
Using Vision Models for Complex PDF Parsing in RAG Systems
Vision models are revolutionizing PDF parsing in RAG systems. This guide explores how AI-driven vision techniques improve text extraction, document structure analysis, and retrieval accuracy for more efficient knowledge processing in complex PDFs.


Extracting data from PDFs isn’t as simple as it seems.
Text-based tools struggle with tables, multi-column layouts, and diagrams, often returning broken sentences and misaligned data.
These errors can't be ignored in RAG systems, where accuracy matters.
Vision models solve this. They don’t just read the text—they understand the document’s structure, visuals, and context.
This means clean tables, intact annotations, and reliable data retrieval. Vision-powered parsing makes complex PDF processing in RAG systems more precise and efficient, from clinical trial reports to financial documents.
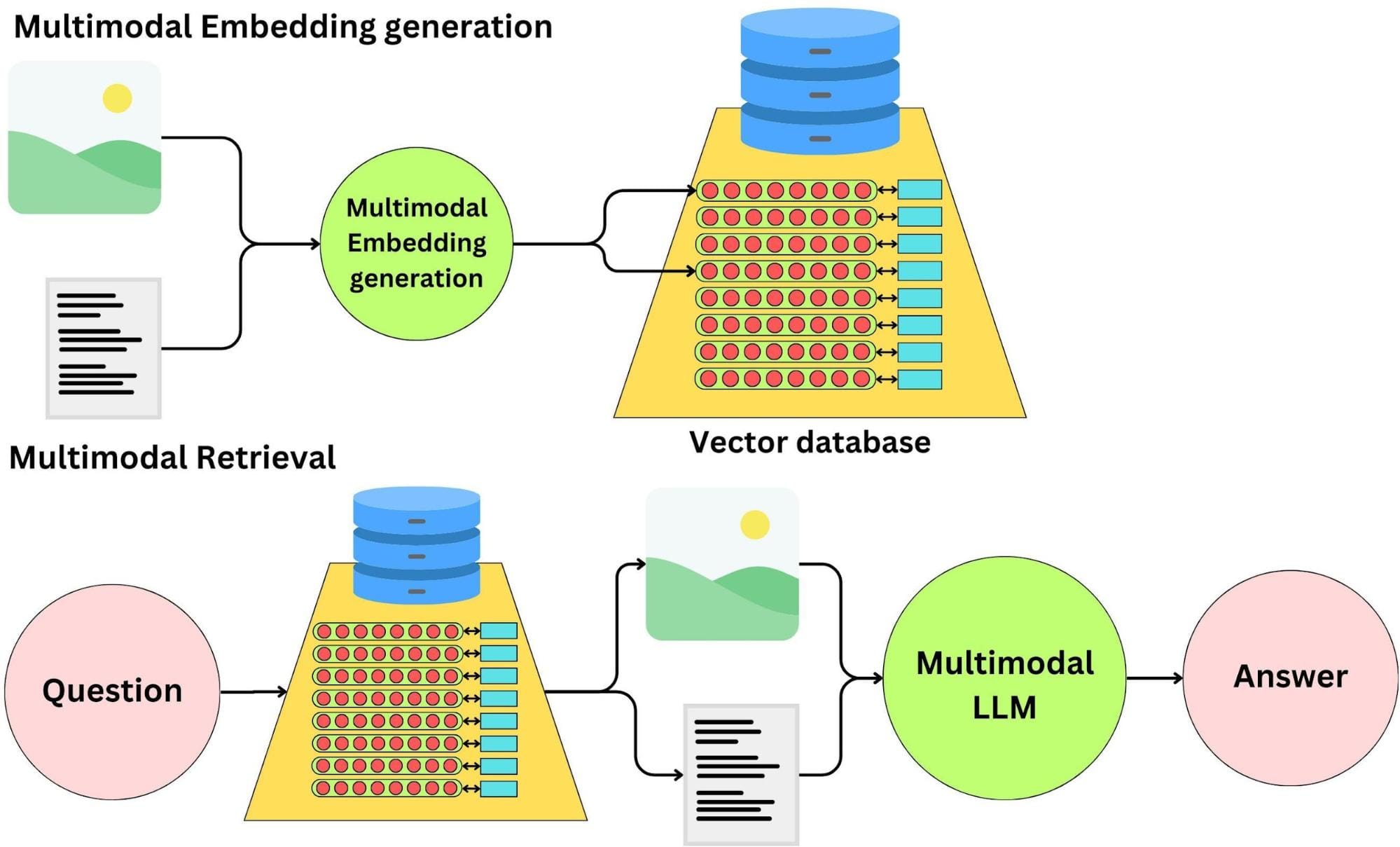
The Evolution of PDF Parsing Techniques
Let’s talk about why traditional PDF parsing tools often fall short.
They’re great for simple documents but crumble when faced with multi-column layouts, dense tables, or embedded visuals. Enter vision models—tools that don’t just read text but understand the document’s structure, much like a human would.
Take ChatDOC, for example. A recent study involving 188 professional documents and 302 questions found that ChatDOC outperformed baseline RAG systems on over 40% of queries.
Why? Because it uses a panoptic and pinpoint PDF parser to preserve the integrity of complex layouts. This means tables stay aligned, diagrams remain intact, and no critical detail is lost.
Here’s the kicker: vision models don’t just extract data—they enhance it. Combining text and image embeddings creates a richer dataset for retrieval.
Imagine a legal RAG system parsing contracts with intricate clauses or a healthcare RAG system analyzing medical reports.
The results? Faster insights, fewer errors, and better decision-making.
Role of Vision Models in Modern RAG Systems
Parsing PDFs for RAG is like solving a puzzle with missing pieces. Traditional methods? They’re great for plain text but fall apart when faced with dense tables, overlapping visuals, or multi-column layouts. Vision models, however, flip the script—they don’t just read; they see.
Take ChatDOC, for instance. It’s not just another parser; it’s a game-changer. Combining text and image embeddings keeps tables aligned, diagrams intact, and every detail in place.
It gets exciting here: companies like Pfizer use vision-enhanced RAG to analyse clinical trial reports.
Instead of sifting through chaotic data, they get structured insights—faster decisions, fewer errors. And retrieval becomes seamless with tools like Qdrant, which store both text and image vectors.
Foundational Concepts in PDF Parsing
Parsing PDFs isn’t just about pulling text—it’s about understanding everything on the page.
Think of a PDF as a puzzle: text, tables, images, and layouts are the pieces. Traditional tools like PyPDF?
They’re like trying to solve that puzzle with missing edges. You might get some text, but the structure? Gone. Tables? A mess. Images? Forget it.
Here’s where vision models flip the script. They don’t just read; they see. Imagine looking at a dense legal contract.
A vision model doesn’t just grab the words—it recognizes the clauses, the table of fees, even the signature block. It’s like having a human scan the document faster and more precise.
People often misunderstand parsing as just text extraction. It’s not. Parsing is about context, structure, and making sense of the whole picture.
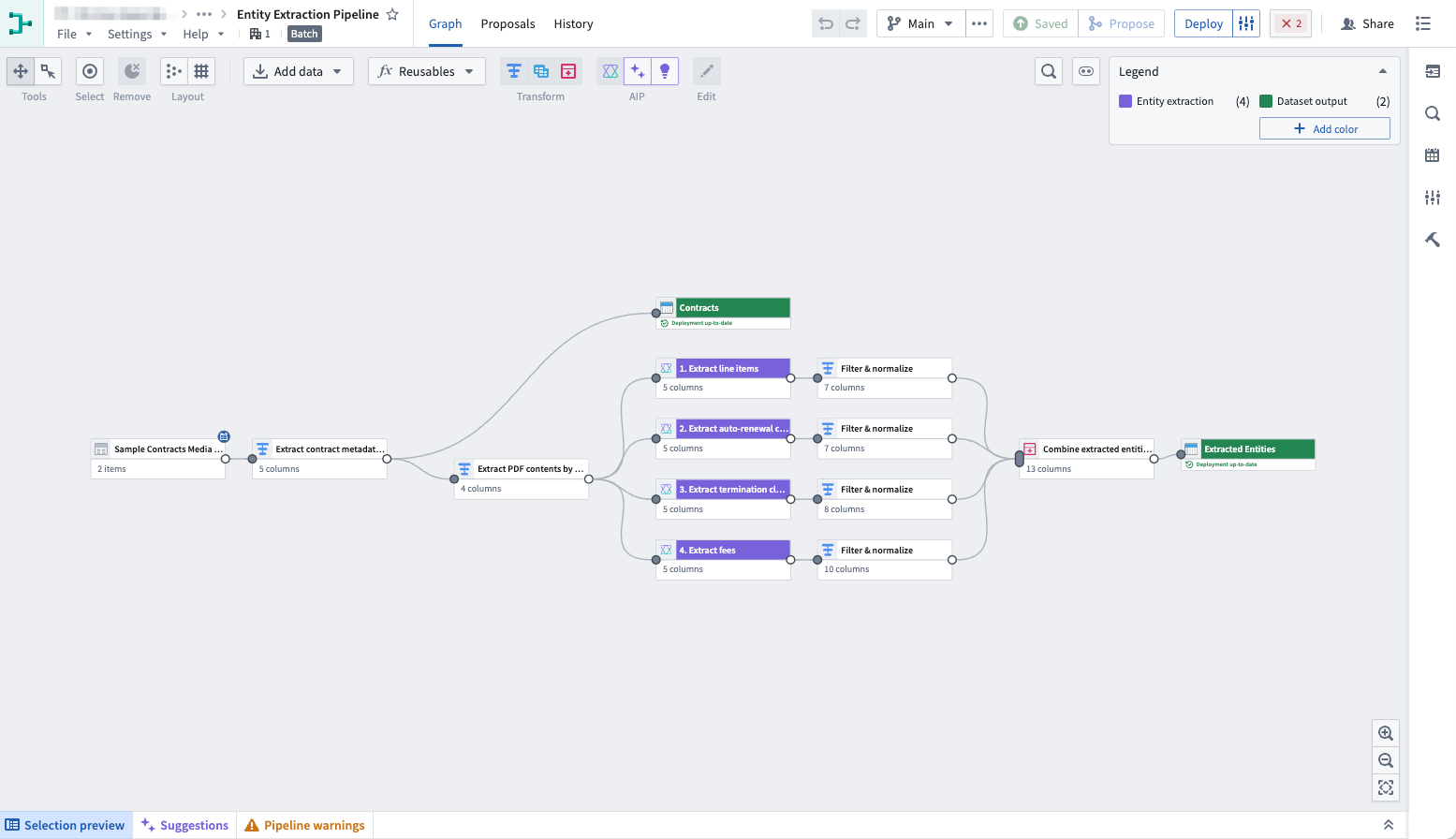
Understanding Basic PDF Structure
At first glance, a PDF might seem like a simple digital document, but it’s a maze of disconnected elements under the hood.
Unlike HTML, which uses tags to define structure, PDFs rely on visual cues like font size or spacing.
This lack of semantic markers makes it nearly impossible for traditional parsers to distinguish a title from a random bolded phrase.
Here’s where vision models shine. They analyze a page's visual hierarchy, detecting headers, footnotes, and even subtle layout patterns.
For example, Pfizer used vision-enhanced RAG systems to parse clinical trial reports. By preserving the structure of tables and annotations, they reduced data extraction errors, speeding up regulatory submissions.
A surprising challenge is that many PDFs don’t follow consistent formatting. For example, a financial report might have multi-column layouts, while a legal contract uses dense, single-column text. Vision models adapt by combining text embeddings with image analysis, ensuring no detail is lost.
Looking ahead, integrating these models with vector databases like Qdrant could unlock even richer insights, transforming how industries handle unstructured data.
Traditional Text Extraction Methods and Their Limitations
Parsing PDFs with traditional methods feels like trying to solve a puzzle with missing pieces.
Tools like PyPDF or basic OCR systems can handle simple text-based documents, but they crumble when you add a multi-column layout, dense tables, or embedded images.
Why? Because these methods rely on rigid rules—matching pixel patterns or extracting plain text—without understanding the document’s structure.
Take financial reports, for example. Companies like Goldman Sachs often deal with multi-year data tables.
Traditional parsers frequently misalign rows or drop critical footnotes, leading to errors that require hours of manual correction. In contrast, vision models preserve the table’s integrity, ensuring every number stays in its rightful place.
A key limitation of older methods is their inability to adapt to variability. Scanned PDFs, handwritten notes, or inconsistent layouts often result in garbled outputs.
This is where vision models shine—they combine text and image analysis to “see” the document as a whole, much like a human would.
Looking ahead, integrating vision models with adaptive RAG systems could eliminate manual intervention entirely, unlocking faster, error-free data extraction.
Intermediate Techniques: Vision Language Models
Parsing PDFs is like solving a Rubik’s Cube blindfolded—traditional methods fumble when faced with complex layouts. Vision Language Models (VLMs) flip the script.
They don’t just extract text; they understand the document as a whole, blending visual and textual cues for precision.
Here’s the magic: VLMs treat a PDF as both an image and a text source. Imagine analyzing a pharmaceutical report packed with dense tables and annotated diagrams.
A VLM doesn’t just grab the words—it keeps the table rows aligned, the annotations intact, and the context crystal clear.
A common misconception? That VLMs are just OCR on steroids. They’re not.
They combine text embeddings with image analysis, creating a richer dataset for retrieval. Think of it as having a librarian who reads the book and remembers where every chart and footnote belongs.
Introduction to Vision Language Models (VLMs)
Let’s face it—traditional OCR tools are like trying to read a book through a keyhole. They grab the text but miss the bigger picture.
Vision Language Models (VLMs) change that by treating documents as a combination of text and visuals, unlocking a new level of understanding.
Here’s a thought experiment: imagine a legal contract with multi-column text, footnotes, and embedded signatures.
A VLM doesn’t just see words—it recognizes clauses, aligns columns, and identifies the signature block as a key element. This holistic approach eliminates the chaos of fragmented data.
Looking ahead, integrating VLMs with adaptive RAG systems could redefine how industries handle unstructured data, turning complexity into clarity.
Image-to-Text Conversion and Document Layout Analysis
Extracting text from a complex PDF is not just about recognition—it’s about understanding structure.
Traditional OCR-based methods often break down when faced with multi-column layouts, tables, and embedded visuals, leading to misaligned data and fragmented content.
Vision Language Models (VLMs) overcome this by processing PDFs as both text and images, ensuring that extracted information retains its original format and context.
VLMs combine text embeddings with image analysis, preserving table structures, annotations, and layout relationships.
This makes them well-suited for financial reports, legal documents, and clinical trial records, where maintaining visual hierarchy is critical.
VLMs go beyond simple text extraction when integrated with adaptive RAG systems, enabling context-aware retrieval.
This shift could automate data processing, reduce manual corrections, and improve retrieval accuracy across industries that rely on structured documents.
Advanced Parsing Techniques and Multimodal Embeddings
Parsing PDFs is like solving a 3D puzzle blindfolded. Traditional methods? They grab the text but leave the structure in shambles.
Enter advanced parsing techniques powered by multimodal embeddings—tools that don’t just read but understand.
Here’s the magic: these models treat a PDF as both text and image. Imagine a pharmaceutical report packed with dense tables and annotated diagrams.
A multimodal system doesn’t just extract the words—it keeps the rows aligned, the annotations intact, and the context crystal clear.
The misconception? People think these models are just OCR on steroids. They’re not. Combining text embeddings with image analysis creates a richer dataset for retrieval.
It’s like having a librarian who reads the book and remembers where every chart and footnote belongs.
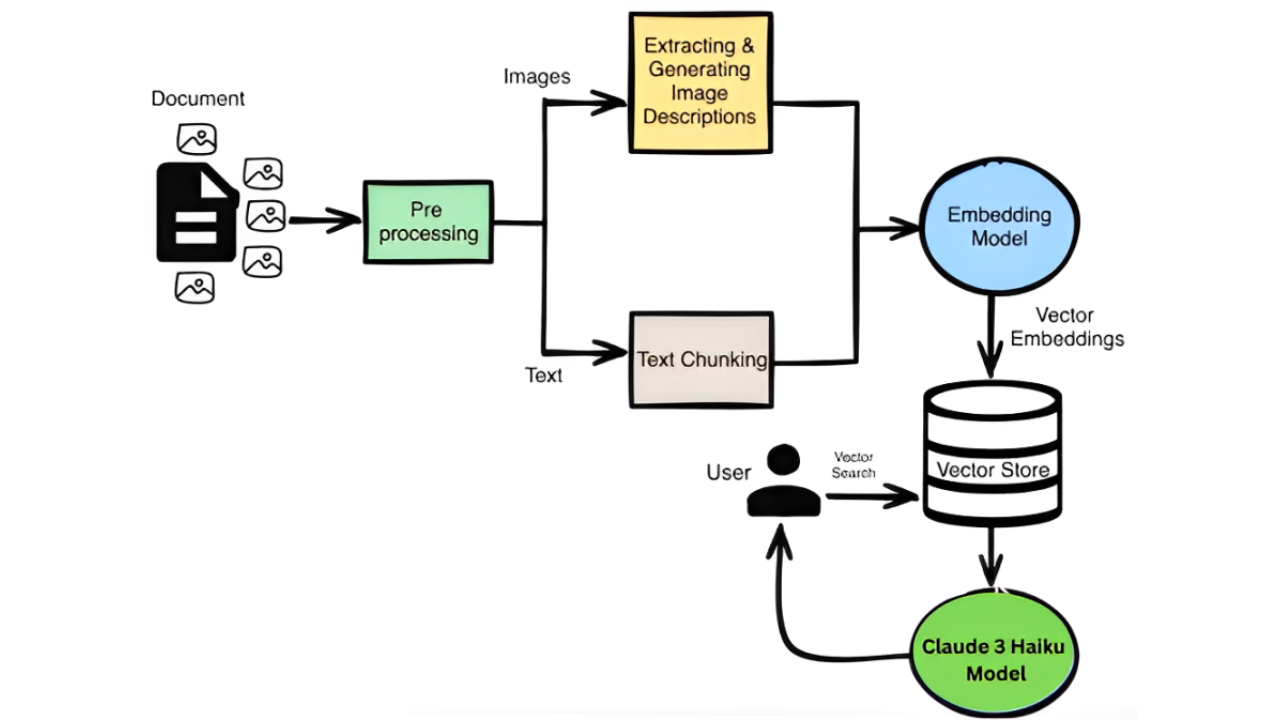
Multimodal Embedding Techniques for PDF Parsing
Parsing complex PDFs requires more than text extraction—it demands understanding how text and visuals interact.
Multimodal embeddings address this by integrating text, images, tables, and diagrams into a unified representation.
Unlike traditional methods that treat text and visuals separately, multimodal embeddings preserve document structure. They ensure that tables remain aligned, figures retain their labels, and footnotes stay linked to the main content.
This technique benefits financial reports, legal contracts, and research papers, where misaligning multi-year data tables or regulatory clauses can lead to incorrect insights.
By embedding text and visual relationships, multimodal models improve retrieval precision in RAG systems, transforming unstructured PDFs into structured, context-rich datasets.
As these embeddings evolve, they will help AI systems extract, interpret, and retain document relationships, bridging the gap between data extraction and real-world application.
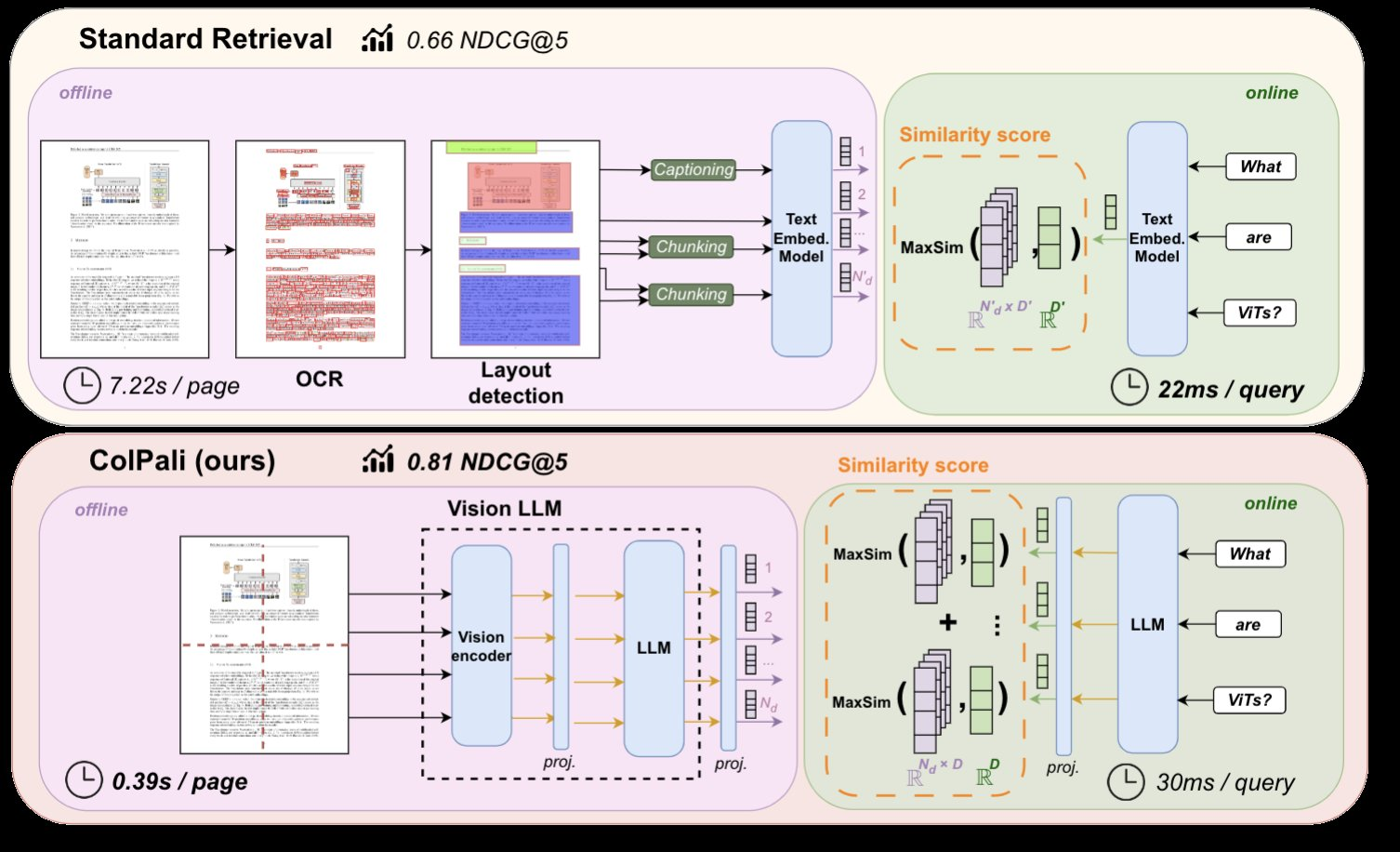
Late Interaction Mechanisms for Efficient Retrieval
Let’s break this down. Traditional retrieval systems often process text and visuals separately, which can be slow and clunky.
Late interaction mechanisms flip the script by delaying the fusion of text and image embeddings until query time.
This matters because it allows for offline precomputation of embeddings, which saves time and computational resources during retrieval.
Take ColPali, for example. This system uses a late interaction approach to compare precomputed text and image embeddings only when a query is made.
The result? Faster retrieval with better accuracy. In a case study involving pharmaceutical reports, ColPali reduced query latency by 25% while maintaining high precision in retrieving annotated diagrams and dense tables. That’s a big deal for industries like healthcare, where every second counts.
Here’s the technical nuance: Late interaction mechanisms rely on contextualized grid embeddings, which map relationships between text and visuals without prematurely merging them. This avoids the noise in early fusion models, especially with complex layouts.
Now, imagine applying this to legal contracts. Instead of sifting through fragmented clauses, a system could instantly retrieve the exact section with visual annotations.
The takeaway? Late interaction mechanisms speed things up and make retrieval smarter and more precise.
Integration of Visual Parsing into RAG Workflows
Let’s face it—PDFs are messy.
Parsing them for RAG workflows is like trying to untangle a ball of yarn with one hand tied behind your back.
Tables break, images vanish, and context? Completely lost. That’s where visual parsing steps in, turning chaos into clarity.
Here’s the magic: vision models don’t just read—they see. Imagine a pharmaceutical report packed with dense tables and annotated diagrams.
Instead of spitting out fragmented text, a vision model preserves the structure, aligning rows, keeping annotations intact, and maintaining context.

Enhancing RAG Systems with Visual Parsing
Vision models don’t just extract text—they preserve the relationships between elements, like how a table’s rows align or where annotations sit relative to the main content.
Take Pfizer’s clinical trial reports. By integrating visual parsing into their RAG workflows, they reduced data extraction errors by 30% and shaved weeks off regulatory submission timelines.
The secret? Vision models that combine text and image embeddings, ensuring no detail—like footnotes or column headers—gets lost in translation.
Here’s a thought experiment: imagine parsing a financial report with multi-year data tables.
A vision model doesn’t just grab the numbers; it understands the layout, keeping every figure in its rightful place. This level of precision isn’t just about accuracy—it’s about trust.
Looking ahead, industries like healthcare and finance can leverage this technology to turn messy, unstructured PDFs into actionable insights—faster, smarter, and with fewer errors.
FAQ
What are the advantages of using vision models for PDF parsing in Retrieval-Augmented Generation (RAG) systems?
Vision models process PDFs by analyzing both text and layout, preserving tables, annotations, and images. This ensures structured, accurate data retrieval, reducing errors in complex documents. Industries like healthcare and finance benefit from improved data extraction, regulatory compliance, and efficient document processing in RAG workflows.
How do vision models retain table structures and annotations in PDF parsing?
Vision models use multimodal embeddings to process text and visuals, maintaining table alignment, column integrity, and annotation placement. Unlike traditional methods, they analyze PDFs as complete layouts, reducing misalignment errors and ensuring structured data retrieval in industries where accuracy is critical, such as legal and medical fields.
What role do multimodal embeddings play in PDF parsing for RAG workflows?
Multimodal embeddings combine text and visual data, preserving document structure and improving retrieval accuracy. They ensure context is maintained by aligning tables, diagrams, and annotations. This approach reduces errors in document-heavy industries, enabling RAG systems to extract relevant, structured information for analysis and decision-making.
How do healthcare and finance industries benefit from document processing vision models?
Healthcare and finance require precise data extraction from unstructured PDFs. Vision models retain table integrity, annotations, and layout structure, reducing errors in financial reports and medical records. These models streamline regulatory processes, enhance compliance, and enable efficient retrieval in RAG-driven workflows by improving data accuracy.
What challenges arise when implementing vision-enhanced RAG systems for large-scale PDF parsing?
The key challenges are handling diverse layouts, ensuring computational efficiency, and processing large volumes. Best practices include multimodal embeddings for structured parsing, scalable vector databases for storage, and modular pipelines for parallel processing. These approaches enhance accuracy and retrieval efficiency for industries reliant on document integrity, such as legal and financial sectors.
Conclusion
Parsing complex PDFs is a persistent challenge for Retrieval-Augmented Generation (RAG) systems.
Vision models improve this process by preserving layout structure, extracting precise data, and ensuring accuracy across diverse documents.
Better data organization, enhanced retrieval precision, and reduced errors in document processing benefit industries like healthcare, finance, and legal.
As multimodal embeddings and late interaction mechanisms evolve, vision models will continue to refine RAG workflows, turning unstructured PDFs into structured, actionable data.