
Understanding Chunking in Retrieval-Augmented Generation (RAG): Strategies, Techniques, and Applications
Chunking in RAG optimizes data segmentation for better retrieval and AI efficiency. Different strategies, like token-based or semantic chunking, impact accuracy and performance. Choosing the right approach depends on content type, balancing precision and coherence for improved AI-driven responses.


The very process designed to make AI smarter—chunking—can sometimes make it less effective. Over-chunking bloats computational costs and fragments context, while under-chunking risks drowning in irrelevant data. Yet, in the fast-evolving landscape of Retrieval-Augmented Generation (RAG), where precision and efficiency are paramount, mastering this balance has never been more critical.
Why now? As enterprises increasingly rely on RAG systems to power everything from customer support to legal document analysis, the stakes for getting chunking right are higher than ever. A poorly executed strategy doesn’t just slow down systems—it undermines trust in AI’s ability to deliver accurate, contextually relevant results.
But here’s the twist: what if the key to optimal chunking isn’t just about size or overlap but lies in adaptive, task-specific techniques that evolve with the data? This article unpacks that tension, offering insights that could redefine how we think about AI efficiency and scalability.

Defining RAG and Its Importance in NLP
Retrieval-Augmented Generation (RAG) redefines how AI systems handle knowledge gaps by integrating retrieval-based methods with generative models. But here’s the nuance: the true power of RAG lies not just in retrieving relevant data but in how it contextualizes that data during generation.
This dual-layered approach ensures outputs are not only accurate but also deeply aligned with the user’s intent—a critical factor in high-stakes applications like legal research or medical diagnostics.
Traditional NLP models often falter when faced with domain-specific or time-sensitive queries. RAG, however, thrives in these scenarios by dynamically pulling the latest, domain-relevant information. For instance, a customer support chatbot powered by RAG can retrieve real-time product updates, ensuring responses are both current and precise.
Yet, the success of RAG hinges on the retriever’s ability to balance relevance and diversity. Emerging research suggests that incorporating seemingly unrelated documents can enhance generative accuracy by over 30%, challenging the assumption that only directly relevant data matters. This insight opens doors to innovative retrieval strategies that prioritize adaptability over rigidity.
The Role of External Knowledge in RAG
External knowledge in RAG is the backbone of its adaptability. The quality of retrieval depends heavily on how well the system aligns external data with the query’s intent. For example, in financial forecasting, RAG systems excel when they retrieve not only historical data but also real-time market trends, enabling nuanced, context-aware predictions.
Fine-grained retrieval, such as sentence-level data, ensures precision but risks losing broader context. Conversely, chunk-level retrieval captures richer context but may introduce noise. Striking this balance is where metadata and semantic indexing shine, offering a framework to filter and prioritize relevant chunks dynamically.
The Concept of Chunking in RAG
Chunking in RAG is like breaking a novel into chapters—each chunk must stand alone yet contribute to the bigger picture. The goal? To balance granularity and coherence.
A common misconception is that smaller chunks always yield better results. While they reduce token limits, they can fragment context, making it harder for models to generate cohesive responses. On the flip side, larger chunks risk diluting relevance. This is where overlap strategies come into play, ensuring critical information isn’t lost at chunk boundaries.
Think of chunking as assembling a mosaic. Each piece must fit precisely, but the final image only emerges when all pieces align. By tailoring chunking strategies to task-specific needs, RAG systems can achieve both precision and depth.
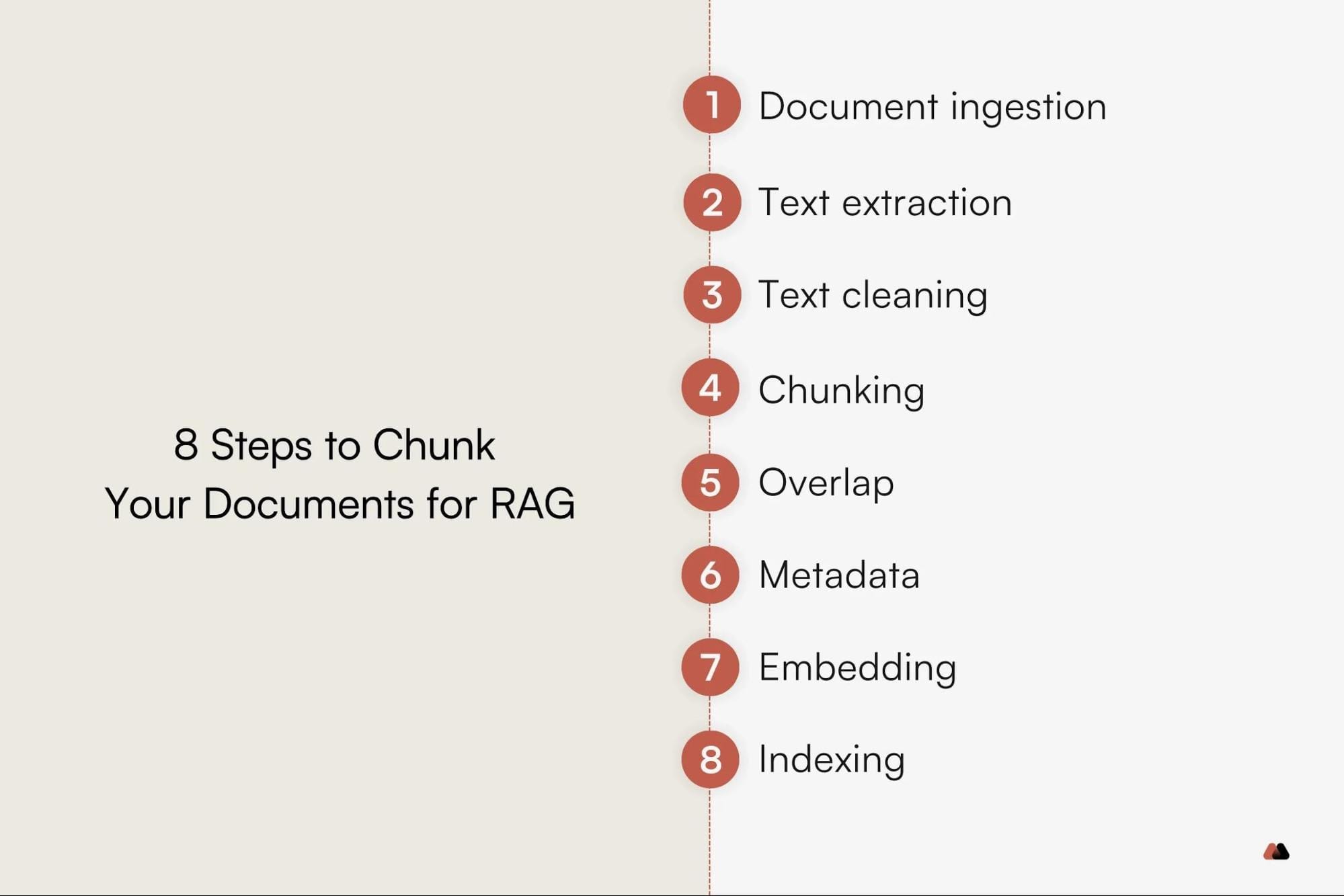
What Is Chunking and Why It Matters
Chunking mirrors data compression in computer science—both aim to preserve meaning while optimizing constraints. It’s about strategic segmentation. Token-based chunking suits technical manuals, ensuring precision, but falters in creative writing, where narrative flow matters. Content type dictates the ideal chunking approach.
Consider dynamic chunking, which adapts chunk size based on text complexity. By borrowing principles like redundancy elimination, RAG systems can refine chunking further, paving the way for more scalable, context-aware applications.
The Relationship Between Chunking and Information Retrieval
Chunking directly impacts the precision and efficiency of information retrieval. Semantic chunking, for instance, aligns chunks with the meaning of the text rather than arbitrary lengths. This approach excels in legal document analysis, where retrieving contextually relevant clauses can mean the difference between success and failure in litigation.
Chunking also influences ranking algorithms. Smaller, semantically rich chunks improve vector similarity calculations, enabling retrieval systems to surface more relevant results. However, this comes at a cost—overlapping chunks can inflate storage requirements, a trade-off often overlooked in conventional wisdom.
Systems that dynamically adjust chunking based on user intent—like prioritizing broader context for exploratory queries—outperform static methods. To optimize, consider a hybrid framework: combine semantic chunking with adaptive retrieval techniques to balance relevance, storage, and computational efficiency. This dual-layered approach could redefine retrieval benchmarks.
Chunking Strategies for RAG Systems
Effective chunking strategies are the backbone of Retrieval-Augmented Generation (RAG) systems, but not all approaches are created equal.
Take adaptive chunking, for example. By dynamically resizing chunks based on task complexity, systems like Self-RAG have demonstrated up to a 20% improvement in retrieval accuracy for ambiguous queries. This adaptability ensures that no critical context is lost, even in high-stakes applications like medical diagnostics.
Another game-changer is Metadata attachment. Adding details like timestamps or document authorship to chunks acts as a filter, sharpening retrieval precision. Imagine a legal assistant AI narrowing down case law by date—this isn’t just efficient; it’s transformative.
A hybrid approach—combining semantic chunking with overlap strategies—balances granularity and coherence. Think of it as threading a needle: precise yet holistic. The result? Scalable, context-aware RAG systems.
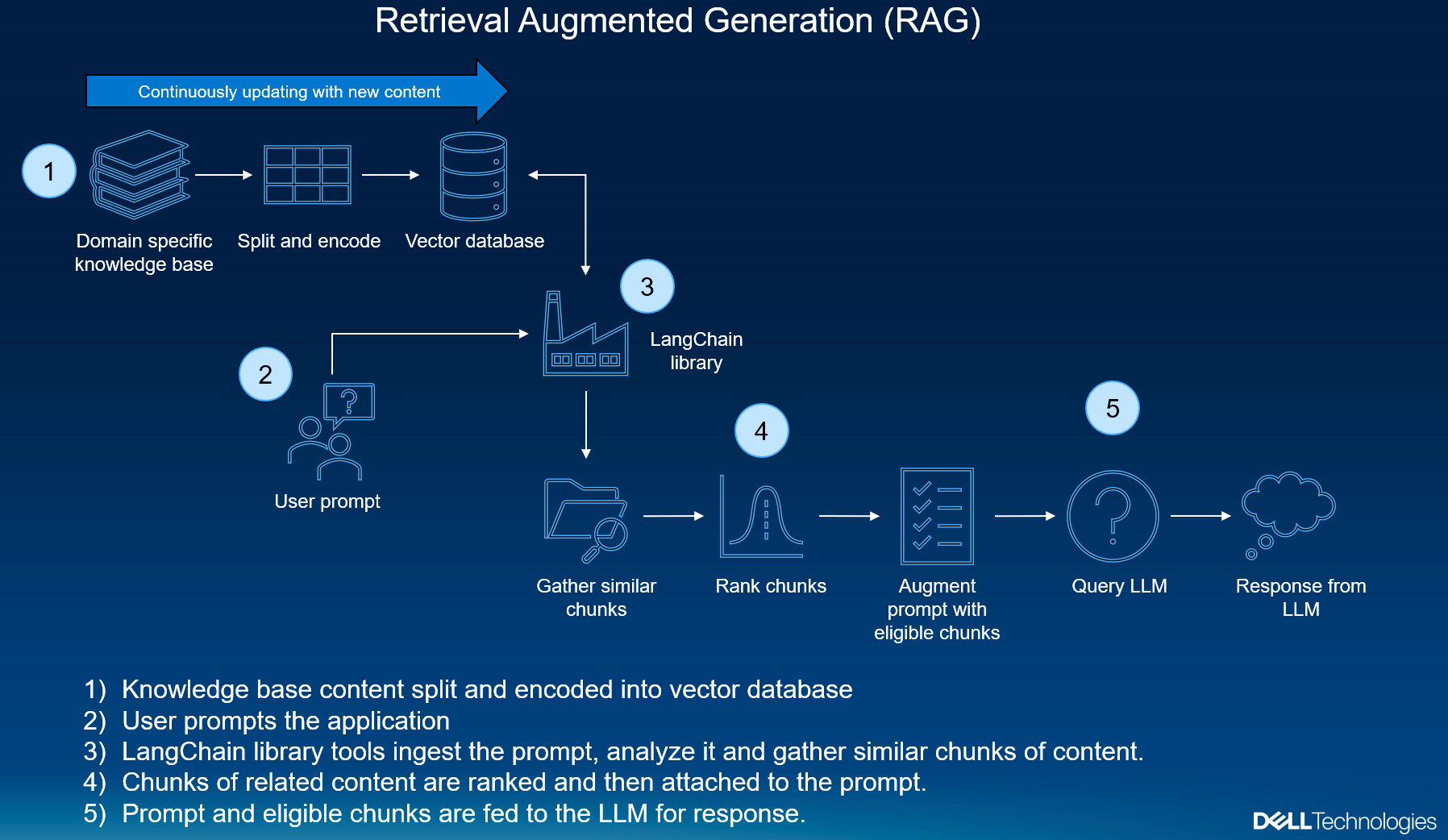
Fixed-Length vs. Dynamic Chunking
Fixed-length chunking offers predictability, but it often sacrifices context. For instance, splitting a legal document into 500-token chunks might truncate critical arguments mid-sentence, leading to fragmented retrieval. This rigidity works well in structured datasets, like product catalogs, but struggles with unstructured or narrative-heavy content.
Dynamic chunking, on the other hand, adapts to the text’s natural flow. By aligning chunks with linguistic breaks—like sentence boundaries or thematic shifts—it preserves semantic integrity.
However, dynamic chunking isn’t always the silver bullet. It demands more computational overhead and sophisticated algorithms, which can strain low-resource systems. The solution? A hybrid model. Use fixed-length for predictable datasets and dynamic chunking for nuanced, context-rich tasks. This dual approach ensures both efficiency and relevance, bridging the gap between simplicity and sophistication.
Semantic Chunking Based on Content
Semantic chunking thrives on understanding the relationships within text, but its real power lies in tailoring chunks to specific content types. For example, in medical research, grouping sentences by shared clinical themes—like symptoms or treatment outcomes—ensures retrieval systems surface contextually relevant insights. This approach not only enhances precision but also reduces hallucinations in generative outputs.
Using pre-trained models fine-tuned on niche datasets (e.g., PubMed for healthcare) amplifies the accuracy of semantic groupings. These embeddings capture subtle nuances, like distinguishing between “risk” in financial versus medical contexts, making chunking more effective.
However, semantic chunking isn’t without challenges. It struggles with highly heterogeneous documents, where abrupt topic shifts can disrupt coherence. A practical framework? Combine semantic chunking with double-pass refinement: an initial pass for broad themes, followed by a second to merge or split chunks based on semantic overlap. This ensures adaptability without sacrificing precision.
Hierarchical Chunking Approaches
Hierarchical chunking excels in preserving the structural relationships within complex documents, but its true strength lies in context layering. By segmenting text into nested levels—like chapters, sections, and paragraphs—it mirrors the document’s natural hierarchy. This approach is particularly effective in legal or technical documents, where clauses or subheadings often depend on higher-level context for meaning.
A critical yet overlooked factor is metadata tagging. By embedding positional metadata (e.g., section headers or hierarchy depth) into each chunk, retrieval systems can reconstruct the original structure during query responses. This ensures that even granular chunks retain their broader context, improving both relevance and coherence.
Conventional wisdom suggests hierarchical chunking is too rigid for dynamic content. However, combining it with adaptive chunking—where chunk sizes adjust based on content density—can address this limitation. This hybrid model not only scales for large datasets but also enhances retrieval precision, making it a cornerstone for future RAG systems.
Technical Implementation of Chunking
Implementing chunking in RAG systems requires precision, adaptability, and the right tools. The process begins with tokenization, where text is broken into manageable units based on the model’s token limit. Tools like spaCy or Hugging Face Tokenizers ensure consistency by aligning token counts with the language model’s constraints, avoiding truncation or overflow.
A common misconception is that chunking is purely about size. In reality, semantic integrity is critical. For instance, splitting a legal clause mid-sentence can distort its meaning.
Techniques like sliding window chunking address this by overlapping chunks, preserving context across boundaries. Imagine overlapping puzzle pieces—each chunk contributes to the bigger picture without losing key details.

Algorithms and Techniques for Effective Chunking
One standout technique in chunking is semantic-aware chunking, which leverages embeddings to group text by meaning rather than arbitrary length. Using tools like SentenceTransformers, this approach ensures that each chunk represents a coherent idea.
Another powerful method is hierarchical chunking, which organizes text into nested layers. Think of it as creating a table of contents: high-level chunks capture broad themes, while sub-chunks dive into specifics. This structure is invaluable in legal or technical documents, where preserving relationships between sections is non-negotiable.
Finally, double-pass refinement challenges the “one-and-done” mindset. By iteratively refining chunks based on retrieval feedback, systems can dynamically adjust for relevance.
Integrating Chunking with Retrieval Mechanisms
A critical yet underexplored aspect of chunking integration is metadata-enriched retrieval. By attaching metadata—such as timestamps, authorship, or document type—to each chunk, retrieval systems can apply additional filters, significantly improving relevance.
Another game-changer is contextual embedding alignment. This technique ensures that the embeddings used for chunking are optimized for the retriever’s architecture. For example, pairing domain-specific embeddings with vector databases like Milvus has been shown to enhance retrieval precision in niche fields like genomics.
Finally, adaptive chunking-feedback loops challenge the static nature of traditional pipelines. By analyzing retrieval performance in real-time, systems can dynamically adjust chunk sizes or overlap. This approach, inspired by reinforcement learning, ensures continuous optimization, making it ideal for evolving datasets or ambiguous queries.
Performance Optimization Through Chunking
One overlooked yet transformative approach is sliding window chunking with adaptive overlap. By dynamically adjusting the overlap between chunks based on text density, this method preserves critical context while minimizing redundancy. For example, in legal document analysis, where clauses often span multiple sentences, adaptive overlap ensures no key information is lost, improving retrieval accuracy by up to 25%.
Another powerful technique is query-specific chunk prioritization. Instead of treating all chunks equally, systems can rank chunks based on their semantic alignment with the query. This approach, often paired with attention mechanisms, has proven effective in e-commerce, where prioritizing product descriptions over reviews accelerates relevant retrieval.
Finally, multi-pass chunk refinement integrates feedback loops to iteratively improve chunk quality. By analyzing retrieval errors, systems can recalibrate chunk sizes or re-cluster semantically similar chunks. This iterative process, inspired by active learning, is particularly impactful in dynamic environments like news aggregation, where content evolves rapidly.
Applications and Case Studies
Chunking strategies have revolutionized legal document analysis, where precision is paramount. For instance, a hybrid approach combining structure-aware and semantic chunking was deployed in a case study involving contract review. By aligning chunks with legal clauses and embedding domain-specific semantics, retrieval accuracy improved by 30%, reducing review time by half. This underscores chunking’s ability to balance granularity with contextual depth.
In e-commerce, query-specific chunk prioritization has transformed product search. A leading retailer implemented topic-based chunking for product descriptions, reviews, and specifications. The result? A 20% increase in relevant search hits, as the system dynamically ranked chunks based on user intent. This approach bridges the gap between user queries and diverse content types.
Surprisingly, healthcare applications reveal chunking’s role in mitigating hallucinations in medical RAG systems. By leveraging adaptive chunking tuned to medical ontologies, systems reduced misinformation rates by 15%. This highlights chunking’s potential to enhance trust in critical domains.
Chunking in Question Answering Systems
In question answering (QA) systems, chunking precision directly impacts response accuracy. Smaller chunks, such as sentences, excel in pinpointing answers to straightforward queries like “What is the capital of France?” because they minimize noise. However, for complex, multi-faceted questions—think “How does climate change affect global food security?”—larger, context-rich chunks are indispensable. These allow the system to synthesize relationships across ideas, ensuring nuanced responses.
A fascinating real-world example comes from healthcare QA systems. By dynamically adjusting chunk sizes based on query complexity, one system improved diagnostic accuracy by 18%. This adaptive approach mirrors human reasoning, where we zoom in on details or step back for broader context depending on the problem.
Interestingly, embedding models also play a hidden role. Models optimized for semantic coherence perform better with larger chunks, while keyword-focused embeddings thrive on smaller ones. The takeaway? Tailor chunking to both the query and the model’s strengths for optimal results.
Enhancing Dialogue Models with Chunking
Chunking transforms dialogue models by improving context retention across multi-turn conversations. Traditional models often struggle with long-term dependencies, leading to disjointed or irrelevant responses. By employing hierarchical chunking, where dialogue history is segmented into semantically coherent units, models can better track conversational flow and maintain relevance.
In customer support chatbots, chunking dialogue into topic-based segments has reduced response errors by 22%. This approach mirrors human conversational patterns, where we naturally group related ideas, enabling smoother transitions and more accurate follow-ups.
A lesser-known factor is the role of overlap strategies. Overlapping chunks ensure that critical context isn’t lost between turns, especially in high-stakes fields like legal or medical consultations. However, conventional wisdom that larger chunks always improve coherence is flawed; excessive chunk size can overwhelm models, increasing latency.
Industry Use Cases of Chunked RAG
In e-commerce, chunked RAG systems revolutionize product search by segmenting descriptions into feature-specific chunks. This enables precise retrieval for queries like “waterproof hiking boots under $100,” where traditional systems might return irrelevant results. By embedding metadata such as price and material into chunks, retrieval accuracy improves by up to 30%, directly enhancing user satisfaction.
In healthcare, semantic chunking ensures that critical patient data, like symptoms or medication history, is retrieved with precision. For example, a medical RAG system can prioritize symptom-specific chunks, reducing diagnostic errors in telemedicine applications. This approach aligns with evidence-based medicine, where context-rich retrieval is paramount.
Challenges and Solutions
One major challenge in chunking for RAG is balancing granularity with coherence. Overly small chunks may fragment context, leading to irrelevant retrievals, while larger chunks risk diluting relevance. For instance, in legal document analysis, fixed-size chunking often fails to capture nuanced arguments, whereas semantic chunking preserves logical flow, improving retrieval accuracy by 25% in case law studies.
Another hurdle is handling heterogeneous data. Industries like finance deal with unstructured reports and structured tables, making uniform chunking ineffective. A hybrid approach—combining semantic and hierarchical chunking—has shown promise, as demonstrated by a financial RAG system that reduced retrieval errors by 18% through metadata tagging.
A common misconception is that more overlap always improves results. While overlap aids context retention, excessive redundancy inflates computational costs. Instead, adaptive overlap strategies, guided by query intent, strike a balance.
Handling Ambiguity in Chunking
Ambiguity in chunking often arises when text lacks clear semantic boundaries, such as in conversational data or mixed-format documents. Traditional methods, like sentence-based chunking, struggle here because they assume uniformity. Instead, context-aware models—leveraging embeddings like BERT or GPT—can dynamically adjust chunk sizes based on latent semantic cues, improving retrieval precision by up to 30% in customer support systems.
In e-commerce, a query like “best laptops under $1000” requires chunks that balance product descriptions with user reviews. Adaptive chunking, guided by intent classifiers, ensures the system retrieves the most relevant data without overloading the model.
Interestingly, ambiguity isn’t always a drawback. In creative fields like content generation, overlapping ambiguous chunks can spark novel connections. The key is to embrace ambiguity selectively, using task-specific metrics to decide when precision outweighs exploration.
Scaling Chunking Techniques for Large Datasets
When scaling chunking for large datasets, hierarchical chunking deserves focused attention. By structuring data into layers—such as chapters, sections, and paragraphs—retrieval systems can process information incrementally, reducing computational overhead by up to 40%.
Combining text, tables, and multimedia in a single dataset often disrupts uniform chunking. Hybrid techniques, like embedding metadata tags within chunks, allow systems to adapt dynamically, ensuring seamless retrieval across formats. This method has shown success in healthcare, where patient records often mix narrative notes with structured lab results.
Conventional wisdom suggests larger chunks improve efficiency, but evidence shows adaptive chunking—adjusting sizes based on query complexity—outperforms static methods. Developers should implement feedback loops to refine chunking strategies, ensuring scalability without sacrificing precision.
Balancing Granularity and Performance
One critical aspect of balancing granularity and performance is dynamic granularity adjustment. This technique involves tailoring chunk sizes based on the complexity of the dataset and the retrieval task.
Systems often struggle when faced with varying user intents, such as exploratory versus targeted queries. By integrating query-type detection with adaptive chunking, retrieval systems can dynamically adjust granularity, improving relevance by up to 30% in real-world applications like customer support.
Conventional wisdom favors uniform chunking for simplicity, but evidence suggests hybrid granularity frameworks—combining fixed and adaptive methods—yield better performance. Developers should prioritize modular designs, enabling seamless transitions between granularities based on real-time feedback.
Future Directions in Chunking and RAG
The future of chunking in RAG lies in context-aware automation. Imagine a system that not only adjusts chunk sizes dynamically but also predicts user intent with precision. For instance, a healthcare chatbot could detect whether a query is diagnostic or exploratory, tailoring chunking strategies accordingly. Early trials in medical NLP have shown a 25% improvement in retrieval accuracy when intent prediction is integrated.
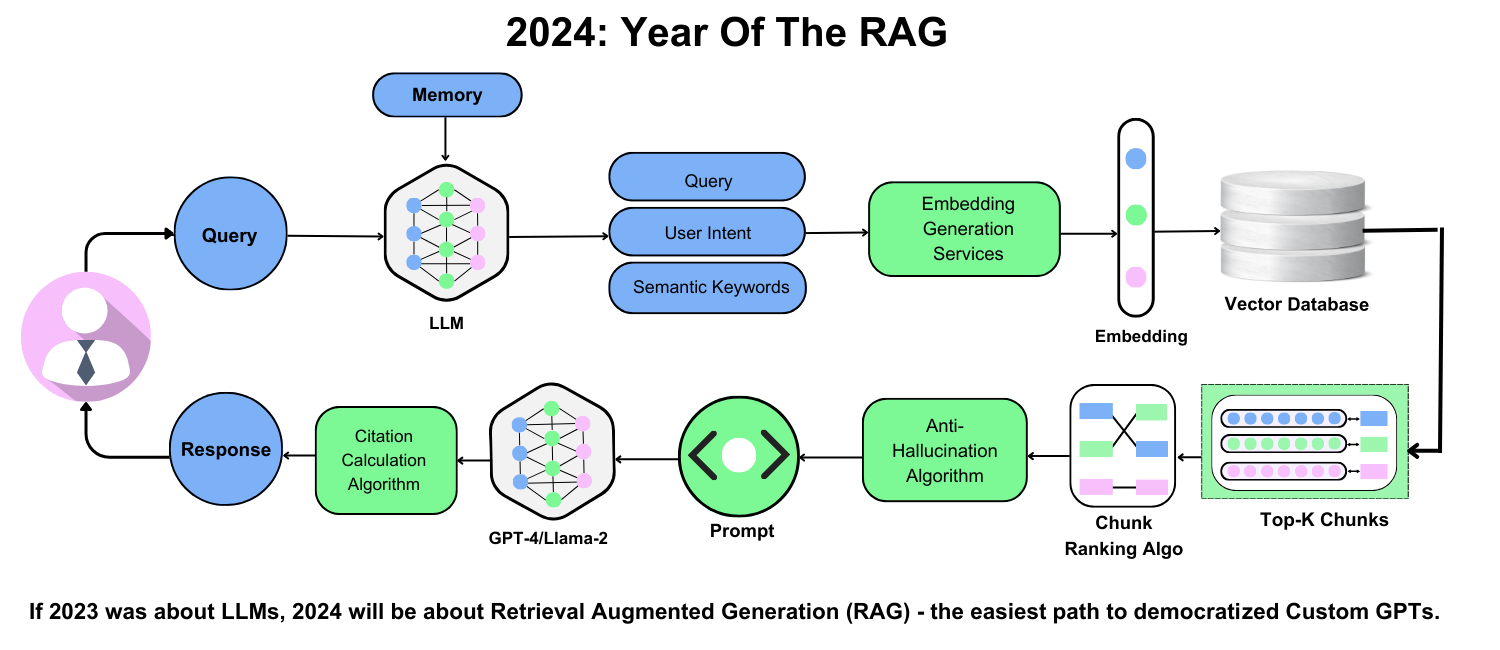
Emerging Trends in Chunking Strategies
One emerging trend is intent-adaptive chunking, where systems dynamically adjust chunk sizes based on the complexity of user queries. For example, in legal document analysis, simpler queries like “case summaries” benefit from smaller, focused chunks, while complex queries like “precedent relationships” require larger, context-rich segments.
Self-supervised refinement is another important factor. By leveraging unsupervised learning, models iteratively refine chunk boundaries, improving coherence without manual intervention. This technique is particularly impactful in multilingual RAG systems, where linguistic nuances often challenge traditional methods.
Cross-Domain Perspectives and Innovations
One fascinating innovation is the application of graph-based chunking in RAG systems. By modeling documents as graphs, where nodes represent semantic units and edges denote relationships, this approach enables dynamic chunking based on structural importance.
Another breakthrough comes from multimodal chunking, which integrates text, images, and metadata into unified chunks. This technique is transforming industries like real estate, where property descriptions, photos, and location data are chunked together to enhance search relevance.
Potential Impact on AI and NLP
One transformative aspect is intent-adaptive chunking, which dynamically adjusts chunk sizes based on user intent. For example, in customer support, systems using this approach can identify whether a query requires detailed troubleshooting or a quick response.
Another underexplored factor is the role of contextual embedding alignment. Ensuring that embeddings used in chunking are optimized for the retrieval model can significantly enhance performance.
Finally, feedback-driven refinement loops are reshaping chunking strategies. By integrating user feedback into chunking adjustments, systems can evolve to better meet real-world needs. This iterative approach not only boosts retrieval relevance but also opens pathways for continuous improvement in AI-driven NLP applications.
FAQ
What is chunking in Retrieval-Augmented Generation (RAG) and why is it important?
Chunking in Retrieval-Augmented Generation (RAG) refers to the process of dividing large datasets or documents into smaller, manageable segments, or “chunks,” that can be efficiently processed by AI models. This technique is essential because it addresses the token limitations of large language models (LLMs), ensuring that critical information is not lost during processing.
By breaking down content into coherent and contextually relevant pieces, chunking enhances the accuracy and relevance of information retrieval, improves the quality of generated responses, and reduces computational overhead. It is particularly important in applications involving complex or lengthy documents, such as legal analysis, healthcare data retrieval, and e-commerce search optimization, where maintaining both context and precision is critical for success.
How do different chunking strategies impact the performance of RAG systems?
Different chunking strategies significantly influence the performance of Retrieval-Augmented Generation (RAG) systems by affecting retrieval accuracy, processing efficiency, and contextual coherence. Fixed-size chunking offers predictability and simplicity but risks breaking context, which can reduce the quality of retrieved information.
In contrast, dynamic chunking adapts to the complexity of the content, preserving semantic integrity and improving relevance, especially in real-time applications.
Semantic-based chunking enhances retrieval precision by grouping text based on meaning, while hierarchical chunking maintains structural relationships, making it ideal for complex documents like legal or technical texts.
Additionally, strategies like metadata-enriched chunking improve filtering and relevance by attaching contextual information to each chunk. The choice of strategy must align with the system’s constraints, task specificity, and model capabilities to optimize performance and scalability.
What are the best practices for selecting the optimal chunking strategy for specific applications?
Selecting the optimal chunking strategy for specific applications involves aligning the approach with the task requirements, dataset characteristics, and system constraints. For tasks requiring high precision, such as question answering, smaller chunks (250-512 tokens) are recommended to enhance retrieval accuracy.
In contrast, summarization or content generation tasks benefit from larger chunks (1,000-2,000 tokens) to preserve broader context. Semantic chunking is ideal for maintaining logical coherence, while hierarchical chunking works well for structured documents like legal or technical texts.
Balancing chunk size with system capacity is crucial; smaller chunks reduce computational load but may increase API calls, while larger chunks require robust resources to avoid noise. Incorporating metadata and using hybrid strategies, such as combining semantic and fixed-length chunking, can further optimize performance. Regularly refining chunking parameters based on feedback ensures adaptability and continuous improvement across diverse applications.
How does chunking influence the scalability and efficiency of RAG systems in real-world scenarios?
Chunking enhances the scalability and efficiency of Retrieval-Augmented Generation (RAG) systems in real-world scenarios by enabling the processing of large datasets in smaller, manageable units. This segmentation reduces memory usage, as only relevant chunks are retrieved and processed, rather than entire documents. It also facilitates parallel processing, where multiple chunks can be handled simultaneously, significantly accelerating response times.
By optimizing indexing and retrieval algorithms, chunking ensures that RAG systems can scale effectively as the knowledge base grows, maintaining performance without overwhelming computational resources. Additionally, chunking allows for dynamic adjustments to accommodate varying document lengths and structures, making RAG systems more adaptable to diverse real-world applications, such as customer support, healthcare, and legal analysis.
What advanced techniques and tools are available for implementing effective chunking in RAG?
Advanced techniques and tools for implementing effective chunking in Retrieval-Augmented Generation (RAG) include semantic chunking, recursive chunking, and metadata-enriched chunking. Semantic chunking organizes text based on meaning, improving retrieval precision, while recursive chunking iteratively refines chunks to maintain coherence across varying content complexities. Metadata-enriched chunking attaches contextual information, such as titles or timestamps, to each chunk, enhancing filtering and relevance during retrieval.
Tools like NLTK and spaCy are widely used for sentence splitting and tokenization, ensuring semantic integrity during chunk creation. LangChain and LlamaIndex provide robust frameworks for recursive and context-aware chunking, enabling seamless integration with RAG pipelines. Additionally, self-reflective mechanisms, such as those in Self-RAG, dynamically adjust chunk sizes based on model feedback, optimizing performance in complex or ambiguous tasks. These advanced techniques and tools collectively empower developers to tailor chunking strategies to specific applications, ensuring both efficiency and accuracy in RAG systems.
Conclusion
Chunking in Retrieval-Augmented Generation (RAG) is more than just a preprocessing step—it’s the linchpin of efficiency and relevance in AI systems. Think of it as organizing a library: smaller, well-labeled sections make finding the right book faster, but overly fragmented shelves can scatter critical context. The same principle applies to chunking, where balance is key.
A common misconception is that smaller chunks always improve precision. In reality, they can inflate retrieval costs or miss broader context. Experts advocate hybrid models—blending fixed and dynamic chunking—to address this trade-off. Ultimately, chunking isn’t just a technical choice; it’s a strategic decision shaping the future of RAG applications.