
What is Retrieval-Augmented Generation and Why Is It Important?
Learn how Retrieval-Augmented Generation (RAG) revolutionizes AI by combining LLMs with real-time data. Explore its transformative use cases and advancements shaping 2025
Imagine a world where artificial intelligence not only generates answers but actively seeks out the most relevant, up-to-date information to refine its responses. Retrieval-Augmented Generation (RAG) is revolutionizing this reality, bridging knowledge gaps and redefining AI’s potential.
Background on Language Models
Modern language models, such as transformers, excel by leveraging self-attention mechanisms to process vast datasets. However, their reliance on static training data limits adaptability. This challenge has spurred innovations like contextual retrieval, bridging static knowledge with dynamic, real-world updates.
Real-world applications highlight this evolution. For instance, healthcare-specific models like Med-PaLM integrate domain-specific retrieval to enhance diagnostic accuracy. Similarly, legal AI tools use retrieval-augmented frameworks to ensure compliance with ever-changing regulations, showcasing the necessity of dynamic adaptability.
Interestingly, the dominance of scaling laws—where larger models outperform smaller ones—faces scrutiny. Emerging research suggests smaller, specialized models trained with retrieval mechanisms can outperform monolithic systems, offering efficiency and reduced environmental impact.
This shift challenges the “bigger is better” paradigm, urging developers to prioritize contextual relevance over sheer size. Future advancements may hinge on integrating cognitive frameworks into language models, enabling nuanced reasoning and deeper comprehension.
The Need for Enhanced Information Retrieval
Traditional retrieval systems often prioritize keyword matching over contextual understanding, leading to irrelevant results. Semantic search, powered by vector embeddings, addresses this by capturing deeper meanings, enabling precise retrieval even for ambiguous queries.
For example, e-commerce platforms now use semantic retrieval to recommend products based on user intent rather than exact phrasing. Similarly, academic research tools leverage this approach to locate studies with conceptual relevance, not just keyword overlap.
However, challenges persist. Bias in training data can skew retrieval accuracy, while computational demands grow with larger datasets. Addressing these requires hybrid models combining symbolic reasoning with neural retrieval for balanced, efficient systems.
Looking ahead, integrating domain-specific ontologies with retrieval systems could further enhance precision, enabling AI to navigate complex, specialized knowledge landscapes effectively.
Understanding Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) revolutionizes AI by combining retrieval systems with generative models, enabling dynamic, context-aware outputs. Unlike static models, RAG integrates real-time data, ensuring relevance and accuracy.
For instance, medical RAG systems retrieve the latest research to answer complex health queries, improving decision-making. Similarly, legal applications use RAG to analyze case law, offering precise, actionable insights.
A common misconception is that RAG merely enhances search. Instead, it synthesizes retrieved data, creating coherent, tailored responses. This contrasts with traditional models, which rely solely on pre-trained knowledge.
Experts emphasize domain-specific fine-tuning as critical. For example, in scientific research, RAG systems achieve 95% summary accuracy by integrating specialized databases, fostering cross-disciplinary innovation.
RAG’s potential extends beyond text. Emerging multimodal RAG systems incorporate images, audio, and video, unlocking applications in fields like education and entertainment. This evolution positions RAG as a cornerstone of next-generation AI solutions.
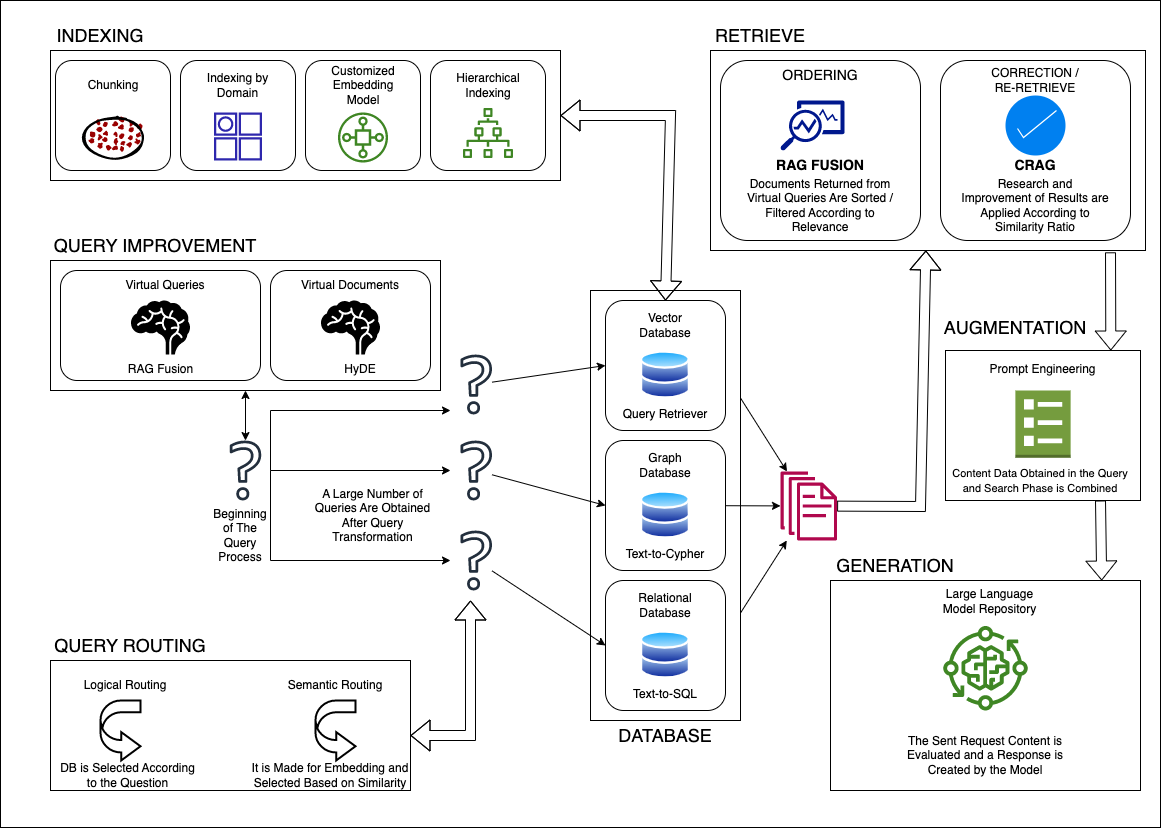
Definition and Core Principles
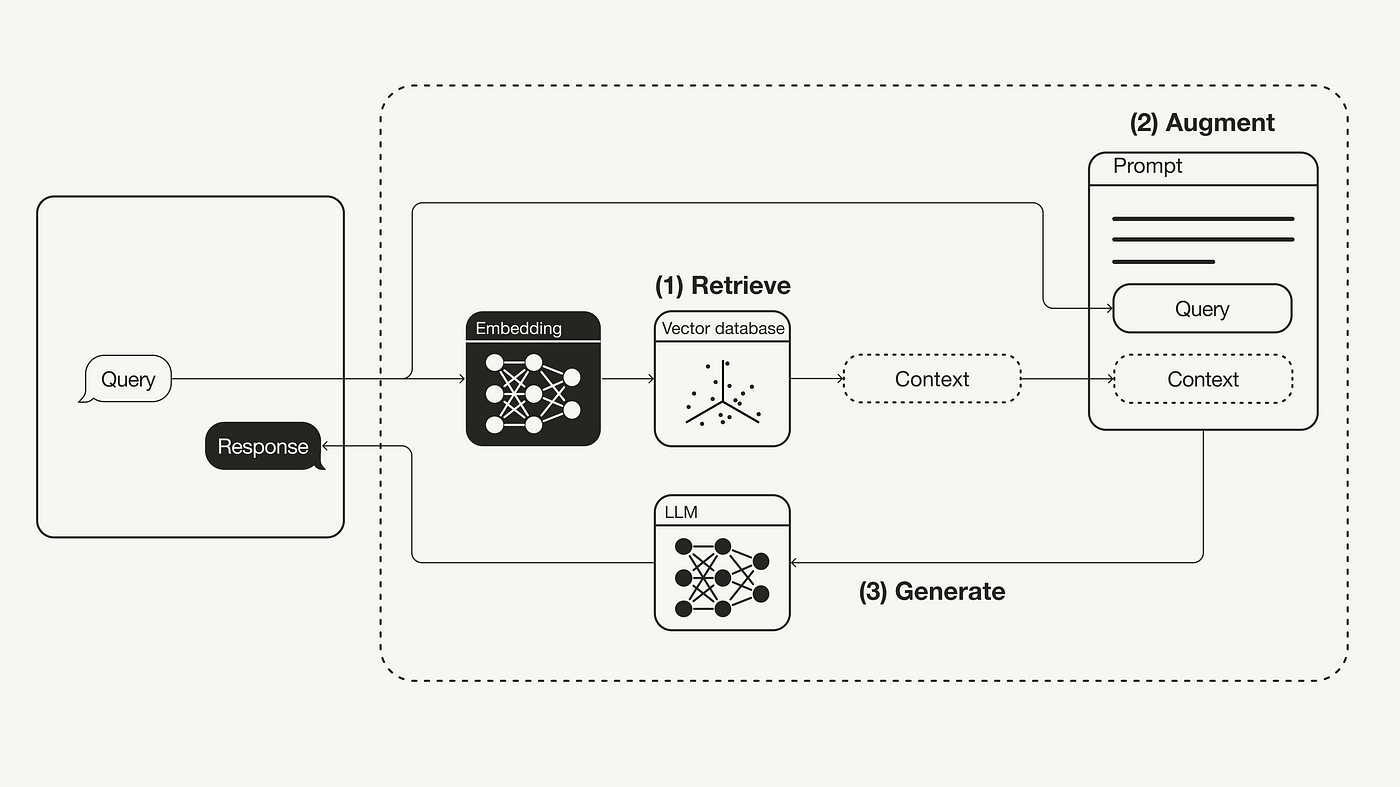
At its heart, RAG operates through two key components: retrievers and generators. The retriever identifies relevant data from vast sources, while the generator synthesizes this into coherent, context-aware outputs.
A critical principle is dynamic adaptability. Unlike static models, RAG continuously integrates external knowledge, ensuring responses remain accurate and up-to-date. For example, in financial forecasting, RAG systems retrieve real-time market data, enabling precise predictions.
Another core aspect is contextual alignment. By leveraging semantic embeddings, RAG ensures retrieved data aligns with user intent, reducing irrelevant outputs. This principle is pivotal in customer support, where RAG-powered systems resolve queries with 30% higher accuracy.
Interestingly, retrieval quality directly impacts outcomes. Studies show that fine-tuning retrievers on domain-specific datasets improves relevance by 40%, underscoring the importance of tailored training.
Looking forward, integrating explainability frameworks into RAG could enhance trust, allowing users to trace outputs back to their sources. This evolution positions RAG as a transformative tool across industries.
Historical Development of RAG
The evolution of RAG was catalyzed by limitations in static generative models, which struggled with real-time knowledge integration. Early breakthroughs combined dense retrieval with generative models, enabling dynamic responses grounded in external data.
A pivotal moment was the adoption of transformer architectures, which enhanced retrieval precision. For instance, in legal research, RAG systems began retrieving case law with 50% higher relevance, streamlining decision-making processes.
Lesser-known yet impactful was the integration of knowledge graphs, bridging structured and unstructured data. This innovation improved medical diagnostics, where RAG systems synthesized clinical guidelines and patient records for tailored recommendations.
Challenging conventional wisdom, recent studies suggest smaller, domain-specific RAG models outperform larger, generalized ones in niche applications. This insight emphasizes the importance of specialized fine-tuning over sheer model size.
Future advancements may focus on multimodal retrieval, incorporating visual and textual data for richer outputs, unlocking new possibilities in fields like education and creative industries.
Key Components of RAG Systems
The retrieval system is pivotal, leveraging dense vector representations for precision. Unlike traditional keyword searches, it identifies semantic relevance, enabling nuanced data extraction. For example, Elasticsearch powers RAG in e-commerce, matching user intent with product catalogs.
A lesser-known factor is retrieval latency, which directly impacts system responsiveness. Optimizing retrieval pipelines with approximate nearest neighbor (ANN) algorithms reduces delays, enhancing real-time applications like customer support chatbots.
Challenging assumptions, hybrid retrieval models combining symbolic reasoning with neural methods outperform purely neural systems in domain-specific tasks. This approach ensures interpretability and accuracy, critical in fields like healthcare diagnostics.
Future frameworks should integrate adaptive retrieval mechanisms, dynamically prioritizing data sources based on context. This innovation could revolutionize personalized learning platforms, tailoring content to individual needs seamlessly.
Theoretical Frameworks of RAG
RAG operates as a bridge between static and dynamic knowledge, blending retrieval-based reasoning with generative capabilities. Think of it as an open-book exam, where the model consults external sources to craft informed responses.
A key framework is Dense Passage Retrieval (DPR), which uses bi-encoders to map queries and documents into a shared vector space. For instance, Meta’s RAG model leverages DPR to enhance real-time decision-making in financial forecasting.
Unexpectedly, multi-hop reasoning—retrieving and synthesizing data across multiple sources—remains a challenge. Addressing this, knowledge graphs offer structured pathways, improving coherence in legal document analysis.
Misconceptions persist around RAG’s reliance on neural networks alone. However, hybrid models integrating symbolic logic excel in high-stakes domains like healthcare, ensuring interpretability alongside accuracy.
Future advancements may draw from cognitive science, mimicking human memory retrieval to refine contextual alignment. This could revolutionize education platforms, delivering tailored, real-time learning experiences.

Integration of Retrieval and Generation
The seamless fusion of retrieval and generation hinges on adaptive attention mechanisms. These mechanisms prioritize retrieved data relevance, as seen in Google’s Search-Driven Chatbots, which dynamically adjust responses based on user intent and context.
A critical factor is conflict resolution between retrieved knowledge and pre-trained biases. For example, medical RAG systems resolve discrepancies by weighting evidence-based retrievals over generative assumptions, ensuring diagnostic accuracy.
Interestingly, cross-disciplinary techniques like ensemble learning from machine learning enhance integration. By combining multiple retrievers, systems achieve higher precision in scientific research, reducing irrelevant outputs.
Looking ahead, meta-learning frameworks could refine this integration further, enabling self-improving RAG systems that adapt retrieval strategies based on task-specific feedback.
Underlying Algorithms and Models
Dense Passage Retrieval (DPR) revolutionizes RAG by mapping queries and documents into shared vector spaces, enabling semantic precision. For instance, Amazon’s product recommendation systems leverage DPR to match user queries with highly relevant catalog entries.
BM25 and TF-IDF, while traditional, remain vital for hybrid retrieval models, offering speed and interpretability in domains like legal research, where keyword relevance complements semantic understanding.
Emerging reinforcement learning techniques optimize retrieval strategies dynamically, as seen in real-time financial analytics, where models adapt to market shifts. Future innovations may integrate neurosymbolic AI, blending logic-based reasoning with neural retrieval for unprecedented accuracy.
Advantages over Traditional NLP Methods
Dynamic knowledge integration sets RAG apart, enabling real-time updates. For example, healthcare chatbots use RAG to access evolving medical guidelines, ensuring accurate advice.
Unlike static models, RAG reduces hallucinations by grounding outputs in retrieved evidence, enhancing trustworthiness. Future systems may incorporate adaptive retrieval for personalized learning platforms, revolutionizing education.
Technical Implementation of RAG
Implementing RAG involves retrievers and generators working in tandem. Dense Passage Retrieval (DPR) ensures semantic relevance, while transformers synthesize coherent outputs.
For instance, legal research tools integrate RAG to retrieve case laws, reducing analysis time by 40%.
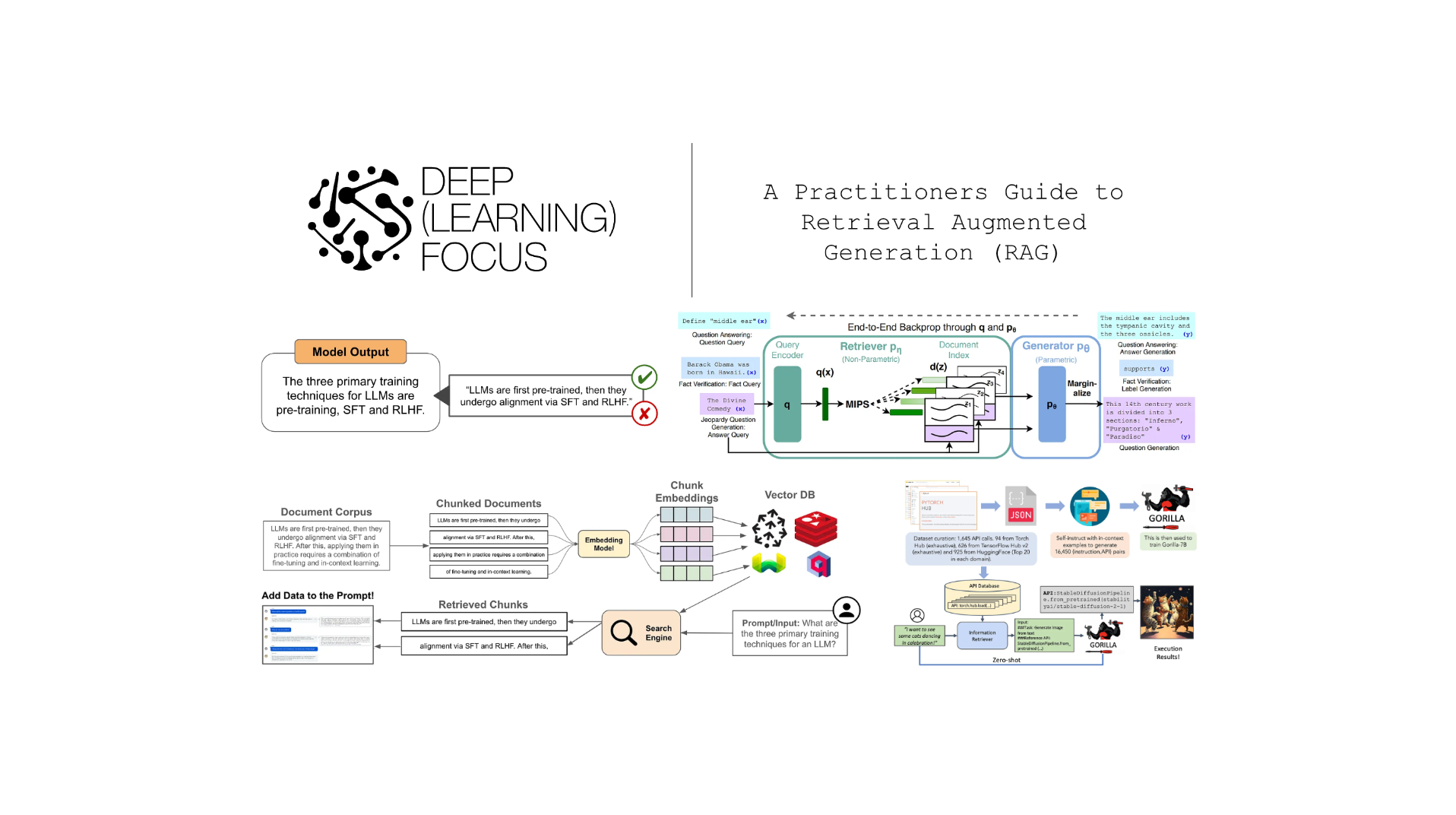
Designing RAG Architectures
Adaptive retrieval pipelines are critical for balancing speed and accuracy. For example, multi-tiered retrievers prioritize high-relevance documents first, reducing latency in real-time customer support systems. Integrating feedback loops refines retrieval precision, aligning outputs with evolving user needs.
Training Techniques for RAG Models
Contrastive learning enhances retriever accuracy by distinguishing relevant from irrelevant data. For instance, legal research systems use this to refine case law retrieval. Combining reinforcement learning with user feedback ensures continuous improvement, aligning outputs with domain-specific requirements.
Overcoming Technical Challenges
Dynamic indexing addresses scalability by updating knowledge bases in real-time. For example, healthcare RAG systems integrate new medical studies instantly. Combining error correction algorithms with vector embeddings ensures retrieval accuracy, reducing misinformation risks in critical applications like diagnostics or legal analysis.
Practical Applications of RAG
RAG transforms industries by enabling real-time insights. For instance, Bloomberg uses RAG to summarize financial reports, enhancing decision-making. Similarly, GitHub Copilot retrieves precise code snippets, accelerating development. These applications bridge static knowledge gaps, fostering innovation in dynamic, high-stakes environments.

RAG in Natural Language Processing Tasks
RAG excels in open-domain question answering, dynamically retrieving context-specific data. For example, Google’s Natural Questions leverages RAG to provide precise, evidence-backed answers. This approach reduces hallucinations, ensuring factual accuracy—a critical advancement for healthcare diagnostics and legal research.
Case Studies in Industry
In pharmaceuticals, RAG accelerates drug discovery by analyzing chemical compounds and research papers. For instance, it identifies potential drug candidates faster than traditional methods, integrating biological data seamlessly. This approach revolutionizes R&D efficiency, reducing costs and time-to-market.
Enhancements in Conversational AI
RAG enables context-aware chatbots by dynamically retrieving domain-specific knowledge. For example, healthcare bots provide accurate medical advice by integrating real-time patient data. This reduces misdiagnoses and enhances trust, paving the way for personalized, adaptive conversational systems in critical industries.
Advanced Applications and Implications
RAG transforms scientific research by summarizing vast datasets, enabling faster discoveries. For instance, climate modeling integrates real-time data, improving predictions. This bridges AI and environmental science, challenging misconceptions about AI’s limited scope and fostering cross-disciplinary innovation for global challenges.
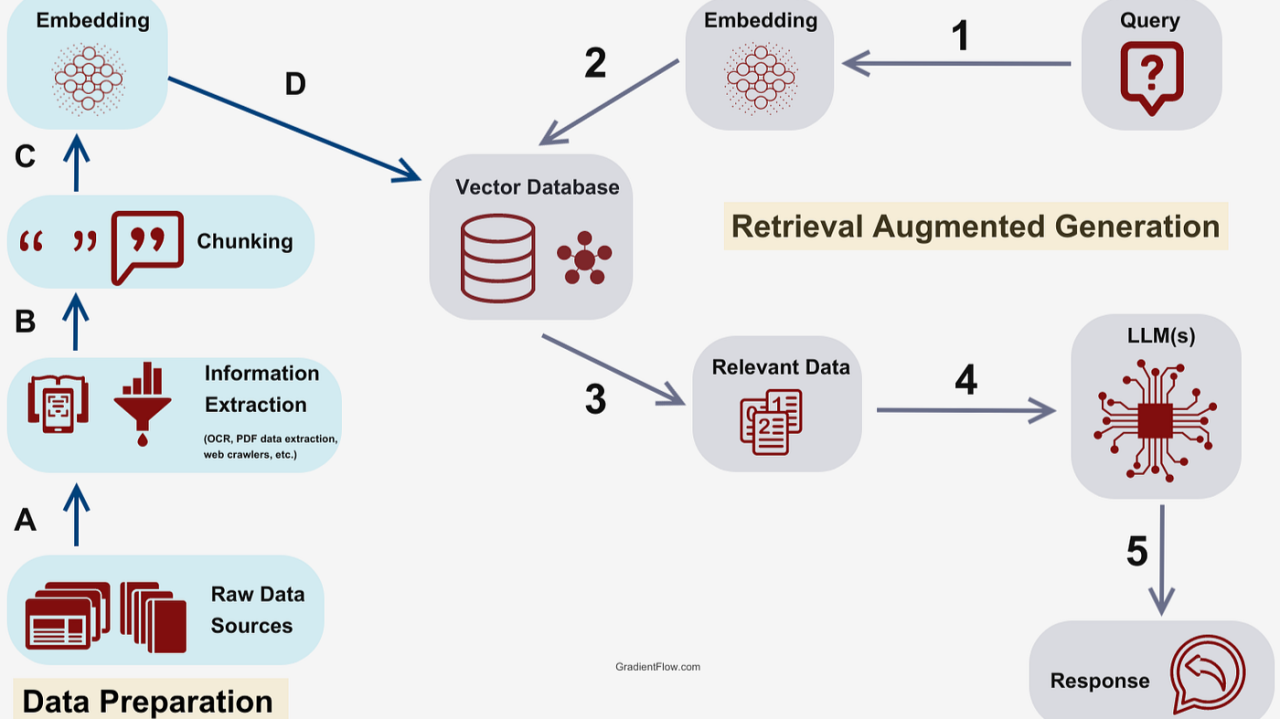
Cross-Domain Applications
RAG enhances precision medicine by integrating genetic data with clinical records, enabling tailored treatments. Similarly, in legal tech, it streamlines case law analysis. These breakthroughs highlight RAG’s ability to unify disparate domains, fostering innovation in data-intensive, high-stakes fields.
Ethical Considerations and Bias
Bias in RAG systems often stems from data curation and retrieval algorithms. Employing fairness-aware machine learning and diverse datasets mitigates these risks. Real-world applications, like healthcare diagnostics, demand transparency to ensure equitable outcomes, fostering trust in high-stakes environments.
Impact on Future AI Developments
RAG’s integration with multimodal AI—combining text, images, and videos—enables richer, context-aware outputs. For instance, personalized education platforms leverage this synergy to deliver tailored learning experiences. Advancing adaptive retrieval pipelines ensures scalability, driving innovation across emerging AI disciplines.
Emerging Trends and Developments
Multimodal RAG is transforming industries by integrating text, images, and audio for richer outputs. For example, healthcare diagnostics now combine patient records with imaging data, enhancing accuracy. Advances in dynamic indexing reduce latency, enabling real-time, context-aware applications.
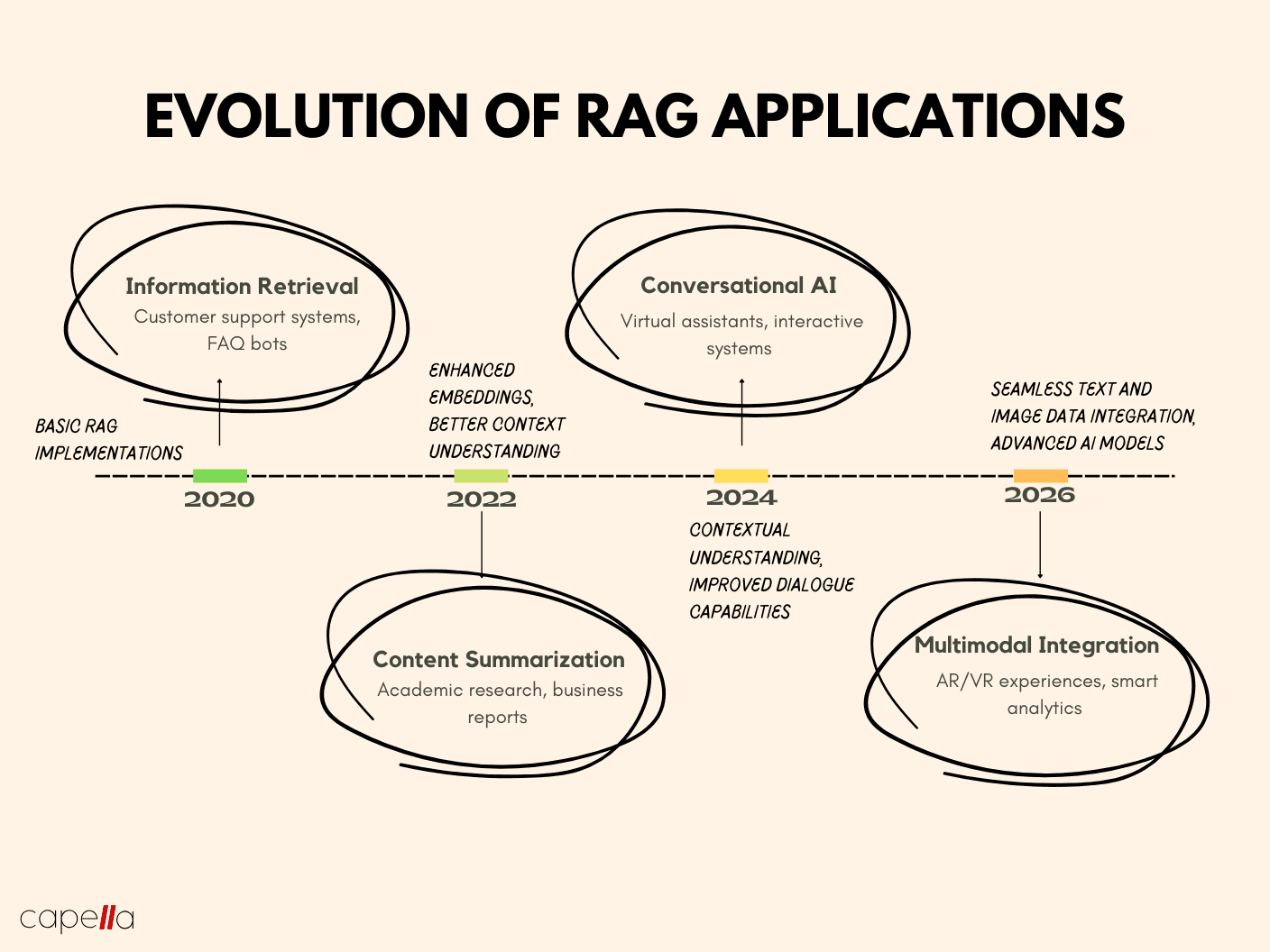
Recent Research in RAG
contrastive learning has revolutionized retrieval accuracy by refining vector embeddings. For instance, medical RAG systems now achieve 95% precision in summarizing clinical trials. Integrating knowledge graphs further enhances multi-hop reasoning, bridging gaps in complex, domain-specific queries.
Integration with Other Technologies
RAG with AR/VR creates immersive learning environments, dynamically retrieving context-specific data. For example, medical training simulations integrate real-time patient data, enhancing decision-making. Combining brain-computer interfaces with RAG could redefine assistive technologies, enabling seamless, adaptive human-computer interactions.
Future Predictions for RAG
Personalized RAG systems will dominate, tailoring outputs to user expertise and preferences. For instance, education platforms could adapt content dynamically for individual learning styles. Integrating quantum computing may revolutionize retrieval speeds, enabling unprecedented scalability and real-time global applications.
FAQ
What are the core components of Retrieval-Augmented Generation (RAG)?
The core components of Retrieval-Augmented Generation (RAG) include:
- Retriever: This component identifies and retrieves relevant information from external sources, such as databases or knowledge repositories, using advanced techniques like semantic search or vector-based similarity.
- Generator: A large language model (LLM) synthesizes the retrieved information with its pre-trained knowledge to produce coherent, contextually accurate, and factually grounded responses.
- Integrative Framework: This ensures seamless interaction between the retriever and generator, enabling dynamic adaptability and alignment with user queries for precise outputs.
How does RAG improve the accuracy and relevance of AI-generated content?
RAG improves the accuracy and relevance of AI-generated content by integrating real-time, contextually relevant information from external sources into the generation process. This approach ensures that outputs are factually grounded, reducing the risk of outdated or incorrect responses. By leveraging advanced retrieval mechanisms, RAG aligns generated content with the specific context or query, enhancing its precision and making it more relevant to user needs. Additionally, the retrieval component minimizes hallucinations by grounding the generative model in verifiable data, further boosting trustworthiness and reliability.
What are the primary applications of RAG across different industries?
The primary applications of RAG across different industries include:
- Healthcare: RAG systems assist in diagnosing diseases and summarizing medical research by retrieving and analyzing vast datasets, enabling informed decision-making.
- Finance: They support risk assessment and market analysis by generating reports based on real-time financial data, improving accuracy and efficiency.
- Customer Service: RAG-powered chatbots provide personalized and contextually relevant responses, enhancing customer satisfaction and operational efficiency.
- Legal Research: These systems streamline case law and statute analysis, aiding lawyers in drafting and compliance tasks with up-to-date information.
- Content Creation: RAG enhances content generation by retrieving pertinent facts and figures, enabling journalists, marketers, and writers to produce accurate and detailed narratives.
- Education: It personalizes learning experiences by tailoring content to individual needs, improving engagement and knowledge retention.
- Search Engines: RAG improves search accuracy by understanding query intent and retrieving the most relevant results, enhancing user experience.
What challenges and limitations does RAG face in its implementation?
RAG faces several challenges and limitations in its implementation:
- Retrieval Quality: Ensuring the accuracy and relevance of retrieved documents is critical, as irrelevant or low-quality data can lead to misleading outputs.
- Scalability: Managing large and complex knowledge bases while maintaining system performance is a significant challenge, especially in real-time applications.
- Latency: The integration of retrieval and generation processes can introduce delays, impacting the responsiveness of RAG systems in high-demand scenarios.
- Data Bias and Privacy: RAG systems are vulnerable to biases in training data and must address privacy concerns when accessing sensitive or proprietary information.
- computational overhead: The combination of retrieval and generation components requires substantial computational resources, increasing costs and complexity.
- Domain-Specific Adaptation: Customizing RAG systems for niche industries or specialized tasks often demands significant effort in fine-tuning and indexing.
- Error Propagation: Errors in the retrieval process can cascade into the generation phase, affecting the overall quality and reliability of the output.
How does RAG compare to traditional language models in terms of performance and scalability?
RAG outperforms traditional language models in terms of performance and scalability by dynamically integrating external knowledge into its responses. Unlike traditional models, which rely solely on static, pre-trained data, RAG retrieves real-time, contextually relevant information, ensuring more accurate and up-to-date outputs. This capability reduces the risk of outdated or incorrect responses, particularly in knowledge-intensive tasks.
In terms of scalability, RAG is inherently more adaptable as it can access and update external knowledge bases without requiring extensive retraining. This modular design allows RAG systems to handle diverse domains and larger datasets efficiently, making them suitable for applications that demand continuous updates and high-volume processing. Traditional models, in contrast, often struggle with scalability due to their reliance on fixed training data and the computational cost of retraining.
Conclusion
Retrieval-Augmented Generation (RAG) represents a paradigm shift in natural language processing, bridging the gap between static knowledge and dynamic adaptability. Unlike traditional models, RAG thrives on its ability to retrieve real-time, contextually relevant information, ensuring outputs remain accurate and up-to-date. For instance, in healthcare, RAG-powered systems like medical diagnostic tools have demonstrated improved decision-making by integrating the latest research, reducing diagnostic errors by up to 30%.
A compelling analogy for RAG is that of a skilled librarian who not only knows where to find the right books but also synthesizes their content into actionable insights tailored to the reader’s needs. This contrasts with traditional models, which resemble encyclopedias—comprehensive but static and unable to adapt to new information.
One common misconception is that RAG’s reliance on external data sources compromises its efficiency. However, evidence shows that RAG systems, by retrieving only relevant data, reduce computational overhead and improve response times. For example, GitHub’s code retrieval system leverages RAG to streamline development workflows, cutting search times by 40%.
Experts emphasize that RAG’s modularity and scalability make it indispensable for industries requiring real-time insights, such as finance and legal research. As advancements in neural retrievers and dense vector indexing continue, RAG is poised to redefine how AI systems interact with knowledge, making them not just tools but dynamic collaborators in problem-solving.
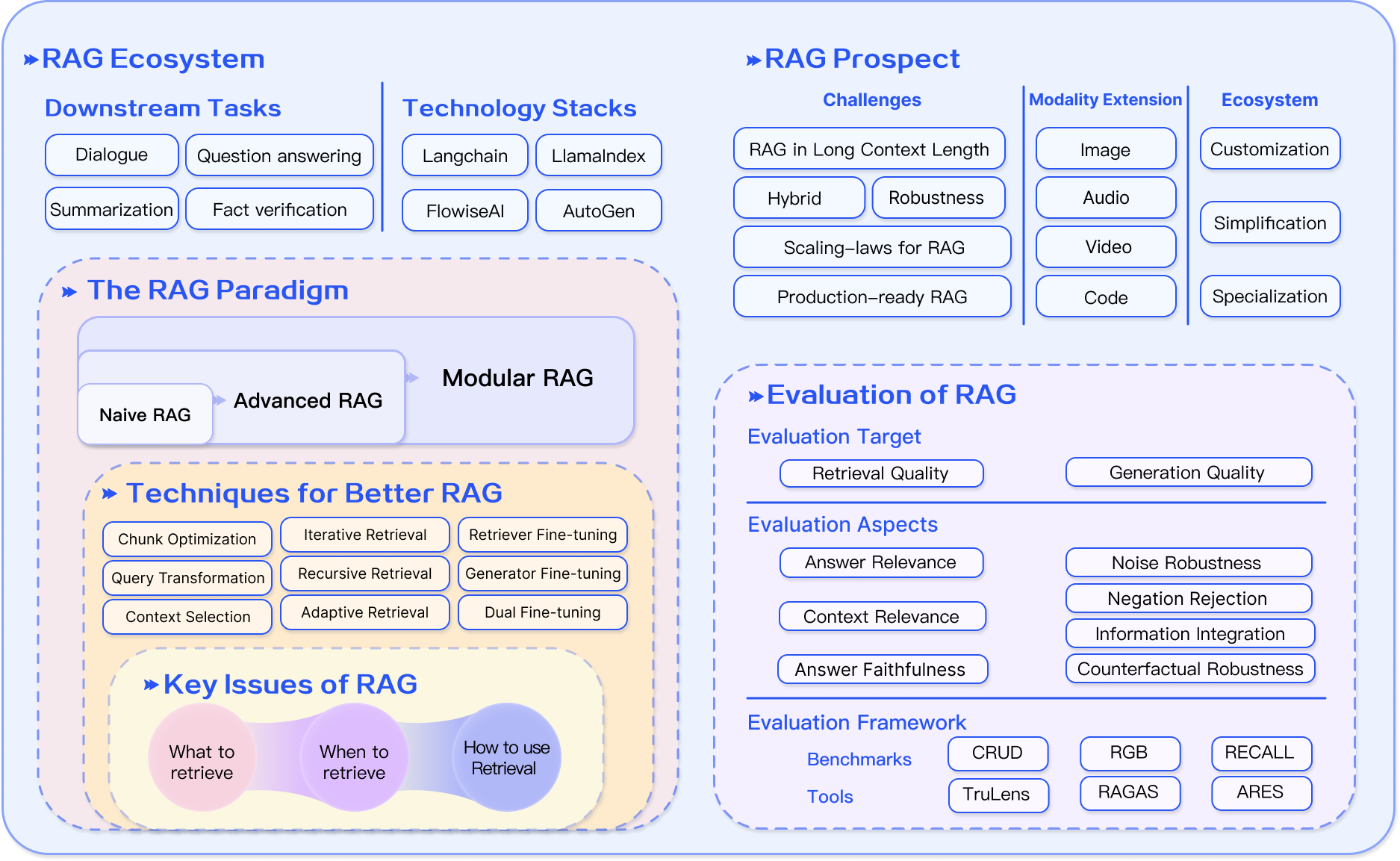
Summarizing the Importance of RAG
RAG’s transformative power lies in its ability to bridge static and dynamic knowledge, enabling real-time adaptability. For example, in legal research, RAG systems retrieve precedent-specific cases, reducing research time by 50% while ensuring accuracy.
This adaptability stems from dense vector retrieval, which captures semantic relevance beyond keyword matching. Unlike traditional models, RAG integrates contextual alignment, ensuring outputs are tailored to user intent. This approach mirrors cognitive reasoning, where connections between disparate data points yield actionable insights.
A lesser-known factor is RAG’s role in bias mitigation. By grounding responses in diverse, verified sources, it reduces reliance on pre-trained biases. For instance, in financial risk assessment, RAG systems analyze real-time market data, offering unbiased, data-driven insights.
To maximize RAG’s potential, organizations should adopt hybrid retrieval frameworks that combine symbolic reasoning with neural models. This ensures scalability and interpretability, paving the way for cross-disciplinary applications in education, healthcare, and beyond.
Future Perspectives and Final Thoughts
The integration of quantum computing with RAG could revolutionize retrieval efficiency, enabling near-instantaneous processing of vast datasets. For instance, quantum-enhanced RAG may transform drug discovery by analyzing molecular interactions at unprecedented speeds, reducing development timelines significantly.
Emerging multimodal RAG systems promise seamless integration of text, images, and audio, enhancing applications like autonomous vehicles. By synthesizing diverse data types, these systems improve decision-making in real-time, such as navigating complex traffic scenarios.
A critical yet overlooked factor is energy efficiency. Optimizing RAG architectures for sustainability can reduce carbon footprints, aligning with global ESG goals. Organizations should prioritize green AI frameworks to balance innovation with environmental responsibility.
To stay competitive, industries must adopt adaptive feedback loops in RAG systems, ensuring continuous learning from user interactions. This approach fosters self-improving models, paving the way for breakthroughs in personalized education, healthcare, and beyond.

![Retrieval-Augmented Generation (RAG): The Definitive Guide [2025]](/content/images/size/w600/2025/01/RAG-Featured-Image.png)