
Effective Strategies for Handling Long Chat Histories in RAG-Based Chatbots
Long chat histories can challenge RAG-based chatbots. This guide explores strategies to manage context effectively, reduce token limits, and enhance response accuracy—ensuring smoother, more intelligent conversations over extended interactions.


Chatbots are getting smarter, but long conversations still trip them up.
After a few dozen turns, even advanced systems start to lose track—giving answers that miss the point or repeat what’s already been said. You've probably seen it happen if you’ve built or used one.
This is where effective strategies for handling long chat histories in RAG-based chatbots come into play.
These systems rely on retrieving past context to generate accurate answers, which becomes more challenging as chats grow. Irrelevant snippets slip in, and essential details get buried. The result? Confused responses and frustrated users.
Understanding effective strategies for handling long chat histories in RAG-based chatbots isn’t just about saving memory—it’s about keeping conversations coherent, responsive, and useful.
This guide breaks down what works, what doesn’t, and how to design chatbots that handle long, complex interactions without falling apart.
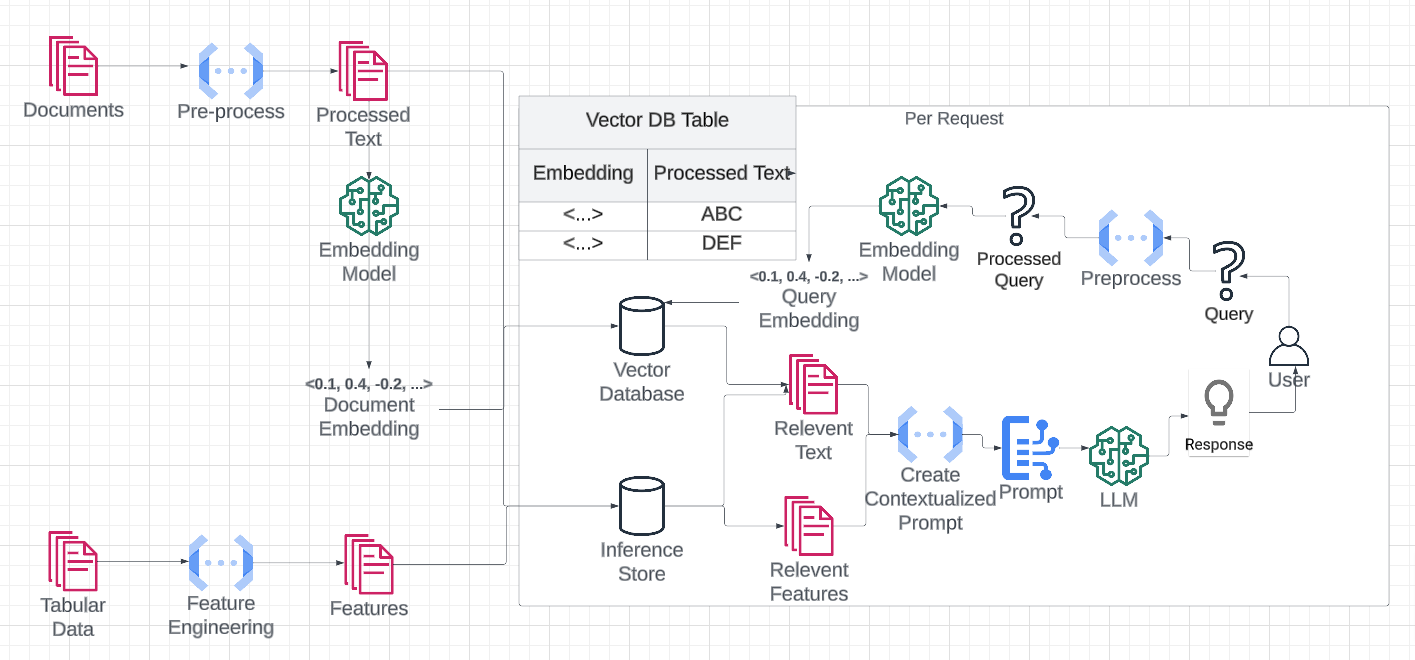
Understanding RAG Architecture
The seamless integration of retrieval and generation components is the cornerstone of effective RAG-based chatbots.
A critical yet often overlooked aspect is the alignment of retrieval outputs with the generative model’s input expectations.
This alignment ensures that the retrieved data is relevant and structured so that the generative model can process it effectively, minimizing the risk of incoherent or irrelevant responses.
One advanced technique involves leveraging semantic chunking during document preprocessing.
By segmenting documents into contextually meaningful units, retrieval precision improves significantly.
For instance, LangChain’s modular framework allows for dynamic chunking based on document structure, enhancing the retrieval model’s ability to fetch contextually rich snippets.
However, this approach requires careful calibration to avoid overloading the generative model with excessive or redundant information.
A notable challenge arises in domain-specific applications, where retrieval models must adapt to specialized terminologies.
Fine-tuning retrieval algorithms to prioritize domain-relevant content can bridge this gap, as demonstrated by NVIDIA’s implementation of agentic architectures for handling complex queries.
This underscores the importance of tailoring RAG pipelines to the unique demands of each use case, ensuring both accuracy and conversational fluidity.
Importance of Chat History Management
Effective chat history management hinges on contextual pruning, a technique that dynamically filters out irrelevant conversational data while preserving critical context.
This approach ensures that chatbots maintain clarity and precision, even in extended interactions.
Unlike static storage, which indiscriminately retains all exchanges, contextual pruning operates on a principle of selective retention, similar to editing a narrative for coherence.
This matters because retaining excessive history can overwhelm retrieval mechanisms, leading to slower response times and irrelevant outputs.
By contrast, pruning leverages metadata tagging and semantic analysis to rank conversational snippets by relevance.
For example, MyScale’s SQL-compatible memory system enables real-time pruning, ensuring only the most pertinent data is accessible during retrieval.
Balancing pruning thresholds is a nuanced challenge. Over-pruning risks losing essential context, while under-pruning invites noise. To address this, adaptive algorithms can adjust thresholds based on query complexity, as demonstrated by Galileo AI’s dynamic retrieval scaling.
This balance transforms chat history from a liability into a strategic asset, enhancing both accuracy and efficiency.
Core Techniques for Chat History Management
Managing chat history in RAG-based systems requires balancing essential context and avoiding information overload.
One pivotal technique is semantic chunking, which segments conversations into contextually meaningful units rather than arbitrary lengths. This approach ensures that retrieval systems prioritize coherence over volume.
For instance, tools like LangChain dynamically adjust chunk sizes based on conversational flow, enabling chatbots to maintain relevance even in extended interactions.
Another critical method is adaptive memory prioritization, which ranks stored data by relevance and recency.
Unlike static retention models, this technique dynamically updates memory buffers, ensuring that only the most pertinent information is accessible.
MyScale’s SQL-compatible memory system exemplifies this by integrating metadata tagging to streamline retrieval processes across multi-user environments.
A common misconception is that retaining more history improves performance. In reality, excessive data can dilute retrieval accuracy.
Techniques like contextual pruning counteract this by discarding redundant or outdated snippets, akin to decluttering a workspace for efficiency.
Together, these strategies transform chat history from a liability into a precision tool, enhancing both response accuracy and system scalability.
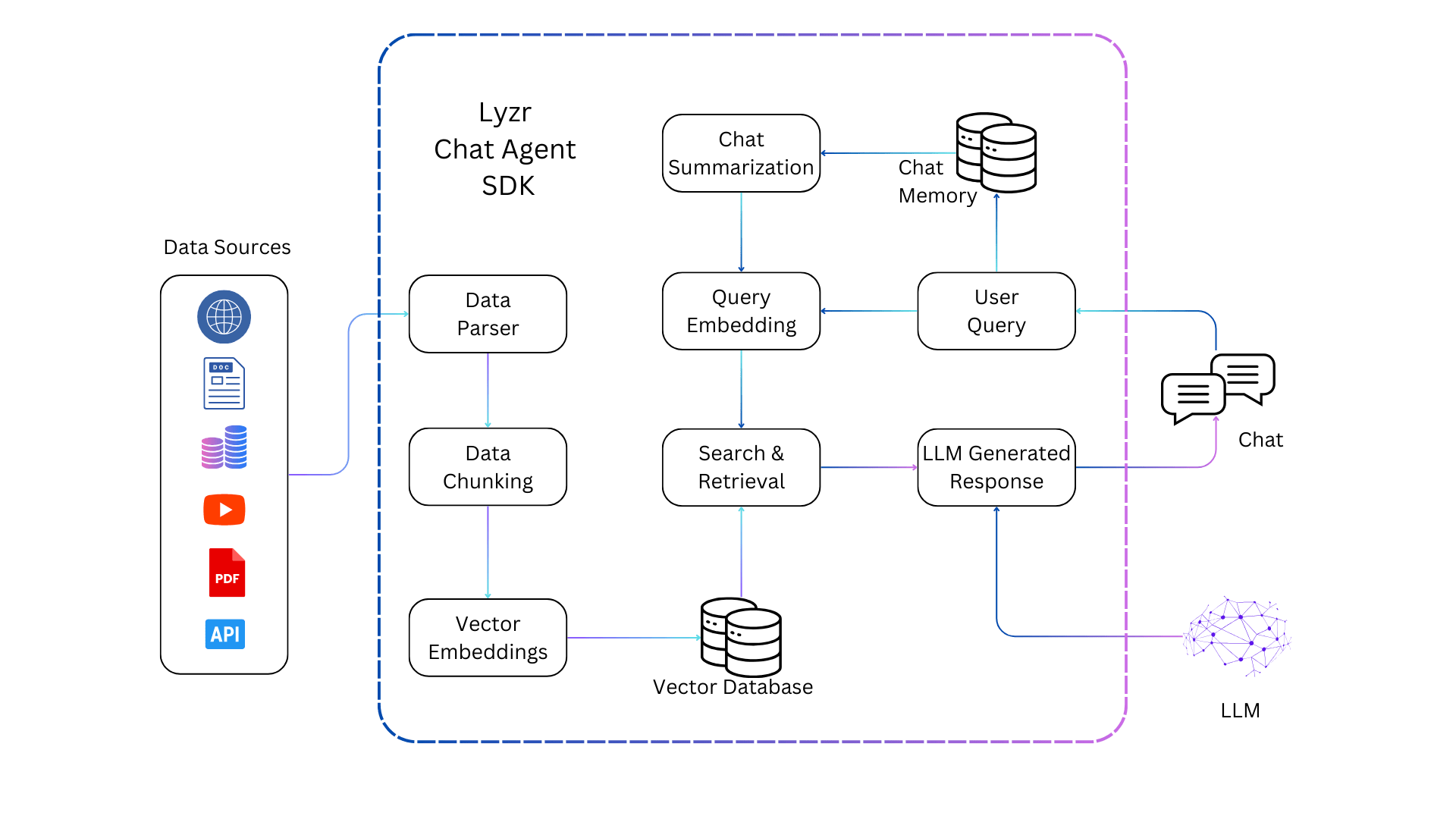
Chunking Methods: Fixed-Size vs. Semantic
Fixed-size chunking offers simplicity and predictability, dividing text into uniform segments based on token or character count.
This method is computationally efficient and straightforward to implement, making it ideal for scenarios where processing speed and consistency are paramount.
However, its rigidity often disrupts semantic coherence, as chunks may split mid-sentence or across related ideas, leading to fragmented context and diluted retrieval accuracy.
By contrast, semantic chunking prioritizes meaning over uniformity. It uses natural language processing (NLP) techniques, such as sentence embeddings or topic modeling, to identify logical boundaries within the text.
This approach ensures that each chunk encapsulates a cohesive idea, enhancing the relevance and depth of retrieved information.
While computationally intensive, semantic chunking excels in applications requiring nuanced understanding, such as legal or medical document analysis.
Balancing these methods is a critical challenge. Hybrid strategies, such as combining fixed-size chunking for efficiency with semantic adjustments for coherence, can mitigate their respective limitations.
For instance, dynamically resizing chunks based on query complexity ensures both scalability and contextual integrity, making this approach adaptable to diverse use cases.
Memory Management in RAG Systems
Dynamic memory curation is the linchpin of effective RAG systems. It ensures that only the most relevant conversational snippets are retained while extraneous data is discarded.
This approach mirrors the human tendency to prioritize recent and critical information, enabling chatbots to maintain contextual precision without succumbing to memory overload.
The process hinges on adaptive memory prioritization, where metadata tagging and semantic analysis rank stored data by relevance and recency.
Unlike static retention models, this method dynamically adjusts memory buffers, tailoring the retained context to the complexity of ongoing interactions.
For instance, in customer support, a chatbot might prioritize unresolved issues over completed queries, ensuring continuity in problem resolution.
However, this technique is not without challenges. Over-pruning risks losing essential context, while under-pruning invites noise.
A nuanced solution lies in context-aware algorithms that adapt pruning thresholds based on query complexity. Galileo AI’s implementation of dynamic retrieval scaling exemplifies this, balancing memory retention with retrieval efficiency.
By integrating these principles, RAG systems achieve a conversational flow that feels both natural and precise, enhancing user experience across diverse applications.
Advanced Context Preservation Strategies
Preserving context in RAG-based chatbots requires more than simply storing conversation history; it demands a dynamic interplay between memory optimization and retrieval precision.
One advanced approach involves hierarchical memory layering, where short-term and long-term memories are segmented and prioritized based on interaction relevance.
A critical misconception is that retaining all historical data enhances accuracy. In reality, excessive data often dilutes retrieval quality.
Techniques like contextual summarization, which condenses prior exchanges into semantically rich representations, address this issue.
Tools such as Pinecone integrate these summaries into vector embeddings, ensuring that only the most pertinent details inform subsequent responses.
Consider this as curating a museum exhibit: irrelevant artifacts are archived, while key pieces are prominently displayed to tell a cohesive story.
This method reduces computational overhead and enhances user satisfaction by maintaining conversational fluidity.
Ultimately, these strategies transform static memory into an adaptive framework, enabling chatbots to deliver precise, contextually aware interactions across diverse applications.
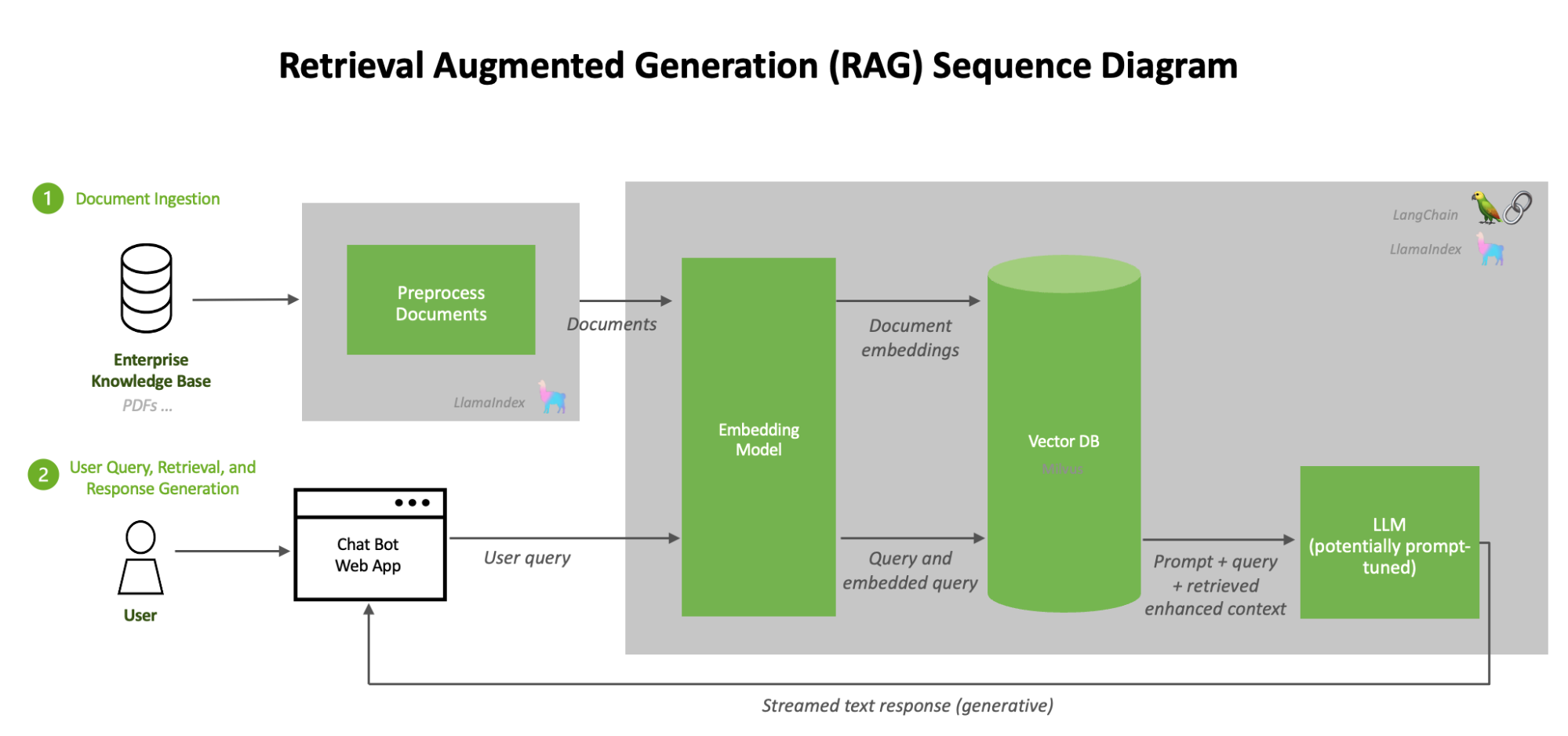
Implementing Context-Aware Retrieval
Context-aware retrieval thrives on the principle of dynamic relevance, where the system continuously evaluates and adapts to the evolving flow of a conversation.
This approach ensures that only the most pertinent snippets are retrieved, aligning seamlessly with the user’s intent.
Unlike static retrieval methods, which often fail to capture the fluidity of human dialogue, context-aware systems dynamically adjust retrieval parameters based on interaction history and query complexity.
One critical mechanism is dynamic reranking algorithms, prioritizing retrieved results by weighing factors such as semantic proximity, recency, and conversational intent.
For instance, Anthropic’s Contextual Retrieval system employs real-time embedding updates to mitigate contextual drift, ensuring that responses remain coherent even in multi-turn dialogues.
This adaptability is particularly valuable in scenarios like customer support, where user queries often evolve from specific issues to broader concerns.
However, implementing such systems is not without challenges. A notable limitation is balancing computational efficiency with retrieval depth.
Overly aggressive reranking can introduce latency, while insufficient adjustments risk irrelevant outputs.
Addressing this requires fine-tuning parameters like embedding refresh rates and reranking thresholds, tailored to the application’s domain and user expectations.
By treating retrieval as an adaptive process rather than a static function, organizations can achieve a nuanced interplay between precision and scalability, transforming user interactions into meaningful, contextually rich experiences.
Optimizing Response Generation
Dynamic context curation is pivotal for ensuring that response generation remains both accurate and contextually relevant.
By selectively condensing prior exchanges into semantically rich summaries, the system avoids the pitfalls of overloading the generative model with redundant or irrelevant data. This approach enhances computational efficiency and sharpens the model’s ability to produce coherent and meaningful responses.
One advanced technique involves adaptive summarization, where the context passed to the generation module is dynamically adjusted based on the complexity of the user’s query.
For instance, in high-stakes domains like healthcare, critical details—such as symptoms or prior recommendations—are preserved, while extraneous information is pruned.
Tools like Pinecone’s vector embeddings facilitate this by encoding summaries into compact, retrievable formats, enabling seamless integration with generative models.
However, challenges arise in balancing summarization granularity. Over-summarization risks omitting key nuances, while under-summarization can overwhelm the model. A practical solution lies in query-conditioned summarization, where the system tailors the level of detail to the user’s immediate needs.
LangStream successfully implemented this technique. Its adaptive pipelines demonstrated improved response coherence in customer support scenarios.
By refining how historical data informs generation, organizations can achieve a balance between depth and clarity, transforming user interactions into highly personalized experiences.
Balancing Context Retention and Information Overload
Striking the right balance between retaining context and avoiding information overload is like fine-tuning a symphony: Each element must contribute without overwhelming the whole.
Retaining excessive chat history can lead to retrieval inefficiencies, where irrelevant data dilutes response accuracy—conversely, overly aggressive pruning risks erasing critical context, leaving gaps in understanding.
A practical solution lies in dynamic memory layering, where short-term and long-term memories are segmented and prioritized.
For instance, short-term memory might focus on the last five exchanges, while long-term memory archives key insights from earlier interactions.
This approach mirrors human cognition, where immediate details are readily accessible, and foundational knowledge is stored for reference.
To further refine this process, contextual weighting algorithms assign relevance scores to conversational snippets based on recency, semantic importance, and user intent.
This ensures that only the most pertinent data informs the chatbot’s responses, maintaining both precision and fluidity.
The implications are profound: by mastering this balance, chatbots can deliver nuanced, contextually aware interactions that feel both natural and efficient.
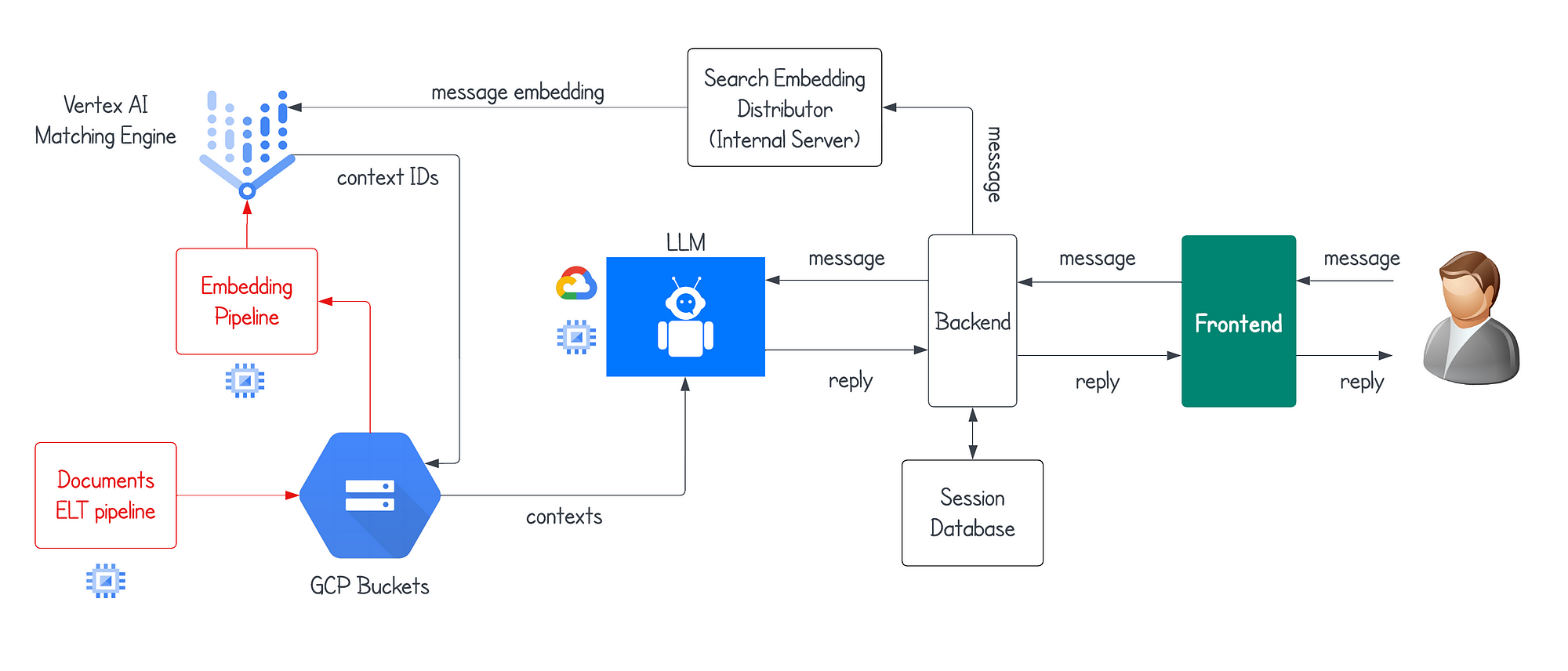
Trade-offs in Chat History Length
The length of chat history directly impacts a chatbot’s ability to deliver precise, contextually relevant responses.
Retaining too much history risks overwhelming retrieval systems with noise, while overly aggressive truncation can strip away critical context, particularly in multi-turn conversations.
The challenge lies in finding a balance that optimizes both relevance and efficiency.
One effective approach is query-conditioned truncation, where the chatbot dynamically adjusts the amount of retained history based on the complexity and specificity of the user’s query.
For example, a technical support bot might prioritize recent troubleshooting steps for a simple follow-up question but expand its memory scope for a more intricate diagnostic query.
This method ensures that the chatbot remains agile without sacrificing depth when it matters most.
However, implementation nuances can complicate this strategy.
For instance, domain-specific applications like healthcare require careful calibration to avoid discarding essential patient details.
Tools like LangStream’s adaptive pipelines address this by integrating semantic analysis to rank conversational snippets, ensuring that only the most relevant data is retained.
By tailoring memory retention to the context, developers can create responsive and contextually aware chatbots that enhance user satisfaction across diverse scenarios.
Techniques for Context Summarization
Effective context summarization hinges on adaptive semantic condensation, a technique that distills conversational history into its most relevant and actionable elements.
Unlike static summarization methods, this approach dynamically adjusts summaries' granularity based on the ongoing interaction's complexity.
Leveraging advanced natural language processing (NLP) models, adaptive semantic condensation ensures that critical nuances are preserved while extraneous details are pruned.
This method operates through a multi-step process.
First, semantic embeddings are generated to capture the contextual essence of each conversational snippet.
These embeddings are then ranked by relevance using recency, user intent, and query specificity metadata.
Finally, a summarization algorithm condenses the ranked data into a cohesive narrative, ensuring that the retained context aligns with the user’s immediate needs.
A notable advantage of this technique is its flexibility across domains.
For instance, it can prioritize case-specific precedents in legal applications, while it highlights unresolved issues in customer support.
However, challenges arise in balancing granularity; overly condensed summaries risk omitting critical details, while excessive retention can overwhelm the retrieval system.
By integrating adaptive semantic condensation, RAG systems achieve a balance between clarity and depth, transforming chat history into a strategic asset.
FAQ
What are the most effective techniques for handling long chat histories in RAG-based chatbots?
Effective techniques include semantic chunking, contextual pruning, memory layering, and summarization. These methods reduce noise, retain critical context, and ensure accurate responses in multi-turn conversations without overloading retrieval.
How does semantic chunking improve retrieval in long conversations?
Semantic chunking splits conversations into meaning-based segments. This preserves topic flow and improves retrieval precision, helping the chatbot understand related ideas and respond with relevant context during extended dialogues.
What is the purpose of contextual pruning in RAG systems?
Contextual pruning filters out irrelevant data by ranking interactions using metadata and relevance. This prevents memory overload and ensures the chatbot focuses only on the most useful context for accurate responses.
How does adaptive memory layering support multi-turn conversations?
Adaptive layering separates memory into short-term and long-term storage. Recent exchanges are kept for immediate context, while important earlier messages are stored for continuity, helping the chatbot stay coherent over many turns.
How can chatbots avoid information overload while preserving context?
Chatbots use memory layering, pruning, and summarization to avoid overload. These methods keep relevant data accessible while discarding noise, allowing RAG systems to stay efficient and provide accurate, context-aware answers.
Conclusion
Handling long chat histories in RAG-based chatbots requires careful memory control and retrieval tuning.
Systems maintain accuracy across multi-turn conversations by using techniques like semantic chunking, adaptive memory, and contextual pruning. These strategies ensure RAG-based chatbots remain scalable, responsive, and precise.