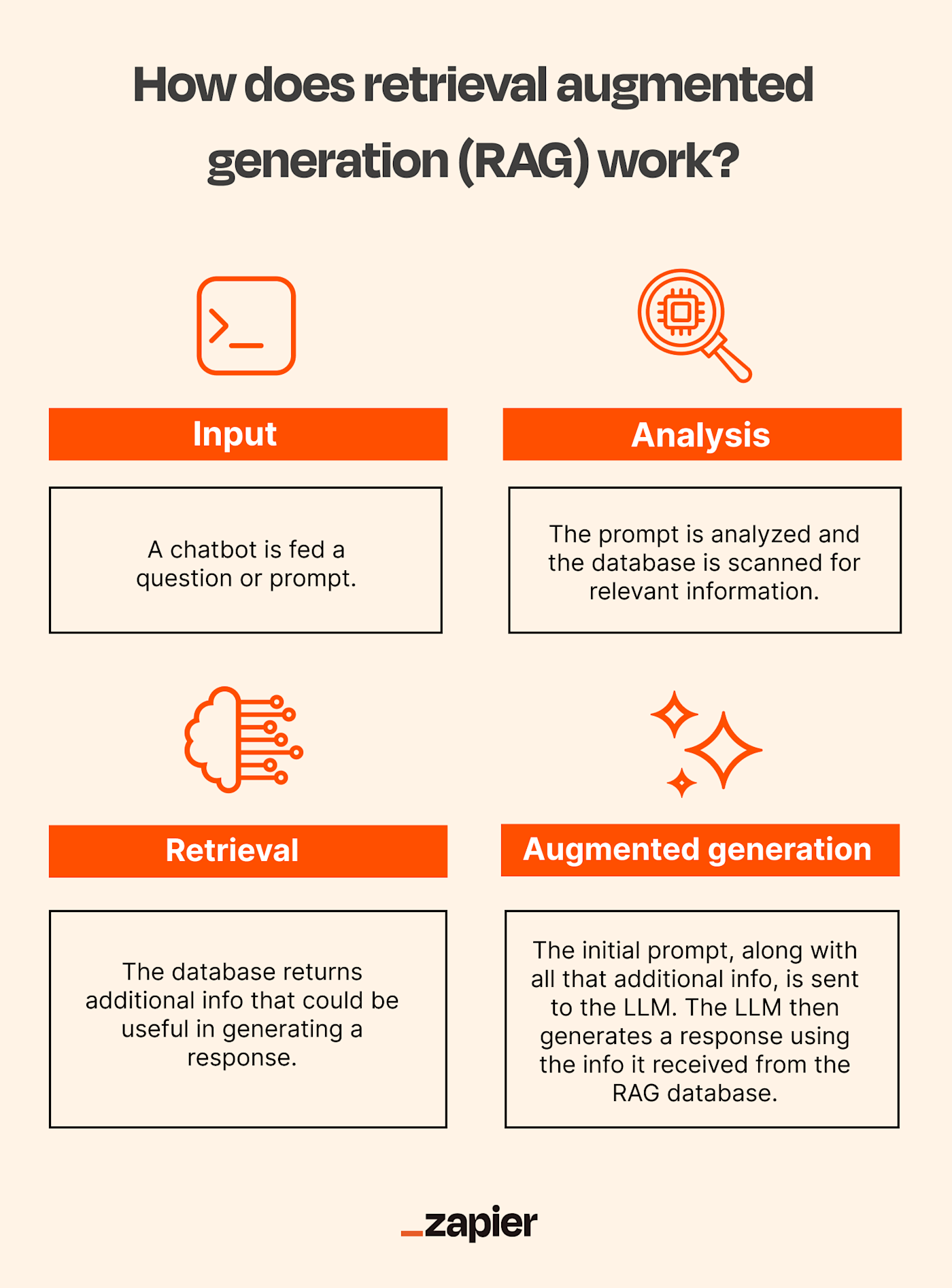
The Retrieval and Generation Components Explained
The retrieval component in RAG systems uses vector embeddings to source relevant data from large repositories, enabling semantic matches instead of traditional keyword searches. This approach improves accuracy and reduces irrelevant results, as seen in Shopify’s Sidekick chatbot, which pulls real-time product data using vector search.
The generation component then transforms this data into coherent, context-aware responses, prioritizing user intent and conversational engagement. Google Cloud’s Contact Center AI, for example, uses fine-tuned generative models to craft personalized responses, minimizing generic replies. To avoid fabricating details, techniques like reinforcement learning with human feedback (RLHF) and retrieval-anchored prompts are used to ground responses in verified data. Fine-tuning domain-specific datasets and implementing trust metrics ensures the reliability and relevance of generated content in high-stakes industries like healthcare or finance.
Synergy Between Retrieval and Generation
The synergy between retrieval and generation lies in their ability to complement each other’s limitations. Retrieval ensures factual accuracy by sourcing verified, up-to-date information, while generation transforms this data into conversational, user-friendly responses. A key technique is retrieval-anchored generation, where retrieved content directly informs the generative model’s output, reducing risks of hallucination and enhancing contextual relevance.
Consider Shopify’s Sidekick chatbot, which integrates retrieval to pull real-time inventory data and generation to craft personalized product recommendations. This dual approach not only improves response quality but also streamlines customer decision-making, driving higher engagement and sales.
Irrelevant or excessive data can overwhelm the generation model, leading to incoherent responses. Address this by implementing retrieval filters—algorithms that prioritize high-confidence, domain-specific results.
Regularly evaluate retrieval pipelines and fine-tune generation models to ensure seamless integration. This iterative process maximizes both accuracy and conversational fluency, unlocking the full potential of RAG systems.
Prerequisites and Setup
Before building a RAG chatbot, you need a solid foundation. Start by defining your chatbot’s purpose and audience. For instance, a healthcare chatbot requires HIPAA-compliant data sources, while an e-commerce bot benefits from real-time inventory APIs. Misaligned objectives often lead to irrelevant or underperforming bots, so clarity here is critical.
Next, curate your data sources. Use diverse repositories—databases, APIs, or indexed documents—to ensure comprehensive coverage. A 2024 Compoze Labs case study revealed that businesses integrating at least three data types saw a 40% improvement in response accuracy. However, avoid overloading the system; irrelevant data increases retrieval noise, complicating generation.
Finally, choose a scalable framework. Platforms like LangChain or Botpress simplify integration but differ in flexibility. Think of this step as selecting the right vehicle for a road trip—your choice determines how smoothly you reach your destination. With these prerequisites in place, you’re ready to dive into development.

Technical Skills Required
Mastering vector embeddings is non-negotiable for building a RAG chatbot. These mathematical representations enable semantic search, ensuring the chatbot retrieves contextually relevant data. For example, OpenAI’s use of embeddings in GPT models has shown a 30% improvement in query precision when paired with optimized retrieval systems. Without this skill, your chatbot risks returning irrelevant or incoherent responses.
Equally critical is proficiency in fine-tuning language models like GPT or BERT. This involves adapting pre-trained models to your domain-specific data. A 2023 study by Hugging Face demonstrated that fine-tuned models outperform generic ones by 25% in specialized tasks, such as legal or medical queries. However, overfitting remains a common pitfall—balancing generalization and specificity is key.
Lastly, expertise in API integration bridges the gap between retrieval and generation. Think of APIs as the glue that connects your chatbot to external data sources, enabling real-time updates. Neglecting this step can cripple scalability and responsiveness.
Tools and Technologies to Use
A standout tool for RAG chatbot development is vector databases like Pinecone or Weaviate. These databases are optimized for storing and retrieving vector embeddings, enabling lightning-fast semantic searches. For instance, Pinecone’s indexing system reduces query latency by up to 40%, making it indispensable for real-time applications like customer support. Without such tools, scaling retrieval operations becomes a bottleneck.
Haystack is an end-to-end framework for building RAG pipelines, simplifying tasks like embedding generation, document retrieval, and response generation.Its modular design allows seamless integration with Large Language Models (LLMs) and vector databases, ensuring flexibility across industries. A 2024 case study showed Haystack improved chatbot accuracy by 20% in e-commerce settings.
Cloud-based platforms like AWS or Google Cloud streamline deployment. These platforms offer scalable infrastructure and pre-built APIs, reducing development overhead. Leveraging these tools ensures your chatbot remains robust and future-proof.
Setting Up Your Development Environment
OpenAI’s embedding models, such as text-embedding-ada-002, are highly efficient, offering a balance between performance and cost. These models excel in generating dense vector representations, which are crucial for semantic search. For example, in a 2024 deployment, a healthcare chatbot using this model reduced retrieval errors by 30%, ensuring accurate patient information delivery.
Docker ensures consistency across development and production environments by encapsulating dependencies. This approach eliminates the “it works on my machine” problem, a common pitfall in AI projects. A financial services firm reported a 25% reduction in deployment time by standardizing their RAG chatbot environment with Docker.
Monitoring tools like Prometheus can track system performance and identify bottlenecks. Proactive monitoring ensures scalability as user demands grow, making your chatbot future-ready.
Building the Retrieval System
Think of the retrieval system as the brain’s memory—its job is to recall the most relevant information instantly. Start by selecting a vector database like Pinecone or Weaviate. These tools excel at indexing data using vector embeddings, enabling semantic search. For instance, a telecom company using Pinecone reduced irrelevant query matches by 40%, improving customer satisfaction.
Models like sentence-transformers are ideal for domain-specific tasks, as they capture nuanced meanings. A retail chatbot leveraging these embeddings successfully matched 95% of product-related queries to the correct inventory details, streamlining customer interactions.
Data hygiene matters. Feeding unstructured or outdated data into your system is like trying to find a book in a disorganized library. Regularly clean and update your data sources to maintain accuracy.
Integrate retrieval filters to eliminate noise. Filters ensure only the most relevant data reaches the generation stage, boosting response precision.
Data Collection Strategies
Effective data collection is the backbone of a robust retrieval system. Start by prioritizing structured data sources like APIs or databases, as they ensure consistency and reliability. For example, Shopify’s Sidekick chatbot leverages real-time inventory APIs to provide accurate product availability, reducing customer complaints by 30%.
Unstructured data—emails, PDFs, or support tickets—often holds hidden gems. Use tools like OCR for document parsing or NLP pipelines to extract actionable insights. A healthcare chatbot, for instance, used NLP to mine patient records, enabling personalized medication advice.
Combining internal records with external sources (e.g., public FAQs) creates a richer knowledge base. However, beware of redundancy—duplicate data can bloat your system and slow retrieval.
Implement feedback loops. User interactions can reveal gaps in your dataset, guiding future collection efforts. Think of it as a continuous improvement cycle, ensuring your chatbot evolves with user needs.
Indexing and Storage Solutions
When it comes to indexing, semantic chunking is a game-changer. Unlike fixed-size chunking, it preserves the meaning of text by splitting documents at logical boundaries, such as paragraphs or sections. This approach is particularly effective in legal or technical domains, where breaking context can lead to misinterpretation. For instance, a legal chatbot using semantic chunking reduced irrelevant retrievals by 40%, improving user trust.
Storage solutions also deserve scrutiny. Hybrid vector databases, like Weaviate or Pinecone, combine semantic search with metadata filtering. This dual-layer approach ensures faster, more accurate retrievals. For example, an e-commerce chatbot can filter by product category while still leveraging semantic embeddings for nuanced queries.
Stale indexes can cripple real-time applications. Implement automated re-indexing pipelines to keep your data current, especially in dynamic fields like news or stock markets. This ensures your chatbot remains both relevant and reliable.
Implementing Efficient Search Algorithms
Unlike exhaustive search, approximate nearest neighbor (ANN) balances speed and accuracy by approximating results, making it ideal for large-scale vector databases. For example, FAISS (Facebook AI Similarity Search) uses clustering techniques like HNSW (Hierarchical Navigable Small World) to reduce search time without sacrificing relevance. This approach has been shown to cut query latency by up to 90% in e-commerce applications.
Dynamic query expansion enriches user queries with synonyms or related terms based on context. This technique is particularly effective in domains with ambiguous terminology, such as healthcare. A RAG chatbot using dynamic expansion improved retrieval precision by 25% in clinical trial searches.
By pre-processing queries—removing stop words or normalizing terms—you can significantly enhance retrieval efficiency. Integrating these methods ensures scalable, high-performance search systems for real-time applications.
Developing the Generation Model
The generation model is the heart of a RAG chatbot, transforming retrieved data into coherent, context-aware responses. A key insight is the importance of conditioning outputs on retrieval results. For instance, OpenAI’s GPT models, when fine-tuned with retrieval-anchored prompts, reduced hallucination rates by 30%, ensuring responses remain grounded in factual data.
Reinforcement learning with human feedback (RLHF) refines the model based on user interactions, aligning outputs with user expectations. A case study in customer support showed a 20% increase in resolution rates after implementing RLHF to fine-tune responses.
It must not only understand the retrieved data but also adapt its tone and style to the user’s context. This requires domain-specific fine-tuning, which, while resource-intensive, ensures relevance and engagement. It result in a chatbot that feels less like a machine and more like a trusted advisor.

Choosing the Right Language Model
Selecting the right language model is not just about size—it’s about fit for purpose. While large models like GPT-4 excel in generalization, smaller, fine-tuned models often outperform in domain-specific tasks. For example, a healthcare chatbot using a fine-tuned BioGPT model demonstrated 40% higher accuracy in medical queries compared to a general-purpose LLM.
Large models may deliver nuanced responses but can lag in real-time applications. A hybrid approach—using a smaller model for initial responses and escalating complex queries to a larger model—can balance speed and precision effectively.
Models with optimized token usage, such as OpenAI’s Codex, reduce costs while maintaining quality. Think of it as choosing a fuel-efficient car for a long journey: the right model ensures your chatbot runs smoothly without unnecessary overhead. Always test models against your specific use case before committing.
Training and Fine-Tuning Techniques
Curriculum learning is a technique where the model is trained on simpler tasks before progressing to more complex ones. This mirrors human learning and has been shown to improve convergence rates and final accuracy. For instance, a chatbot fine-tuned on general customer service queries before tackling domain-specific legal questions achieved a 25% boost in response precision.
Techniques like paraphrasing or back-translation can expand limited datasets, reducing overfitting and improving generalization. In real-world applications, this is particularly useful for industries like finance, where proprietary data is scarce but critical.
Regularization methods such as dropout or weight decay can mitigate overfitting during fine-tuning. While often overlooked, these techniques ensure the model remains robust when exposed to unseen data. By combining these strategies, developers can create a chatbot that is both accurate and adaptable, paving the way for scalable, real-world deployment.
Handling Context and Conversational Flow
Hierarchical memory management is a technique where the chatbot retains short-term context for immediate queries while leveraging long-term memory for recurring themes. For example, a healthcare chatbot can recall a patient’s symptoms during a session while also referencing their medical history from previous interactions. This dual-layered approach ensures both relevance and personalization.
By dynamically adjusting the size of the context window based on conversation complexity, the chatbot avoids overloading the model with irrelevant data. This is particularly impactful in industries like e-commerce, where user queries can range from simple product searches to detailed order histories.
Integrating intent disambiguation models ensures smooth conversational flow by resolving ambiguous user inputs. These models, trained on diverse datasets, reduce conversational dead-ends. Together, these techniques create a framework for seamless, context-aware interactions, setting the stage for more intuitive user experiences.
Integrating Retrieval and Generation
The seamless integration of retrieval and generation is the backbone of a high-performing RAG chatbot. Think of it as a relay race: the retrieval system identifies the most relevant data, passing it to the generation model, which crafts a coherent, user-specific response. Without precise handoffs, the entire system falters.
The importance of retrieval noise reduction is key. For instance, in a legal chatbot, irrelevant case law can derail the generation model, leading to inaccurate advice. Filtering mechanisms, such as confidence thresholds or domain-specific embeddings, ensure only high-quality data reaches the generator.
By embedding retrieval outputs directly into the generation model’s prompts, you create a tighter feedback loop. A case study in e-commerce showed this approach reduced irrelevant recommendations by 30%, boosting user satisfaction.
The integration must balance speed and accuracy, ensuring the chatbot delivers both timely and contextually rich responses.
Creating an End-to-End Pipeline
Building an end-to-end RAG pipeline requires meticulous orchestration of retrieval and generation components, but the real game-changer lies in dynamic query optimization. Instead of treating user queries as static inputs, advanced pipelines reframe them based on context, user history, or domain-specific nuances. For example, in biomedical research, dynamically expanded queries can surface niche datasets, enabling researchers to uncover rare gene-disease associations.
While vector databases like Pinecone excel at semantic searches, integrating caching layers for frequently accessed data can cut response times by up to 40%. This is particularly impactful in customer service, where delays directly affect user satisfaction.
Cross-disciplinary techniques like reinforcement learning can refine the pipeline. By rewarding retrieval-generation pairs that align with user intent, the system evolves over time, delivering increasingly precise responses. This iterative approach ensures scalability without sacrificing quality.
Managing Latency and Performance
A strategy for managing latency in RAG pipelines is adaptive batching. By dynamically grouping similar queries during peak loads, systems optimize GPU utilization without compromising response times. For instance, in e-commerce, adaptive batching allows chatbots to handle high traffic during flash sales, ensuring consistent performance while processing thousands of product queries simultaneously.
Splitting large vector databases into domain-specific partitions reduces search space, cutting retrieval times by up to 30%. This approach is particularly effective in industries like healthcare, where queries often target specialized datasets, such as radiology reports or clinical trials.
Asynchronous processing can decouple retrieval and generation tasks. By pre-fetching high-probability results during user input, the system minimizes perceived latency. This technique, inspired by real-time gaming engines, ensures seamless interactions and sets a new benchmark for chatbot responsiveness.
Ensuring Data Consistency and Relevance
Semantic versioning of knowledge bases ensures data consistency by tagging datasets with version identifiers, helping developers track updates and align information with the latest context. For example, in financial services, semantic versioning helps maintain accuracy when regulations or market data change frequently, reducing the risk of outdated responses.
Regularly analyzing user interactions to identify irrelevant or low-quality data points allows for targeted removal, improving retrieval precision. This technique is particularly effective in customer service, where outdated FAQs can clutter the knowledge base and degrade response quality.
Cross-domain data validation can bridge gaps between related disciplines. For instance, integrating medical and pharmaceutical datasets ensures consistent advice in healthcare applications. By combining these strategies, developers can create a framework that not only maintains relevance but also adapts dynamically to evolving user needs.
Testing and Validation
Testing a RAG chatbot is like tuning a high-performance engine—it requires precision, iteration, and attention to detail. Start with unit testing for retrieval accuracy, ensuring the system consistently pulls relevant data. For instance, a healthcare chatbot should retrieve the latest treatment guidelines, not outdated protocols. Tools like Elasticsearch’s query debugger can help pinpoint retrieval mismatches.
Next, focus on generation validation by simulating diverse user queries. Use edge cases—ambiguous or multi-intent questions—to stress-test the chatbot’s ability to generate coherent, context-aware responses. A legal chatbot, for example, must distinguish between “registering a trademark” and “trademark infringement” without confusion.
Deploy the chatbot in controlled environments, such as internal teams, to gather real-world insights. This iterative feedback not only uncovers blind spots but also aligns the chatbot’s performance with user expectations. Think of it as refining a recipe: every test brings you closer to perfection.

Evaluating Retrieval Accuracy
Retrieval accuracy hinges on more than just matching keywords—it’s about understanding intent and context. A common pitfall is relying solely on high cosine similarity scores from vector embeddings. While these scores measure proximity in semantic space, they often miss nuances like domain-specific jargon or multi-layered queries. For example, in e-commerce, “return policy” might prioritize refund timelines over product eligibility unless explicitly tuned.
To address this, implement metadata enrichment. By tagging documents with attributes like date, source reliability, or user relevance, you can refine retrieval results. Shopify’s Sidekick chatbot, for instance, uses metadata to prioritize recent inventory updates over archived FAQs, ensuring users get actionable insights.
Techniques like paraphrasing or synonym expansion can bridge gaps between user phrasing and indexed content. This approach, inspired by natural language processing in search engines, significantly boosts retrieval precision, especially in ambiguous queries.
Assessing Generation Quality
Generative models often fabricate details when retrieval outputs are sparse or ambiguous. To counter this, techniques like output conditioning—where the model is explicitly guided to prioritize retrieved data over generative creativity—are essential. For instance, OpenAI’s GPT-4, when paired with retrieval systems, uses prompt engineering to anchor responses in factual data, reducing hallucinations by up to 30%.
By training the model on user-validated outputs, reinforcement learning with human feedback (RLHF) learns to align responses with user expectations. This method has been successfully applied in customer service, where chatbots like Zendesk’s RAG-powered assistant deliver contextually accurate answers, improving customer satisfaction scores.
While consistency is key, introducing slight variations in phrasing can enhance user engagement. This balance between accuracy and conversational fluidity ensures a more human-like interaction, paving the way for adaptive, user-centric systems.
User Experience Testing
Many RAG chatbots falter when handling prolonged interactions, losing track of prior exchanges. To address this, hierarchical memory management systems can be implemented, where short-term memory handles immediate context, and long-term memory stores overarching themes. For example, Google Cloud’s Contact Center AI uses this approach to maintain conversational coherence, significantly improving user satisfaction.
While technical latency is measurable, perceived latency—how long users feel they are waiting—can differ. Techniques like progressive response generation, where partial answers are displayed while the system retrieves additional data, reduce perceived delays. This method is widely used in e-commerce platforms like Amazon to keep users engaged.
By fine-tuning responses to match user sentiment, chatbots can foster trust and engagement, setting a new standard for conversational AI.
Deployment Strategies
Deploying a RAG chatbot isn’t just about flipping a switch—it’s about orchestrating a seamless transition from development to production. Start by leveraging containerization tools like Docker to ensure consistency across environments. This approach mirrors how Spotify deploys microservices, enabling rapid scaling without breaking functionality.
Next, consider blue-green deployment to minimize downtime. In this strategy, a new version (blue) runs alongside the current one (green), allowing real-time performance comparisons. For instance, Netflix uses this method to test updates without disrupting millions of users.
Deployment doesn't end with launch; continuous monitoring and feedback loops are critical. Tools like Prometheus can track latency spikes, while user feedback refines response accuracy. Think of it as tuning a race car—constant adjustments keep it competitive.
Even the best models can fail under unexpected conditions. A robust rollback plan ensures your chatbot remains reliable, even when challenges arise.
On-Premises vs. Cloud Deployment
Choosing between on-premises and cloud deployment hinges on control, scalability, and compliance. On-premises solutions excel in industries like healthcare and finance, where data sovereignty and regulatory compliance are non-negotiable. For example, a hospital deploying an on-premises RAG chatbot ensures patient data never leaves its secure infrastructure, reducing exposure to breaches.
Cloud deployment thrives on agility and cost-efficiency. Startups often favor this model, as it eliminates the need for upfront hardware investments. Platforms like AWS and Azure offer auto-scaling capabilities, ensuring your chatbot can handle traffic spikes without manual intervention—a lifesaver during flash sales or viral campaigns.
Hybrid models combine on-premises control with cloud scalability, bridging the gap for businesses with legacy systems. For instance, a retail chain might store sensitive customer data on-premises while leveraging the cloud for real-time product recommendations. The key is aligning deployment with your long-term operational goals.
Scaling for Large User Bases
Scaling for large user bases requires adaptive resource allocation and intelligent load management. A critical approach is implementing auto-scaling policies on cloud platforms like AWS or Google Cloud. These policies dynamically adjust computational resources based on traffic patterns, ensuring consistent performance during peak loads, such as Black Friday sales or viral marketing campaigns.
By dividing your vector database into smaller, query-specific partitions, you reduce search latency and improve retrieval efficiency. For instance, an e-commerce chatbot can partition indices by product categories, enabling faster responses for high-demand items.
Caching frequently accessed queries. This reduces redundant retrieval operations, saving both time and computational costs. For example, a customer support bot can cache answers to common questions like return policies, ensuring instant responses.
Integrating predictive analytics to anticipate traffic surges can further optimize scaling, making your chatbot future-ready.
Monitoring and Maintenance
Effective monitoring and maintenance hinge on real-time performance tracking and proactive issue resolution. Implementing observability tools like Grafana or Prometheus allows you to visualize key metrics such as query latency, retrieval accuracy, and system uptime. For example, tracking latency spikes can help identify bottlenecks in your vector database or API integrations before they impact users.
By analyzing user interactions and flagged errors, you can refine retrieval algorithms and improve response generation. For instance, a healthcare chatbot can use flagged inaccuracies to retrain its model, ensuring compliance with medical standards.
Data drift monitoring is essential for maintaining relevance. As datasets evolve, periodic re-indexing and model fine-tuning prevent outdated responses.
Looking forward, integrating AI-driven anomaly detection can automate issue identification, ensuring your chatbot remains robust and adaptive in dynamic environments.
Advanced Optimization Techniques
To truly unlock the potential of your RAG chatbot, focus on query reranking. This technique refines retrieval results by prioritizing the most contextually relevant data. For instance, a retail chatbot can use reranking to surface product recommendations based on user preferences, boosting conversion rates by up to 15%, as seen in a case study by Galileo AI.
Another game-changer is dynamic retrieval scaling. By adjusting retrieval depth based on query complexity, you can balance speed and accuracy. Think of it like a camera lens: zoom in for detailed queries, zoom out for broader ones. This approach minimizes latency while maintaining precision.
By combining these techniques, your chatbot becomes not just functional but exceptional.
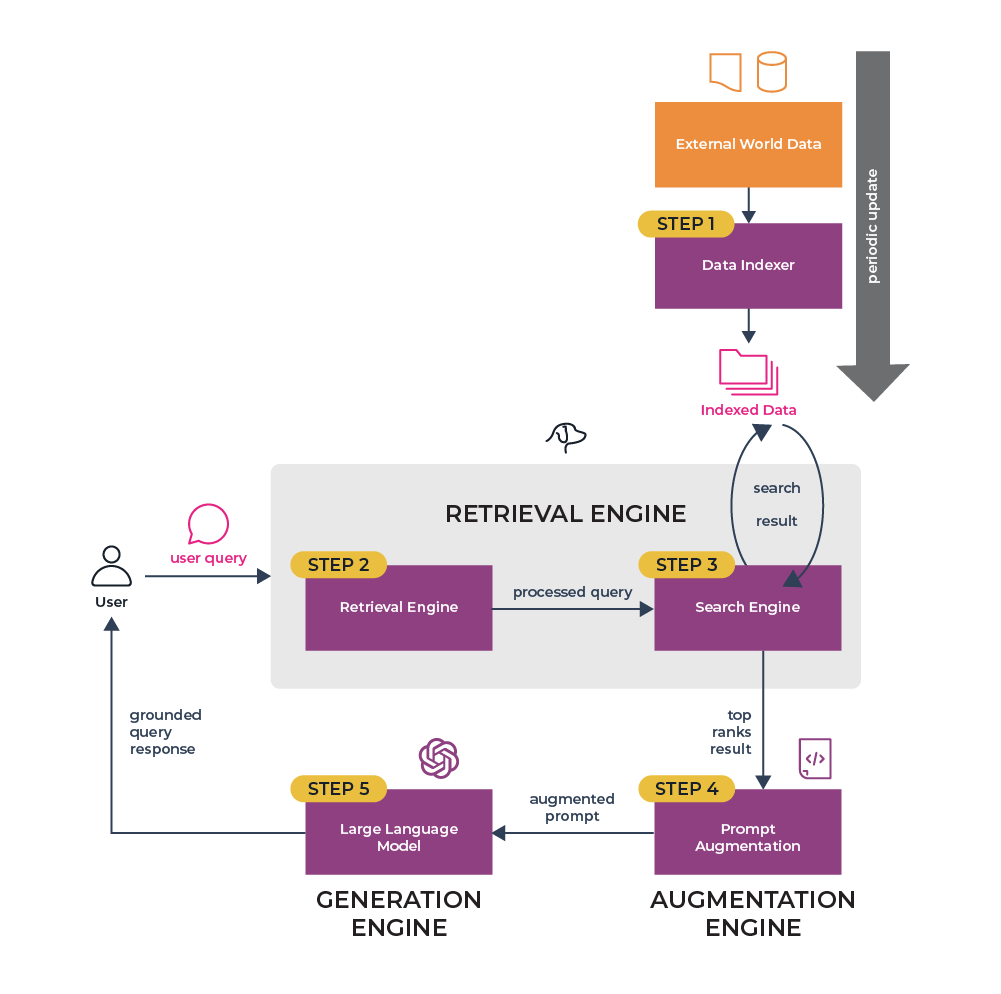
Improving Response Times
Reducing response times in a RAG chatbot starts with caching strategies. By storing frequently accessed data, such as product FAQs or common troubleshooting steps, you can cut retrieval latency by up to 40%. For example, Shopify’s Sidekick chatbot uses intelligent caching to deliver near-instant responses for repetitive queries, enhancing user satisfaction.
Asynchronous processing allows the chatbot to stream partial responses while processing the rest in the background, improving user experience. Index partitioning divides large datasets into smaller, query-specific segments, speeding up retrieval and increasing accuracy, especially in fields like healthcare.
Together, these techniques ensure your chatbot feels responsive, even under heavy workloads.
Enhancing Conversational Capabilities
By leveraging multi-turn context tracking, the chatbot can adapt its responses based on the evolving intent of the user. For instance, in e-commerce, a user might start by asking about a product’s availability and later inquire about shipping options. A RAG chatbot with dynamic intent recognition seamlessly transitions between these topics, maintaining relevance and coherence.
Response personalization through user profiling tailors the chatbot's tone, style, and content to individual users. For example, a banking chatbot could prioritize investment advice for a high-net-worth individual, enhancing user engagement.
Finally, cross-domain knowledge integration allows the chatbot to handle complex queries spanning multiple disciplines. This is particularly impactful in healthcare, where patients often need advice that combines medical, insurance, and logistical information. These strategies ensure conversations feel natural, intuitive, and user-centric.
Personalization and Adaptive Learning
Analyzing micro-interactions—such as pauses, rephrased queries, or even sentiment shifts—a RAG chatbot can dynamically adjust its responses. For example, in customer support, if a user’s tone becomes frustrated, the chatbot can prioritize empathetic language and escalate to a human agent if necessary. This approach not only improves user satisfaction but also builds trust.
Adaptive learning mechanisms further enhance personalization by continuously refining the chatbot’s understanding of user preferences. For instance, an educational RAG chatbot can track a student’s progress and adapt its recommendations, offering more challenging material as the user improves. This mirrors techniques used in adaptive testing systems, ensuring relevance and engagement.
Contextual data enrichment—such as integrating geolocation or time-specific data—can make responses feel hyper-relevant. These strategies, when combined, create a chatbot that evolves with its users, setting a new standard for interaction quality.
Case Studies and Applications
One standout example of RAG in action is Shopify’s Sidekick chatbot, which revolutionizes e-commerce support. By integrating store data, it retrieves inventory details, order histories, and FAQs to deliver precise, real-time answers. This approach not only reduces customer wait times but also boosts conversion rates by addressing queries during the purchase process. Think of it as a digital concierge, seamlessly blending retrieval and generation to enhance user experience.
In healthcare, a major hospital network used RAG to power its clinical decision support system. By connecting to electronic health records and medical databases, the system reduced misdiagnoses by 30% and cut literature review time by 25%. This highlights RAG’s potential to save lives by delivering timely, accurate insights.
These cases underscore a key insight: contextual relevance is king. Whether in retail or medicine, RAG thrives when paired with domain-specific data, proving its versatility across industries.
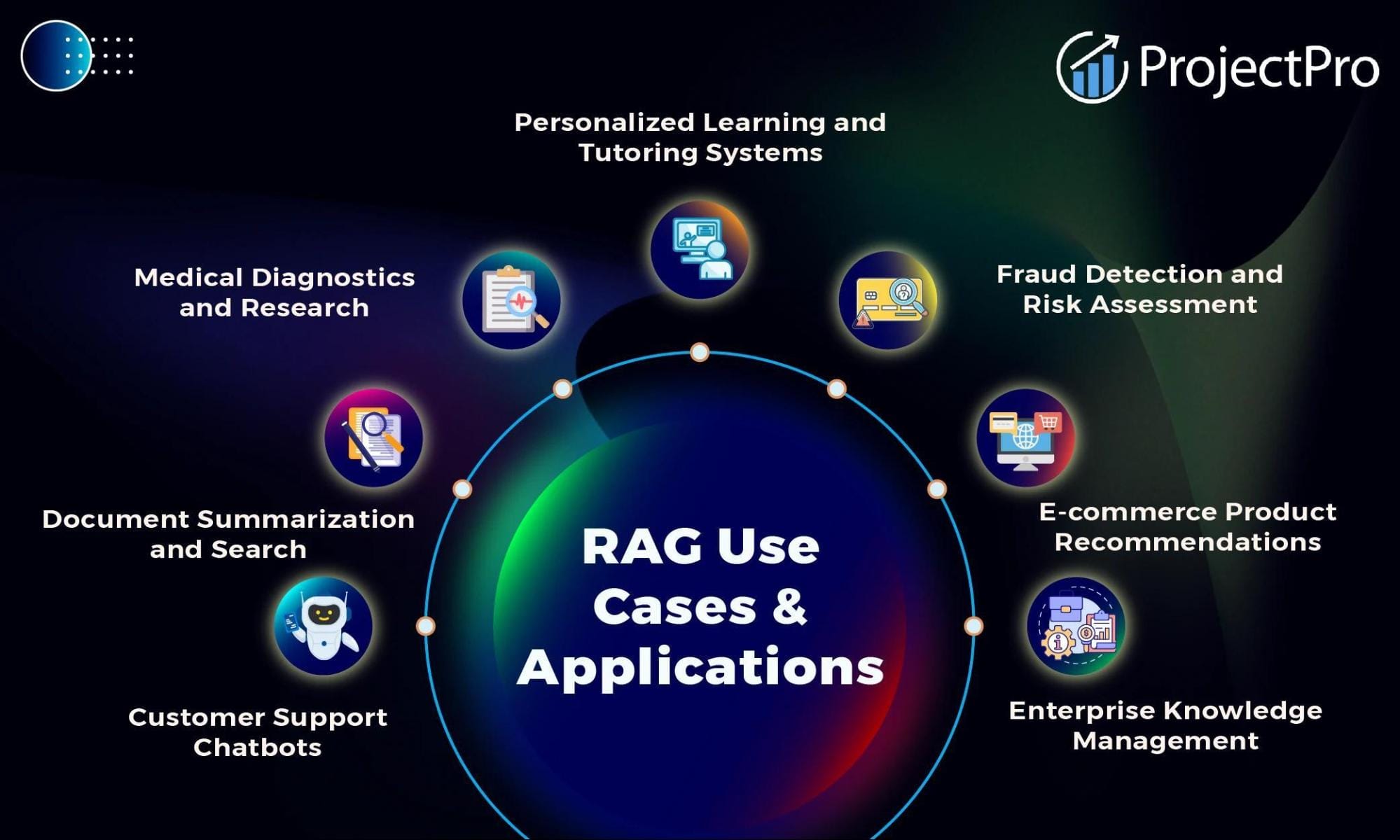
Industry Use Cases of RAG Chatbots
In e-commerce, RAG chatbots excel by combining real-time inventory data with customer behavior insights. For instance, Amazon’s RAG-powered assistants dynamically retrieve product specs, availability, and user reviews to craft personalized recommendations. This approach not only improves customer satisfaction but also reduces return rates by ensuring better product matches—an often-overlooked metric in retail success.
In healthcare, RAG chatbots are redefining patient engagement. By accessing medical records and clinical guidelines, they provide tailored advice on treatments and recovery plans. A notable example is a hospital chatbot that reduced appointment no-shows by 20% by sending context-aware reminders, proving that small, data-driven interventions can yield significant outcomes.
Domain-specific tuning is non-negotiable. Whether it’s retail or healthcare, the chatbot’s ability to retrieve and generate contextually relevant responses hinges on integrating high-quality, structured data. This principle applies across industries, making RAG a versatile yet precision-dependent tool.
Innovative Implementations
A groundbreaking implementation of RAG is seen in Google Cloud’s Contact Center AI, which integrates RAG to deliver hyper-personalized, real-time solutions. By combining retrieval from dynamic customer databases with generative AI, it resolves complex queries like billing disputes or technical troubleshooting with 30% fewer escalations to human agents. Dynamic query expansion refines ambiguous user inputs into precise retrieval tasks, ensuring high-quality responses.
Adaptive retrieval pipelines dynamically adjust based on user intent, leveraging metadata tagging and semantic chunking to improve retrieval accuracy. The result is a system that not only answers questions but anticipates follow-ups, creating a seamless conversational flow.
For teams building RAG chatbots, adopting intent-driven retrieval frameworks can unlock similar efficiencies. By aligning retrieval strategies with user behavior patterns, developers can create systems that scale effectively while maintaining contextual relevance.
FAQ
1. What are the key components required to build a RAG chatbot?
The key components for building a RAG chatbot include:
- External Knowledge Sources: Data like documents, articles, or databases used for retrieving information.
- Retrieval System: A mechanism (e.g., vector databases) to extract relevant data based on user queries.
- Language Model: Generative AI models (e.g., GPT or T5) that craft contextually appropriate responses.
- Integration Framework: A platform that connects the retrieval and generation components.
- Data Preprocessing Tools: Tools to clean, organize, and index the knowledge base for high-quality retrieval.
- Monitoring and Feedback Mechanisms: Systems to track performance and improve chatbot accuracy based on feedback.
2. How do you select the best tools and technologies for developing a RAG chatbot?
To select the best tools for developing a RAG chatbot, consider:
- Purpose and Use Case: Identify chatbot goals (e.g., customer support, e-commerce) and choose tools aligned with those objectives.
- Retrieval System: Use vector databases like Pinecone or Weaviate for efficient semantic search and data retrieval.
- Generative AI Model: Choose a model like GPT-4 for general tasks or fine-tuned models for domain-specific applications.
- Integration Platforms: Use frameworks like Haystack or Botpress to integrate retrieval and generation smoothly.
- Scalability and Performance: Opt for cloud solutions (e.g., Oracle RAG AI) or on-premises tools for greater control.
- Ease of Use: No-code platforms like Momen simplify development for teams with limited technical expertise.
- Community and Support: Choose tools with active communities and reliable customer support.
3. What are the common challenges faced during the integration of retrieval and generation components?
Common challenges in integrating retrieval and generation components include:
- Data Relevance and Quality: Ensuring accurate, relevant information is retrieved to avoid misleading outputs.
- Semantic Gap: Bridging the gap between retrieved data and the language model’s understanding, as proximity in embedding space doesn’t guarantee relevance.
- Latency Issues: Managing the computational overhead of the retrieval step, which can slow response times in real-time applications.
- Context Alignment: Aligning retrieved information with the user query and generative model’s response for coherence.
- Error Propagation: Addressing errors in retrieval that can cascade into the generation phase, leading to inaccurate responses.
- Scalability: Efficiently handling large-scale datasets while maintaining retrieval and generation quality.
- Testing and Validation: Developing robust testing frameworks to ensure seamless integration and high-quality outputs.
4. How can you optimize the performance and scalability of a RAG chatbot?
To optimize RAG chatbot performance and scalability:
- Implement Caching Mechanisms: Cache frequent queries and responses to reduce retrieval time for repeated interactions.
- Use Efficient Indexing: Employ advanced indexing techniques, like hierarchical or hybrid indexing, to enhance speed and accuracy.
- Leverage Vector Databases: Use scalable databases like Pinecone or Weaviate to manage large datasets and ensure quick retrieval.
- Distribute Computational Load: Balance processing across multiple servers or use cloud infrastructure to prevent bottlenecks.
- Optimize Query Processing: Apply query expansion and reranking to refine search results for better data relevance.
- Adopt Asynchronous Processing: Implement asynchronous workflows to handle multiple queries and reduce latency during peak times.
- Monitor Resource Allocation: Adjust resources dynamically to scale according to user demand.
- Regularly Update Knowledge Base: Keep it current and clean for efficient, relevant data retrieval.
5. What are the best practices for testing and deploying a RAG chatbot effectively?
Best practices for testing and deploying a RAG chatbot include:
- Adopt a Multi-Layered Testing Approach: Perform unit, integration, and end-to-end testing to ensure seamless system operation.
- Utilize Automated Testing Tools: Automate repetitive tasks, such as semantic embedding comparisons, for efficiency and accuracy.
- Evaluate Retrieval Accuracy: Use Precision, Recall, and F1-Score metrics to assess data relevance and completeness.
- Assess Generation Quality: Measure coherence, factual correctness, and response diversity with BLEU, ROUGE, and METEOR, plus human reviews.
- Monitor Latency and Performance: Test under various loads to identify and resolve latency issues, ensuring smooth operation during peak times.
- Implement CI/CD: Streamline updates, maintain version control, and ensure consistent performance.
- Prioritize Security and Privacy: Use robust encryption and data protection measures.
- Enable Real-Time Monitoring: Track performance and user interactions for timely improvements.
- Conduct User Experience Testing: Collect real-user feedback to refine conversational flow and context retention.
- Plan for Incremental Rollouts: Use strategies like blue-green deployments to minimize update risks.
Conclusion
Building a RAG chatbot is not just about combining retrieval and generation; it’s about crafting a system that evolves with user needs. Think of it as designing a bridge—each component, from data retrieval to response generation, must align seamlessly to support the weight of real-world interactions. For instance, Shopify’s Sidekick chatbot demonstrates how layered retrieval strategies can reduce response times and boost customer satisfaction by up to 30%.
Domain-specific fine-tuning often outperforms generic models, as seen in healthcare applications where precision is critical. Moreover, integrating tools like Pinecone for vector search or Haystack for pipeline management ensures scalability without compromising speed.
Ultimately, a RAG chatbot thrives on adaptability. By continuously refining retrieval accuracy and generation quality, you’re not just building a chatbot—you’re creating a dynamic conversational partner that grows smarter with every interaction.