
Handling Retrieval Inconsistency After Vector Database Updates
Vector DB updates can lead to retrieval inconsistencies in RAG systems. This guide explores common causes, troubleshooting methods, and best practices to maintain accuracy, stability, and performance after database modifications or re-indexing.


You update your vector database—just a small batch of new embeddings—and suddenly, your search results start acting strange. What used to rank well now surfaces irrelevant items.
The problem?
Retrieval inconsistency after vector database updates. It’s subtle, hard to detect, and surprisingly common.
Modern vector databases are fast and scalable, but even minor changes can ripple through your index and throw off similarity search. When embeddings shift or the index lags behind, the system loses context.
For applications like recommendation engines or semantic search, that’s not a minor glitch—it’s a risk to core functionality.
In this article, we’ll explore what causes retrieval inconsistency after vector database updates, how it affects real-time systems, and what you can do to fix it without rebuilding everything from scratch.
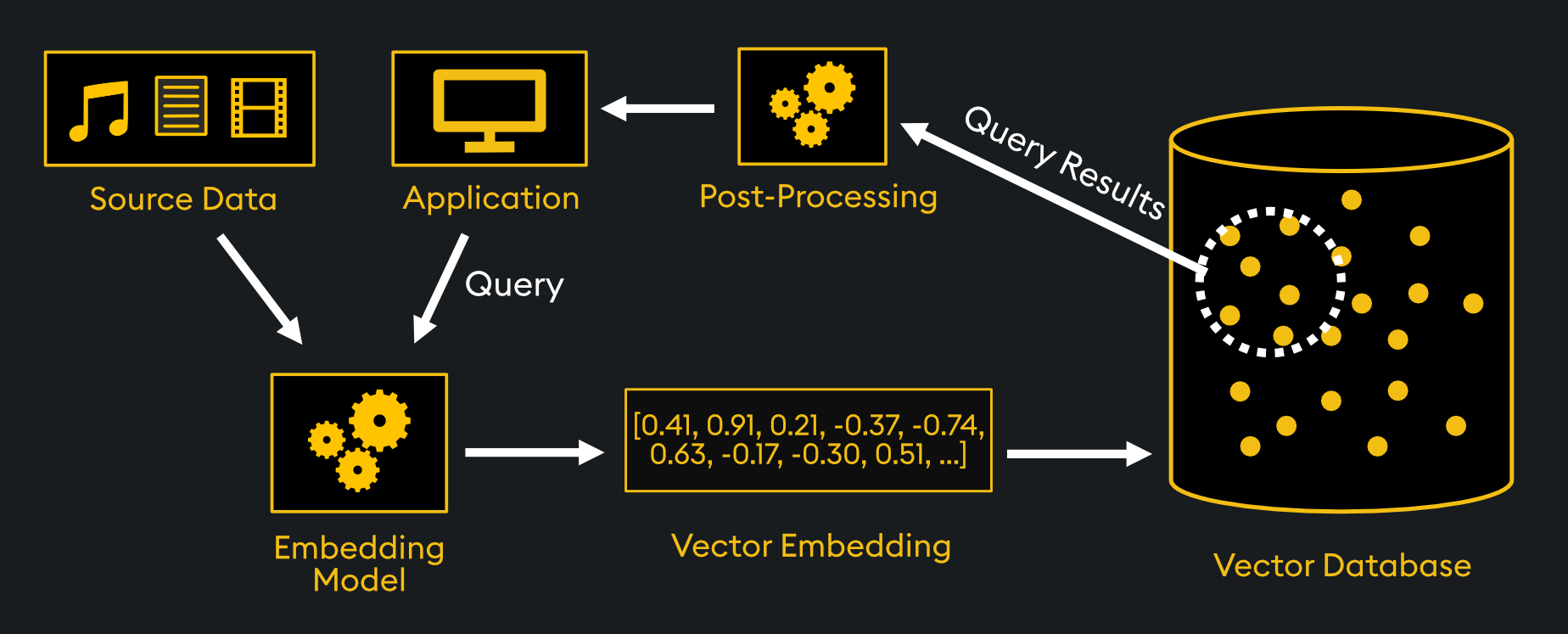
Basics of Vector Representation and Similarity Metrics
The foundation of vector representation lies in its ability to encode complex, unstructured data into high-dimensional numerical forms, enabling meaningful comparisons.
A critical yet underexplored aspect is the role of dimensionality reduction techniques, such as Principal Component Analysis (PCA), in optimizing vector embeddings. By reducing noise and preserving essential features, these methods enhance both retrieval accuracy and computational efficiency.
However, the choice of similarity metric—be it cosine similarity, Euclidean distance, or dot product—introduces nuanced trade-offs.
For instance, while cosine similarity excels in text-based applications by focusing on vector direction, it may falter in scenarios where magnitude carries significance, such as image retrieval. This interplay between metric selection and data characteristics often determines the success of a system.
An overlooked challenge is the impact of embedding drift, where updates to vector representations disrupt established relationships.
Addressing this requires dynamic recalibration of similarity metrics, a practice still evolving in real-world implementations.
These complexities underscore the need for a holistic approach that integrates theoretical rigor with adaptive methodologies.
Common Challenges in Vector Database Management
One critical challenge in vector database management is addressing the synchronization gap between vector updates and index consistency.
This issue becomes particularly pronounced in dynamic systems where data evolves rapidly, such as real-time recommendation engines or semantic search platforms.
The underlying problem lies in the misalignment between updated vector embeddings and static indexing structures, which can degrade retrieval accuracy and system reliability.
To mitigate this, incremental indexing techniques are often employed.
These methods aim to update only the affected portions of the index rather than rebuilding it entirely.
However, this approach introduces its own complexities, such as fragmented indices and increased query latency over time.
A comparative analysis reveals that while delta indexing minimizes downtime, it struggles with long-term performance degradation, whereas full reindexing ensures consistency but at the cost of significant computational overhead.
Contextual factors, such as the frequency of data updates and the dimensionality of the vectors, further influence the effectiveness of these strategies.
For instance, high-dimensional datasets exacerbate the “curse of dimensionality,” making even minor inconsistencies more impactful.
A promising solution involves hybrid approaches that combine incremental updates with periodic full reindexing, balancing consistency and performance.
By integrating rollback mechanisms and version control, organizations can better manage the inherent trade-offs, ensuring robust and scalable vector database systems.
Mechanisms of Vector Database Updates
Updating a vector database is not merely a technical operation; it is a balancing act that directly impacts retrieval accuracy, system performance, and long-term scalability.
At its core, the process involves reconciling the need for immediate data visibility with the structural integrity of indexing systems.
This tension is particularly evident in high-frequency update scenarios, such as e-commerce platforms where new product vectors must appear in search results instantly.
The choice of update mechanism often hinges on the indexing algorithm.
For instance, Hierarchical Navigable Small World (HNSW) graphs excel at handling incremental updates due to their dynamic node insertion capabilities, but they demand significant memory overhead.
In contrast, Inverted File (IVF) indexes require periodic retraining to adapt to shifting data distributions, introducing latency during reindexing. These trade-offs underscore the importance of aligning update strategies with application-specific requirements.
A counterintuitive insight is that hybrid approaches—combining in-memory caching for rapid updates with disk-based storage for persistence—can mitigate performance bottlenecks.
For example, a social media platform might cache recent user-generated vectors in memory for instant retrieval while batching older data to disk. This dual-layer strategy ensures both speed and durability.
Ultimately, the implications of update mechanisms extend beyond technical efficiency. They shape user experiences, influence system reliability, and determine the scalability of vector databases in dynamic environments.
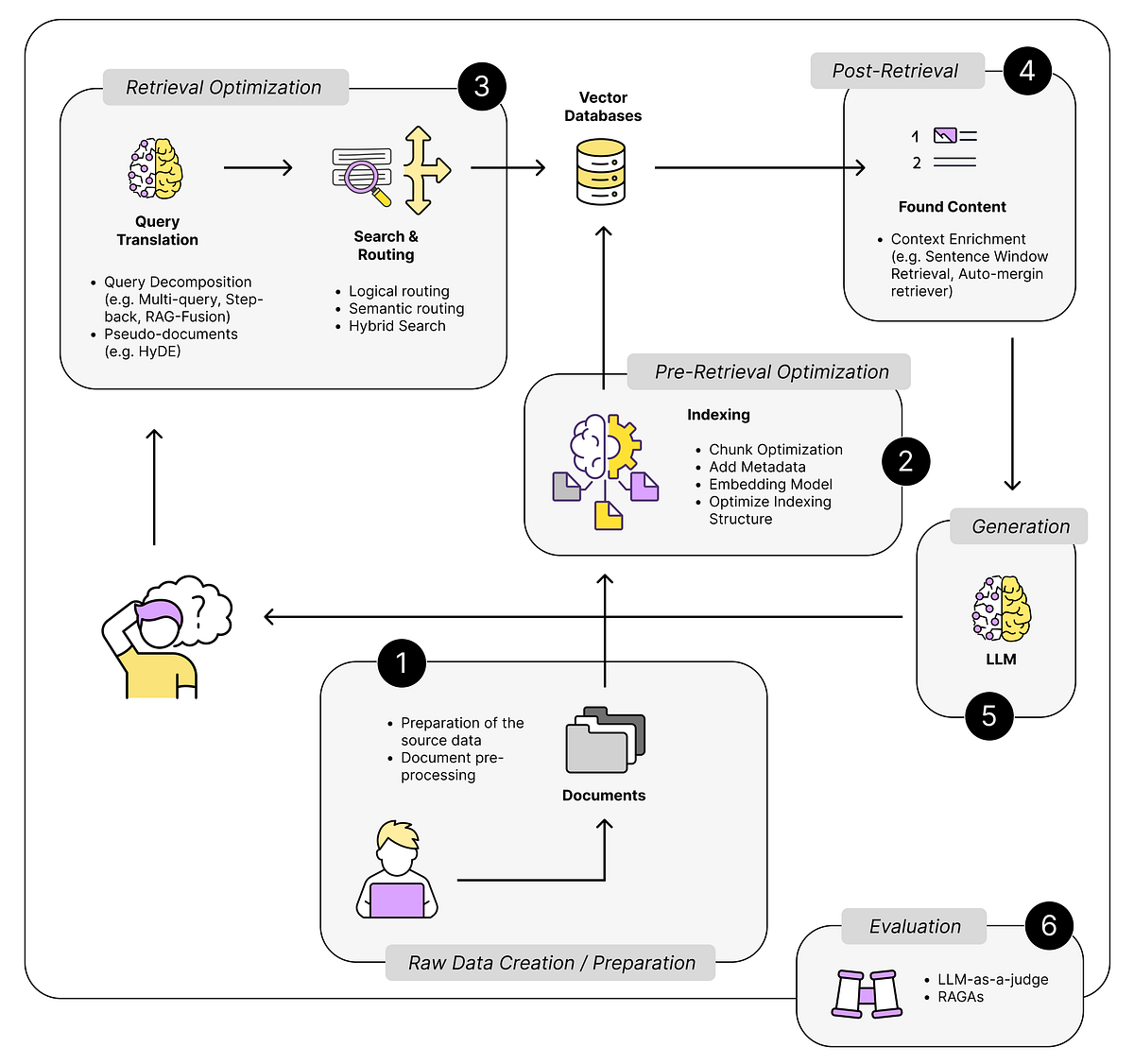
Update Operations: Adding, Modifying, and Deleting Vectors
Adding vectors to a database may seem routine, but the challenge lies in ensuring seamless integration with existing indices.
Each new vector alters the spatial distribution, potentially disrupting the balance of similarity searches.
Techniques like lazy index updates, which delay reindexing to batch operations, can mitigate immediate performance hits but risk temporary inconsistencies.
Modifying vectors introduces even greater complexity.
Adjusting a vector’s embedding effectively repositions it within the high-dimensional space, necessitating recalibration of its relationships with neighboring vectors. Retrieval accuracy can degrade without precise synchronization between the updated vector and its metadata.
Advanced indexing algorithms, such as dynamic HNSW, address this by recalculating affected connections in real time, albeit at a computational cost.
While seemingly straightforward, deleting vectors often leaves residual gaps in the index. These “holes” can fragment the structure, leading to inefficiencies in similarity searches.
Periodic index compaction routines, which reorganize and rebalance the index, are critical to maintaining system integrity. However, these processes must be carefully timed to avoid disrupting active queries.
Ultimately, effective update operations demand a balance between immediate responsiveness and long-term structural coherence, ensuring both performance and reliability in dynamic environments.
Impact of Updates on Index Structures
When updates occur in a vector database, the spatial distribution of vectors within the index shifts, often in subtle but impactful ways.
This dynamic introduces a challenge: maintaining the structural integrity of the index while ensuring retrieval accuracy.
One overlooked aspect is the cascading effect of even minor updates, where the insertion or modification of a single vector can disrupt the balance of proximity relationships across the index.
Traditional indexing methods, such as tree-based structures or static partitions, struggle in these scenarios because they are optimized for static datasets.
In contrast, dynamic indexing techniques, like Hierarchical Navigable Small World (HNSW) graphs, adapt more fluidly by recalculating affected connections in real time.
However, this adaptability comes at the cost of increased memory usage and computational overhead, particularly in high-frequency update environments.
A notable example is Qdrant's implementation of hybrid indexing, which combines in-memory buffers for rapid updates with disk-based storage for persistence.
This approach minimizes latency but requires careful tuning to prevent bottlenecks during index merges.
Ultimately, the effectiveness of an update strategy depends on contextual factors like data volatility and query patterns. A nuanced approach, blending incremental updates with periodic reindexing, ensures both performance and consistency in dynamic systems.
Consistency Models in Vector Databases
Consistency in vector databases is not a one-size-fits-all concept but a spectrum of trade-offs tailored to specific application needs.
At its core, a consistency model defines how updates propagate across distributed nodes, directly influencing retrieval accuracy and system performance.
For instance, strong consistency ensures that all replicas reflect the latest data before a write operation is acknowledged. While this guarantees data integrity, it introduces latency, often exceeding 200ms in high-throughput systems like fraud detection platforms.
In contrast, eventual consistency prioritizes availability and low latency by allowing temporary discrepancies between replicas.
This model is particularly effective in social media feeds, where real-time updates are less critical than user experience.
However, the risk of conflicting results necessitates robust conflict resolution mechanisms, such as vector versioning or quorum-based protocols.
By tuning read timestamps, systems can dynamically adapt to workload demands, ensuring responsiveness and reliability. This adaptability underscores the importance of aligning consistency strategies with application-specific priorities.
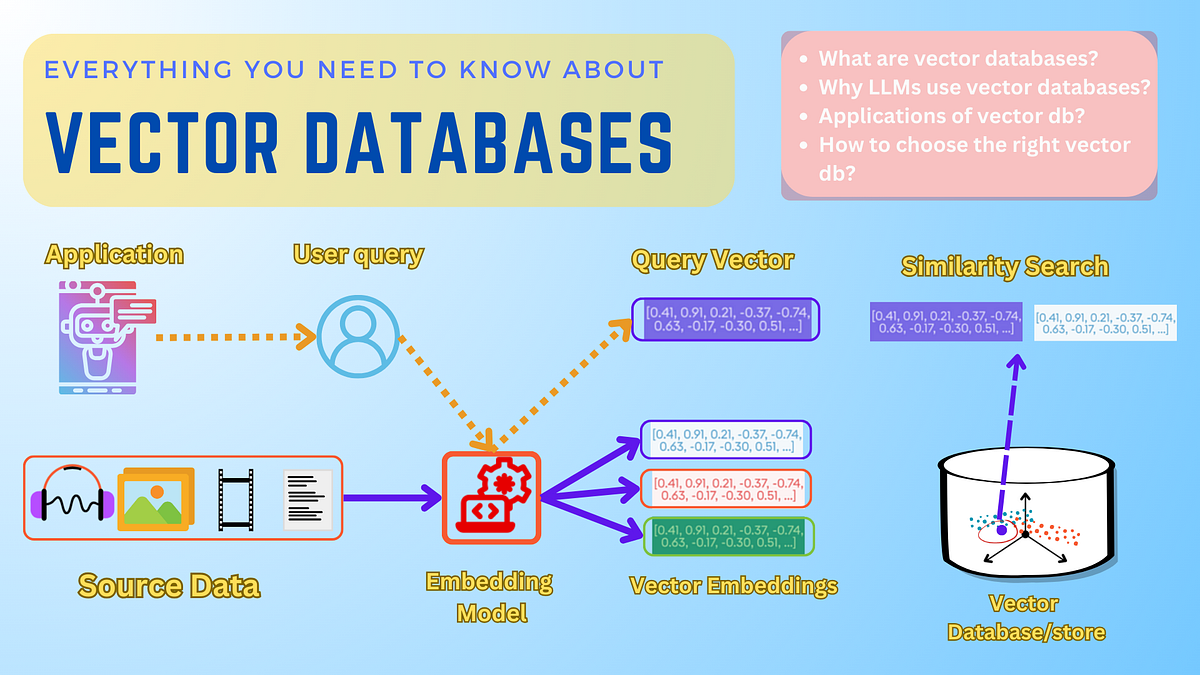
Image source: linkedin.com
Exploring Consistency Models: Strong vs. Eventual Consistency
Strong and eventual consistency models represent two ends of a spectrum, but their real-world application often lies in the nuanced middle ground.
One critical yet underexplored aspect is the latency thresholds' role in determining these models' practical viability.
Latency, often dismissed as a secondary concern, directly influences user experience and system throughput, making it a pivotal factor in consistency model selection.
Strong consistency ensures immediate data alignment across nodes, but this comes at the cost of increased latency.
For instance, the synchronization delay can bottleneck query performance in a distributed vector database handling high-frequency updates.
Conversely, eventual consistency minimizes latency by allowing temporary discrepancies, but this can lead to outdated or conflicting results in time-sensitive applications like fraud detection.
A hybrid approach, such as bounded staleness consistency, offers a compelling alternative.
By defining acceptable latency thresholds for data propagation, systems can balance immediacy with accuracy.
For example, Milvus employs tunable consistency settings, enabling administrators to adjust read staleness based on workload demands. This flexibility ensures that critical queries prioritize accuracy, while less sensitive operations benefit from reduced latency.
Ultimately, the choice of consistency model is not binary but contextual.
By integrating latency-aware strategies, organizations can achieve a dynamic equilibrium, optimizing both performance and reliability in distributed vector databases.
Techniques for Ensuring Data Synchronization
Event-based synchronization is one of the most effective yet underutilized techniques for ensuring data synchronization in vector databases.
Unlike periodic refresh methods, which operate on fixed schedules, event-based synchronization reacts dynamically to changes in the data, ensuring updates are propagated as soon as they occur.
This approach is particularly valuable in high-frequency environments, such as e-commerce platforms, where even minor delays can disrupt user experience.
The core mechanism involves leveraging change data capture (CDC) to monitor transaction logs for modifications. By capturing these changes in real time, the system can trigger synchronization workflows that update distributed nodes without waiting for batch processes.
This minimizes latency and ensures that all replicas reflect the most current data. However, the effectiveness of this technique depends heavily on the underlying infrastructure.
For instance, systems with high network latency or limited bandwidth may struggle to maintain synchronization at scale.
A notable implementation of event-based synchronization can be seen in Nexla’s DB-CDC flows, which streamline updates by directly monitoring transaction logs and transferring changes to target systems.
This ensures that downstream applications always operate on the latest data, reducing the risk of stale results.
While event-based synchronization excels in immediacy, it requires robust conflict resolution mechanisms to handle simultaneous updates.
Techniques like vector clocks or quorum-based protocols can mitigate these challenges, ensuring consistency without sacrificing performance.
Optimizing Retrieval After Updates
Retrieval optimization following updates in vector databases hinges on recalibrating indexing structures to maintain both speed and precision.
A critical yet underappreciated technique involves adaptive reindexing, where only the most affected regions of the index are recalculated.
This minimizes computational overhead while preserving retrieval accuracy. For instance, systems like Pinecone leverage selective graph pruning to dynamically adjust proximity relationships, ensuring that query results remain consistent even as embeddings evolve.
Another advanced approach is query vector augmentation, which enriches the input query with contextual metadata derived from recent updates.
This method, employed by platforms like Weaviate, enhances the system’s ability to interpret nuanced queries without requiring full reindexing.
The database can prioritize the most relevant vectors by embedding temporal markers or semantic tags, effectively bridging the gap between static indices and dynamic data.
These strategies underscore a pivotal insight: retrieval optimization is not merely a technical adjustment but a systemic recalibration that aligns evolving data with user expectations.

Image source: kdb.ai
Retrieval Optimization Techniques
Adaptive reindexing stands out as a transformative approach for maintaining retrieval accuracy in dynamic vector databases.
This method avoids the inefficiencies of full reindexing while preserving precision by recalculating only the most impacted regions of the index.
The underlying principle is to localize updates, ensuring minimal disruption to the broader index structure. This technique is particularly effective in high-frequency update environments, where computational overhead must be tightly controlled.
A compelling comparison emerges when evaluating adaptive reindexing against traditional full reindexing.
While the latter guarantees consistency, it often introduces significant latency and resource consumption. On the other hand, adaptive reindexing leverages selective recalibration, striking a balance between performance and accuracy. However, its effectiveness hinges on robust mechanisms for identifying affected regions, a challenge that varies with data volatility and query patterns.
One notable implementation is Pinecone’s selective graph pruning, which dynamically adjusts proximity relationships without requiring exhaustive recalculations. This approach exemplifies how adaptive strategies can align theoretical efficiency with practical scalability.
Ultimately, retrieval optimization demands a nuanced understanding of system dynamics, where adaptive techniques offer a pragmatic path forward.
Balancing Consistency and Performance
Balancing consistency and performance in vector databases often hinges on the strategic use of bounded staleness consistency. This model allows systems to tolerate minor delays in data propagation while maintaining a predictable level of accuracy. The key lies in defining acceptable staleness thresholds, which act as a buffer against the latency introduced by synchronization processes.
The underlying mechanism involves timestamp-based coordination, where updates are tagged with logical or physical timestamps.
Queries can then be executed against the most recent data within the defined staleness window.
This approach minimizes the trade-off between immediacy and accuracy, making it particularly effective in high-throughput environments like recommendation systems.
A comparative analysis reveals that while strong consistency ensures perfect alignment, it often incurs significant latency, especially in distributed setups.
Eventual consistency, on the other hand, sacrifices precision for speed, leading to outdated results in critical applications.
Bounded staleness strikes a middle ground, offering a tunable framework adaptable to varying workloads.
By integrating this model, organizations can optimize retrieval workflows, ensuring responsiveness and reliability without overburdening system resources.
FAQ
What causes retrieval inconsistency after vector database updates?
Retrieval inconsistency often results from embedding drift and outdated index structures. These changes misalign vector relationships, which disrupts similarity search accuracy. Monitoring query times and score shifts can help identify and address the problem.
How do embedding drift and entity relationships affect retrieval?
When vector embeddings shift, they can break spatial links between related entities. This weakens semantic coherence and lowers retrieval precision. Salience analysis and co-occurrence tracking help preserve these relationships during updates.
How can index structures be optimized to reduce inconsistency?
Index structures can be optimized through adaptive reindexing, salience-based update targeting, and hybrid indexing. These methods recalibrate only affected areas, keeping high-value relationships intact while reducing processing load.
How do salience analysis and co-occurrence improve retrieval?
Salience analysis flags the most relevant vectors for update, while co-occurrence optimization ensures linked entities stay close in embedding space. Together, they stabilize the system and maintain retrieval accuracy during data changes.
What role do hybrid indexing methods play in retrieval consistency?
Hybrid indexing methods use a mix of graph-based and file-based techniques to support consistent retrieval. They adapt to data shifts by balancing update flexibility and search precision, making them suitable for high-frequency environments.
Conclusion
Handling retrieval inconsistency after vector database updates is critical for systems that rely on precision. Index drift, embedding changes, and scaling demands make consistency a moving target.
Techniques like salience tracking, hybrid indexing, and adaptive reindexing offer ways to reduce disruption.
As vector-based systems expand into production, maintaining accurate retrieval requires constant tuning—not just to the data but also to how the system interprets relationships over time.