
Vision Models: Cost-Efficient PDF Parsing for RAG
Vision models offer a scalable, cost-effective solution for parsing complex PDFs in RAG systems. This guide explores how to leverage visual AI to extract structured data, improve retrieval quality, and minimize preprocessing overhead.


PDFs weren’t designed to be parsed. They were designed to be printed. So when systems try to extract structured data from financial reports or medical records, things break. Tables split. Critical links between images and text get lost.
And that’s a big problem—especially in Retrieval-Augmented Generation (RAG) workflows, where one parsing error can throw off the entire output.
This is where Vision Models: Cost-Efficient PDF Parsing for RAG changes the story. By treating documents as both visual and textual objects, vision models decode layout, structure, and meaning in one pass. They’re not just finding words—they’re understanding relationships.
Let’s examine how this shift addresses long-standing issues in document intelligence, one layout at a time.
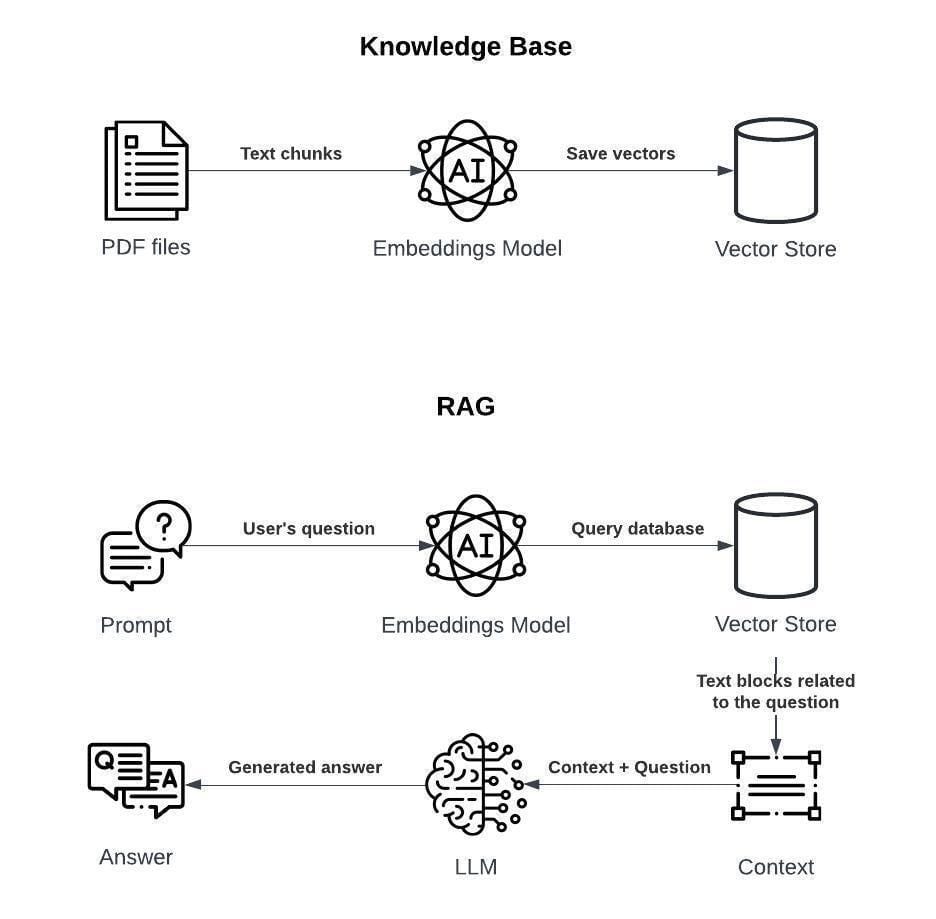
Basics of PDF Structure and Parsing Challenges
Parsing PDFs is like solving a puzzle where the pieces—text, images, and layouts—don’t always fit neatly. One overlooked complexity lies in the absence of semantic markers.
Unlike HTML, which uses tags to define structure, PDFs rely on visual cues like font size, spacing, and alignment. This makes distinguishing a title from a bolded phrase or identifying table headers a significant challenge.
The real breakthrough comes from vision models that analyze these visual hierarchies. By combining text embeddings with layout features, they preserve relationships between elements, such as how annotations align with main content.
For instance, Pfizer’s use of vision-enhanced RAG systems demonstrated how maintaining these relationships reduced errors in parsing clinical trial reports.
However, even the most advanced models still face edge cases. Dense legal contracts, for example, often include overlapping elements, such as footnotes and multi-column text, which can confuse spatial recognition algorithms. Addressing these requires fine-tuning models with domain-specific datasets.
The key takeaway? Effective parsing demands a balance between technical precision and contextual awareness, ensuring no detail is lost in translation.
Introduction to Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) transforms PDF parsing by addressing a critical gap: the inability to contextualize extracted data.
Unlike traditional methods that focus solely on text extraction, RAG integrates external knowledge, enabling vision models to interpret documents holistically. This approach is particularly effective in scenarios where visual and textual elements interact in complex ways, such as multi-page financial reports or annotated legal contracts.
The core mechanism lies in combining retrieval with generation.
Vision models first parse the document, identifying structural elements like tables or diagrams.
Then, RAG retrieves supplementary information—such as historical data or related clauses—to fill in gaps or clarify ambiguities. This dual-layered process ensures that the output is not just accurate but contextually enriched.
For example, M3DocRAG excels in handling multi-document scenarios by dynamically referencing external datasets.
This capability is invaluable in industries such as healthcare, where strict regulatory compliance demands precision.
However, challenges remain, such as ensuring computational efficiency and maintaining alignment between retrieved and parsed data.
By uniting retrieval and generation, RAG redefines how vision models approach unstructured data, offering a nuanced, context-aware solution.
Traditional vs. Vision-Based Parsing Methods
Traditional parsing methods, such as rule-based systems and Optical Character Recognition (OCR), operate on rigid frameworks.
They excel in extracting plain text from simple layouts but falter when faced with the intricate structures of modern PDFs.
For instance, a dense financial report with multi-column tables often yields fragmented outputs, necessitating hours of manual correction. These methods treat documents as static text repositories, ignoring the interplay between text, visuals, and layout.
Vision-based parsing, by contrast, redefines the process by treating documents as integrated ecosystems.
Using Vision Language Models (VLMs), these systems analyze both textual and visual elements simultaneously. This approach ensures that tables remain aligned, annotations stay linked, and diagrams retain their context.
For example, a pharmaceutical company parsing clinical trial data can now extract structured insights without losing critical relationships between elements.
The shift isn’t merely technical—it’s conceptual. Traditional methods focus on extraction, while vision models emphasize understanding. This evolution transforms unstructured PDFs into actionable datasets, enabling industries to achieve precision and efficiency previously unattainable.
Limitations of Rule-Based and OCR Approaches
Rule-based systems and OCR often struggle when encountering PDFs that deviate from standard layouts.
Their reliance on predefined rules or pixel-based text recognition means they struggle to interpret complex structures like overlapping elements or irregular tables.
This rigidity leads to fragmented outputs, particularly in documents where spatial relationships are critical.
One key limitation lies in their inability to preserve contextual integrity.
For example, OCR might extract text from a multi-column layout but fail to maintain the logical flow between columns, rendering the data unusable. Rule-based systems, while computationally efficient, lack adaptability, often requiring extensive manual intervention to handle edge cases like scanned images or handwritten annotations.
To overcome these challenges, integrating vision models offers a transformative approach. By analyzing both text and layout holistically, they bridge the gap between recognition and understanding, enabling seamless data extraction even in the most intricate scenarios.
Emergence of Vision Language Models (VLMs)
Vision Language Models (VLMs) revolutionize PDF parsing by addressing a critical gap: the integration of spatial and semantic understanding.
Unlike traditional methods, VLMs interpret documents as cohesive visual-textual entities, enabling them to decode complex layouts with precision.
At the core of VLM functionality lies the fusion of embeddings from visual and textual encoders. This fusion layer aligns spatial hierarchies with semantic content, ensuring that elements like multi-column text or nested tables are parsed in context.
For instance, when processing annotated legal contracts, VLMs maintain the logical flow between annotations and the primary content, a feat that is unattainable with OCR alone.
A notable advantage of VLMs is their adaptability across domains. In healthcare, for example, domain-specific VLMs like MedFlamingo excel in extracting structured insights from radiology reports, where visual markers and textual descriptions intertwine.
However, challenges persist, such as ensuring computational efficiency when scaling to high-resolution documents.
To maximize their potential, practitioners must fine-tune VLMs with domain-specific datasets.
This approach not only enhances accuracy but also uncovers nuanced relationships within data, transforming unstructured PDFs into actionable intelligence. The implications for industries reliant on precision are profound, reshaping workflows and decision-making processes.
Hybrid Multimodal Parsing Techniques
Hybrid multimodal parsing redefines how we approach PDF processing by combining heuristic methods with advanced AI-driven models.
This synergy addresses a critical challenge: preserving the intricate interplay between text, visuals, and layout in complex documents.
Unlike standalone approaches, hybrid systems leverage the rule-based precision of heuristics to handle predictable patterns while deploying multimodal Vision Language Models (VLMs) for nuanced, context-aware parsing.
One key innovation lies in converting document pages into high-resolution images, enabling VLMs to process them as cohesive visual-textual entities.
For instance, tools like LlamaParse integrate heuristic pre-processing to identify structural markers—such as headers or footnotes—before applying VLMs for deeper semantic analysis. This layered approach minimizes common errors like misaligned tables or fragmented annotations, ensuring data integrity.
A counterintuitive insight?
Heuristic methods, often dismissed as outdated, excel in pre-structuring data for AI models, reducing computational overhead.
By bridging deterministic rules with adaptive learning, hybrid parsing not only enhances accuracy but also scales efficiently for high-volume workflows, transforming unstructured PDFs into actionable datasets.

Combining Heuristic and AI-Based Methods
Blending heuristic techniques with AI models creates a dynamic synergy that addresses the inherent complexity of parsing PDFs.
Heuristics act as a structural guide, identifying predictable elements like headers, footnotes, or line breaks, while AI models excel in interpreting nuanced relationships and extracting context-rich data.
This combination is particularly effective in scenarios where document layouts are inconsistent or contain overlapping elements.
For instance, heuristic rules can pre-structure data by segmenting multi-column layouts or isolating embedded tables, enabling AI to focus on semantic understanding rather than structural disarray. The interplay between these methods ensures that deterministic rules handle repetitive patterns, while AI adapts to edge cases and irregularities.
A notable example is the implementation by Instill Core Artifact, which integrates heuristic pre-processing with multimodal VLMs. This approach not only reduces computational overhead but also enhances accuracy in extracting structured data from dense legal contracts and annotated research papers.
The real innovation lies in striking a balance between these methods.
By leveraging heuristics to simplify input complexity, AI models can operate more efficiently, transforming unstructured PDFs into actionable datasets. This hybrid approach is a cornerstone for scalable, high-fidelity document parsing systems.
Direct Image-Based Retrieval for RAG
Direct image-based retrieval transforms PDF parsing by treating the entire page as a cohesive visual entity, bypassing the pitfalls of text extraction.
This approach leverages the inherent structure of images, capturing spatial relationships and visual hierarchies that traditional OCR methods often disrupt.
By embedding these visual layouts into a unified vector space, systems can retrieve contextually rich data without fragmenting critical elements.
One standout technique involves multimodal embedding models that integrate image and layout features directly into retrieval pipelines.
Unlike text-first methods, these models prioritize visual fidelity, ensuring that tables, annotations, and diagrams remain intact. For instance, Voyage AI’s “voyage-multimodal-3” model excels in embedding high-resolution document images, enabling precise retrieval even in dense, multi-layered PDFs.
However, high computational demands and the need for domain-specific fine-tuning can limit scalability. Additionally, edge cases, such as handwritten annotations or low-quality scans, require adaptive preprocessing to maintain accuracy.
This method’s real-world impact is profound.
Organizations like KDB.AI have demonstrated its utility in financial reporting, where preserving visual context eliminates manual corrections.
By aligning retrieval with visual layouts, this approach not only enhances efficiency but also redefines the standards for extracting structured data.
Enhancing RAG with Vision Models
Preserving the structural integrity of a document is not just a technical necessity—it’s the linchpin for actionable insights in Retrieval-Augmented Generation (RAG) workflows.
Vision models excel here by treating PDFs as cohesive visual-textual entities, ensuring that every table, annotation, and diagram retains its context.
This approach transforms unstructured data into structured intelligence, enabling precise retrieval without sacrificing nuance.
Consider the interplay of multimodal embeddings, where text and image data are fused into a unified representation.
A common misconception is that these models merely enhance OCR. In reality, they redefine parsing by embedding relationships between elements, much like a cartographer mapping terrain.
This capability is critical in industries like finance, where misaligned data can skew multi-million-dollar decisions. The result? Faster workflows, fewer errors, and unparalleled trust in extracted data.
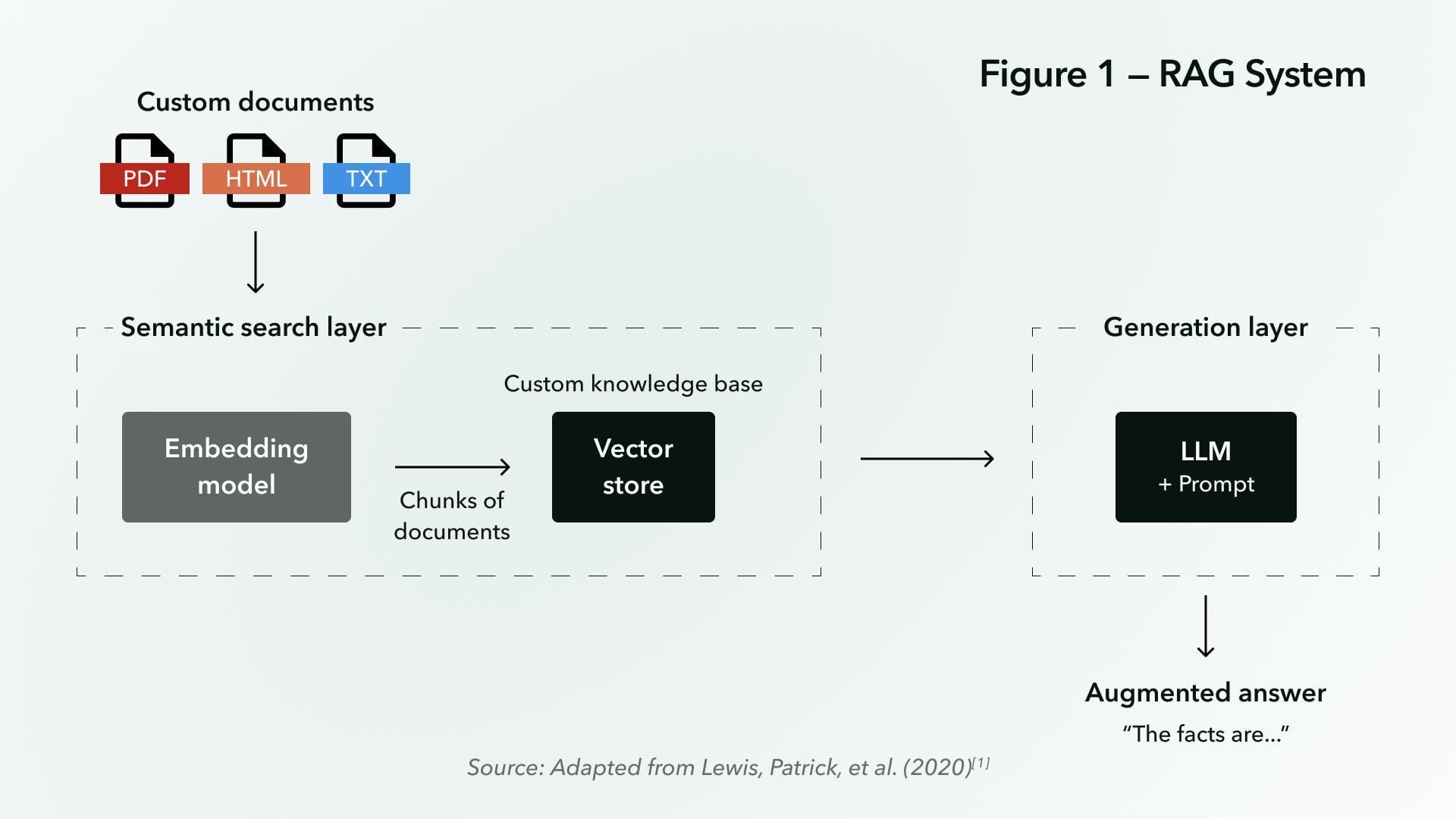
Preserving Document Structure and Context
Preserving a document’s structure is not just about aesthetics—it’s about maintaining the relationships that give data its meaning.
Vision models excel here by treating every element, from tables to annotations, as interconnected parts of a larger narrative. This approach ensures that no detail is isolated or misaligned, which is critical for workflows like RAG.
One key technique is the use of late interaction mechanisms, where text and image embeddings are fused only at query time.
This avoids premature merging, which can distort complex layouts. For example, in legal contracts, this method ensures that clauses remain tied to their annotations, enabling precise retrieval without losing context. The result? A system that doesn’t just extract data but understands its placement and significance.
However, edge cases like handwritten notes or inconsistent formatting still challenge these models.
Addressing these requires adaptive preprocessing pipelines that dynamically adjust to layout variability. By combining these techniques, vision models transform unstructured PDFs into cohesive, actionable datasets, bridging the gap between raw data and meaningful insights.
Improving Retrieval Accuracy and Contextual Richness
Retrieval accuracy hinges on more than just identifying relevant data—it requires preserving the intricate relationships that give documents their meaning.
Vision models excel in this domain by integrating spatial and semantic cues, ensuring that the document’s structure remains intact during parsing. This approach transforms retrieval into a process of contextual understanding, rather than merely extracting data.
A critical technique involves attention-based fusion mechanisms, where visual and textual embeddings are dynamically weighted based on their relevance to the query. This ensures that key elements, such as table headers or annotations, are prioritized without distorting the document’s narrative flow.
For instance, in regulatory compliance workflows, this method enables precise retrieval of clauses tied to specific legal precedents, reducing the risk of misinterpretation.
However, challenges arise in edge cases, such as low-resolution scans or documents with inconsistent formatting.
Addressing these requirements necessitates adaptive preprocessing pipelines that normalize layouts before embedding.
Organizations like ColPali have demonstrated success by employing late interaction mechanisms, which delay the fusion of visual and textual data until query time, enhancing both efficiency and accuracy.
By aligning retrieval with document structure, vision models enable actionable insights, particularly in high-stakes industries where precision is paramount. This nuanced approach redefines how we leverage unstructured data for decision-making.
FAQ
What are vision models and how do they support cost-efficient PDF parsing for RAG systems?
Vision models combine image and text data to understand documents as unified layouts. They preserve structure, reduce parsing errors, and cut manual corrections. This improves efficiency in Retrieval-Augmented Generation (RAG) workflows and lowers processing costs.
How do vision models keep document structure intact in RAG workflows?
Vision models use spatial-text alignment to maintain the placement of tables, annotations, and images. This ensures each element stays in context during parsing and retrieval, improving the accuracy of results in RAG systems.
What do multimodal embeddings do in PDF parsing?
Multimodal embeddings combine text and image features into a shared space. This helps systems understand layout and meaning together, which improves parsing accuracy in documents with complex formats like reports or medical records.
How can healthcare and finance use cost-efficient PDF parsing with vision models?
Healthcare and finance benefit from structured parsing that preserves data relationships. Vision models help extract reliable data from medical notes or financial tables, improving reporting and decision-making while saving time and costs.
What challenges arise in scaling vision models for PDF parsing and how are they solved?
Challenges include layout variability, high compute use, and inconsistent formatting. Solutions include domain-tuned models, adaptive preprocessing, and efficient storage using vector databases. These ensure scalable, precise parsing for large RAG tasks.
Conclusion
Cost-Efficient PDF Parsing for RAG is no longer a future concept—it’s already solving key problems in how systems handle unstructured documents.
By combining structure and meaning through multimodal models, organizations now extract precise, contextual data from complex layouts. From financial audits to patient records, this shift makes document parsing not just faster, but more reliable.
As hybrid pipelines and structured outputs become standard, vision-based parsing will define the next era of Retrieval-Augmented Generation.